はじめに
CVPR2018 workshop 「Visual Understanding of Humans in Crowd Scene and Look Into Person Challenge」から以下の論文
[1] M. Fieraru, et. al. "Learning to Refine Human Pose Estimation"
のまとめ
arXiv:
https://arxiv.org/abs/1804.07909
アーキテクチャのみを簡潔にまとめる
概要
- pose estimation を refine するためのしくみで、様々なモデルの後処理に使える
- 別モデルで推定した pose を本モデルに入力し、refine した関節位置を出力する
アーキテクチャの全体像
以下の図が全体像
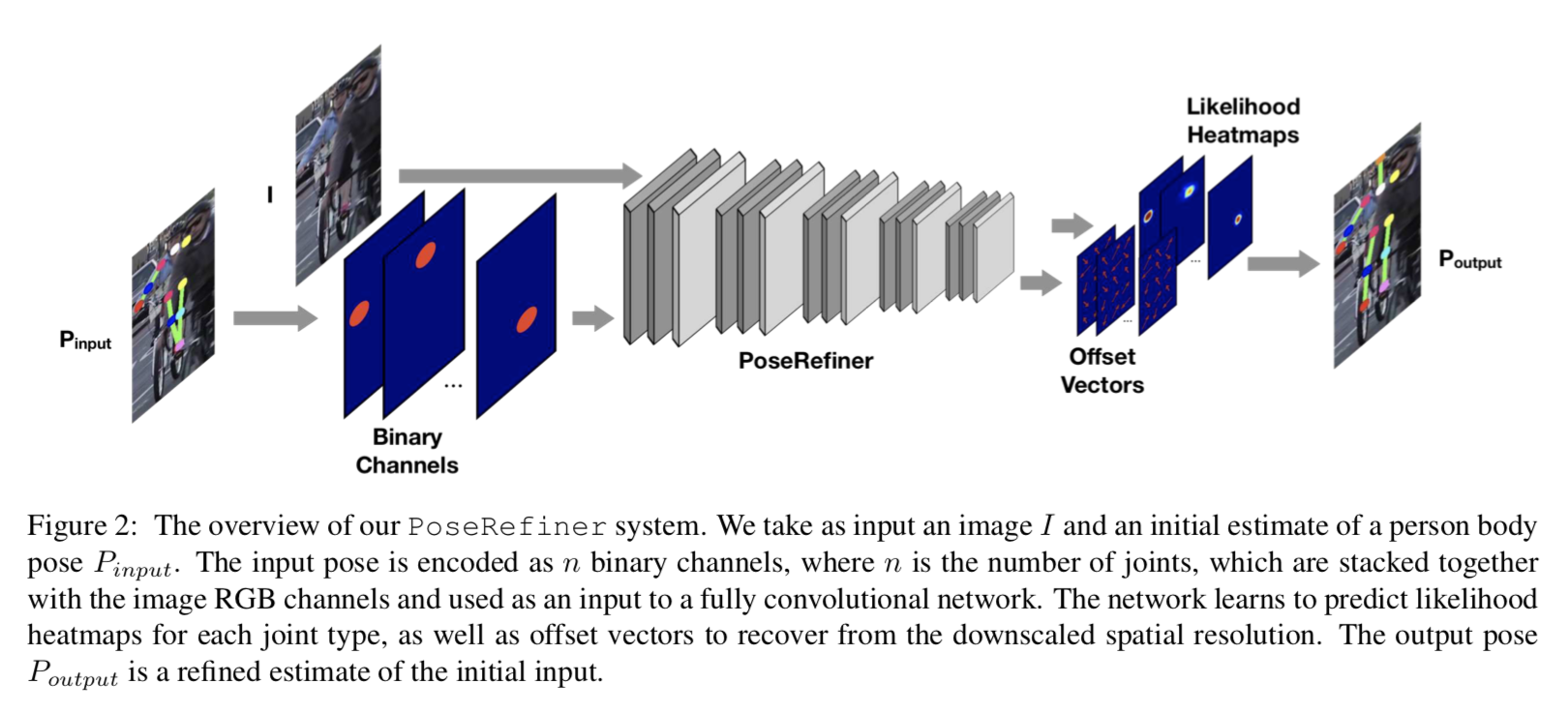
(1)左から元画像、及び別モデルで推定した関節位置をheatmapに変換したものを concatenate して本モデルに入力する
(2)出力は、関節位置のheatmapと、その位置に対するoffset vector。
感想
他の pose estimation モデルの後にくっつけるだけでよいので、てっとり早く精度を上げるのに適してそう
以上。