はじめに
CVPR2020より以下の論文
[1] Y. Zhou, et. al. "Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data".CVPR2020
のまとめ
github:
https://github.com/CalciferZh/minimal-hand
MIT license, Tensorflow 1系
概要
- 3D hand pose estimation のモデル
- 2D や 3D の pose ラベル付き画像、3Dのアニメーションを使って学習させる
- accuracyにおいてSOTAを達成しつつ、100fpsという高い推論速度を達成
背景
著者らは、現状の 3D hand pose estimationにおいて以下2つの問題点があると考えている
問題点1:training dataを利用する際の問題
- 3D でラベリングされたデータはあるが、depthカメラやstereoカメラ等特殊な設備が必要なので数が限られている
- 3D のラベル付き合成データもあるが、realな画像とdomain gapがある
- 2D ラベル付きデータはrealだが、3Dのラベルを付与することは困難
問題点2:推論した値をapplicationで利用する際の問題点
- ほとんどのモデルは各関節の3D位置しか推定しないが、これだけではapplicationで利用するのには不足する。角度もほしい
- 各関節の角度を推定するモデルもあるが、anatomicな正しさが保証されてない
モデル
モデルの全体像
以下の図はモデルの全体像
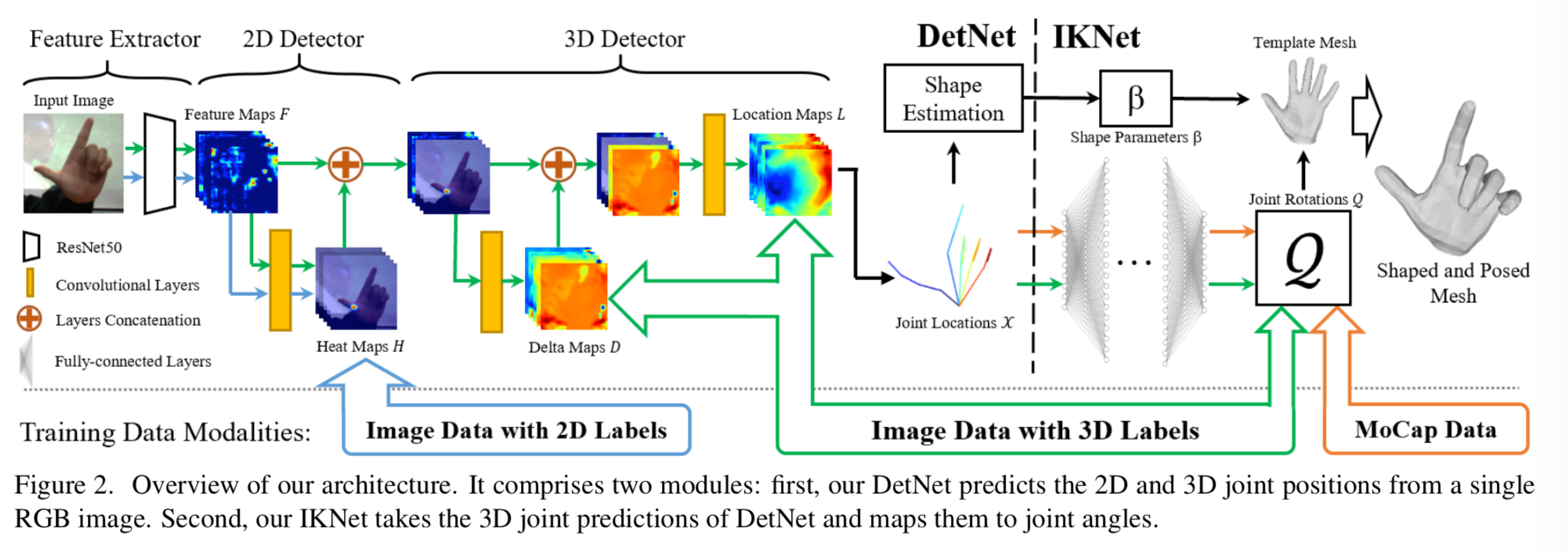
図の左から見ていく。
1)まず最左からRGB単眼画像1枚を入力し、ResNet50でfeature map F を得る。(Feature Extractor)
2)それに対してその下、さらに畳み込んで2Dの heatmpap H を推定する。このheatmap H は2Dのアノテーションで学習させる(2D Detector)
3)heatmap H と feature map F とを足し(concat?)てrefine(?)し、これをその下、畳み込んでDelta Map Dを得る。Delta map Hは3Dのアノテーションで学習させる。その後 Delta map Dをさらに畳み込み、3D の Location Map Lを得る。この段階においても3Dアノテーションで学習させる(3D Detector)
4)Location Map Lからshape パラメータ $\beta$ を推定させ、各関節の角度 Q を得る。QはMoCAP dataで学習させる
5)パラメータと角度から3D meshを得る
全体的には、3D 位置を推定するまでがDetNet、その後shapeを推定するのがIKNet。
Feature Extractor
- 先に述べたようにResNet50をbackboneとしている
- 入力は128x128の画像
- 出力は32x32x256のFeature map F
2D Detector
- 2層のconv
- Feature map Fを入力とし、21チャンネル(root + 各指のjoint)のheatmapを出力する
- これを入れたことで精度が劇的に上がったらしい
3D Detector
- 最終的に推定させるのは Location Map L で、これは2d・・つまりxとyはmapの位置、zはその値としてもの。
- 一方でその途中でDelta Map Dを推定させる。これは親関節から子関節への3Dのベクトル場。これにより各関節と関節の関連付けが明確になる。
- 2d heatmap H と feature map F から Delta Map Dを推定するのは2層のconv
- さらに2d heatmap H と feature map F, Delta Map Dをconcatして2層convで畳み込み、location map L を得る
DetNetのloss
loss 全体は
\mathcal{L} = \mathcal{L}_{heat} + \mathcal{L}_{loc} + \mathcal{L}_{delta} + \mathcal{L}_{reg}
最後の $\mathcal{L}_{reg}$ はL2ノルム。以下、それ以外の各項の詳細。
loss heat
2D heatmap レベルでground truthとのフロベニウス・ノルム・・・要するにL2・・・の2乗を計算する。
\mathcal{L}_{heat} = \| H^{GT} - H \|^2_F
loss location
location map L は2D heatmapのpeak点のみ意味があるので、2D heatmap のground truthをmultiplyする。
\mathcal{L}_{loc} = \| H^{GT} \odot (L^{GT} - L) \|^2_F
loss delta
deltaに関するlossも同様に2D heatmap のground truthをmultiplyする。
\mathcal{L}_{loc} = \| H^{GT} \odot (D^{GT} - D) \|^2_F
IKNet的な部分
書きかけ
実験と結果
3D hand pose 系 datasetにおける定量的評価
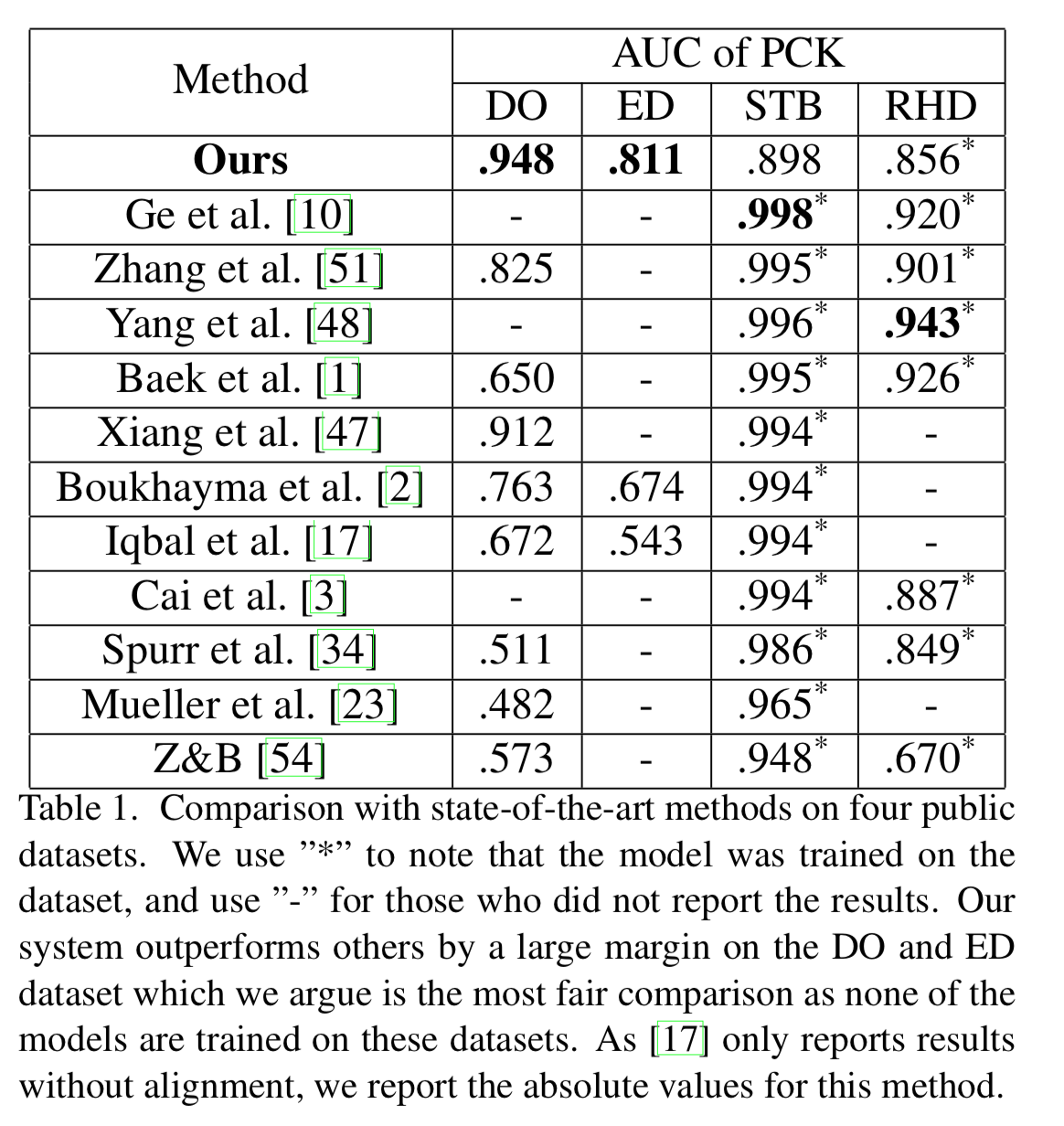
まず著者らによると、STBやRHDはsettingが異なるので同じ条件の評価では無い、とのこと。一方でDOとEDは同一条件となるので、ここで他を圧倒している点をもって、本手法の優位性を主張している。
特にSTBに関しては、他のモデルはSTBのtrain dataで学習させているが、本手法はそれで学習させて無い。このtrain dataを入れるとAUC=0.991となり、他の手法と比肩するレベルになったが、overfittingしたため他のdataasetに対する値は低下したのだそう。(全てのデータを入れるところが本手法の特徴なので、STB単独では評価できないだろう)
ablation study
書きかけ