はじめに
ICLR 2019 に accept された以下の論文
[1] K. Lee, et. al. "SPIGAN: PRIVILEGED ADVERSARIAL LEARNING FROM SIMULATION"
のまとめ。
arXivのリンク
https://arxiv.org/abs/1810.03756
現時点(2019/4/13)で本論文を実装したコードで公開されてるものは私のだけみたい。
https://github.com/masataka46/SPIGAN
概要
- simulatorで作成した画像を realな画像に変換する、domain adaptation 分野の論文
- real な画像に対するアノーテーション無しで目的タスクの推論値を求められる
- simulatorからの画像はGANでrealにするが、その際に simulator ならではの情報(例えばdepth情報)を利用するのが特徴的
以下の図が1例。
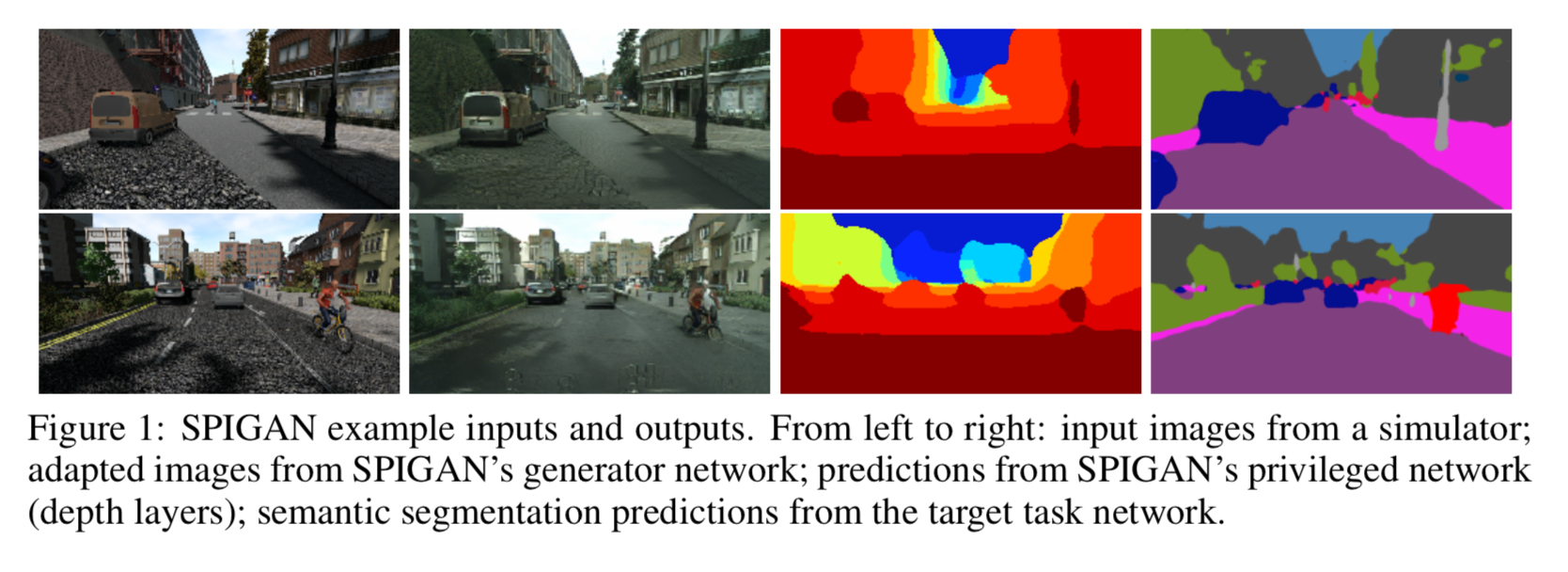
[1]のFigure 1より
左から simulator で生成した画像、それを realにしたもの、depth情報の推論値、セグメンテーションの推論値。
背景
semantic segmentation などはアノテーションの労力が多大にあり、それが学習のボトルネックになっている。アノテーション無しで学習することが出来れば楽だろう。
モデルの概要
モデルの概要は以下の図。

[1]Figure2 より
最上段部分に注目すると、左から画像 $x_s$ 入れて generator で $x_f$ に変換する。
その $x_f$ と実際の画像 $x_r$ を discriminator に入れて real か fake かを判別する。
この部分だけ見ると、ありがちな画像変関係の GAN。
これに中央左寄り、認識タスク(この場合 semantic segmentation)を推論する task predictor $T$ を加えた。これも先行研究で既にある。
本モデルの特徴は中央右寄り Previlege Infomation (この場合depth情報)を推論する Previleged Network $P$ 。
目的関数と学習方法
目的関数全体
全体は以下。
\min_{\theta_G, \theta_T, \theta_P} \max_{\theta_D} \alpha \mathcal{L}_{GAN} + \beta \mathcal{L}_T + \gamma \mathcal{L}_{P} + \delta \mathcal{L}_{perc}
1項目から adversarial loss、task prediction loss、PI regularization、perceptual regularization。
各項の $\alpha, \beta, \gamma, \delta$ は重みづけ。
adversarial loss
adversarial loss は 最小二乗損失で安定化させる。
\mathcal{L}_{GAN}(D, G) = \mathbb{E}_{x_r \sim P_r}[(D(x_r;\theta_{D}) - 1)^2] + \mathbb{E}_{x_s \sim P_s}[D(G(x_s;\theta_{G});\theta_D)^2]
$x_r$ :realな画像
$p_r$ :realな画像が従うデータ生成分布
$x_s$ :simulatorで作成した画像
$p_s$ :simulatorで作成した画像がデータ生成従う分布
$\theta_G$ :generatorのパラメータ
$\theta_D$ :discriminatorのパラメータ
task prediction loss
task predictor $T$ に 合成画像 $x_s$ と それをreal化した画像 $G(x_s, \theta_G)$ を入力し、ラベルとの loss を計算することで、両者のラベル情報を保持することを狙う。
semantic segmentation タスクの場合、ピクセルレベルでの交差エントロピーを計算する。
\begin{eqnarray}
\mathcal{L}_T (T, G) &=&\mathcal{L}_{CE} (x_s, y_s) + \mathcal{L}_{CE} (G(x_s, \theta_G), y_s)\\
\mathcal{L}_{CE}(x,y) &=& \frac{-1}{WH}\sum_{u,v}^{W,H} \sum_{c=1}^{C} \mathbb{1}_{[c=y_{u,v}] } \log(T(x;\theta_T )_{u,v})\
\end{eqnarray}
$W$ :画像の幅
$H$ :画像の高さ
$u$ :画像の横ピクセル
$v$ :画像の縦ピクセル
$C$ :物体のクラス
$\theta_T$ :task predictor のパラメータ
$mathbb{1}$ :indicator 関数
$y_s$ :セグメンテーションのラベル
PI regularization
タスク特有の情報(previlege infomation)で制約をかける。depth情報の場合は、previleged network $P$ に合成画像 $x_s$ と それをreal化した画像 $G(x_s, \theta_G)$ を入力し、depth ラベルとの loss を計算する
これにより合成画像 $x_s$ と それをreal化した画像 $G(x_s, \theta_G)$ のdepth 情報が維持されることを狙う。
推論値とラベルとの差のL1ノルムでlossを求める。
\mathcal{L}_P (P,G) = \| P(x_s;\theta_P) - z_s \|_1 + \| P(G(x_s, \theta_G);\theta_P) - z_s \|_1
perceptual regularization
合成画像 $x_s$ と それをreal化した画像 $G(x_s, \theta_G)$ を意味的に近くするため、さらに perceptual loss を用いる。
\mathcal{L}_{perc}(G) = \| \phi (x_s) - \phi (G(x_s;\theta_G)) \|_1
$\phi(x)$ :VGG19などの学習済みモデルの中間層からの出力。
詳しくは、[6]に計算方法が書かれていて、
\mathcal{L}_{I,L}(\theta) = \sum_l \lambda_l \| \Phi_l (I) - \Phi_l (g(L;\theta)) \|_1
となっている。 $l$ はVGG19の conv1_2、conv2_2、conv3_2、conv4_2、conv5_2で、これら出力に対して差のL1を計算する。
$\lambda_l$ は各層に対する重み付けで、出力テンソルの要素数を逆数にしたものを初期値とし、学習によって最適化される変数。
学習方法
以下の2ステップで学習する
- $\theta_G, \theta_T, \theta_P$ を固定し、$\theta_D$ を学習する
- $\theta_D$ を固定し、$\theta_G, \theta_T, \theta_P$ を学習する
実験と結果
データセット
- synthetic domain に用いた dataset:SYNTHIAのSYNTHIA-RAND-CITYSCAPES(Cityscapesに似た合成画像)
- target domain に用いた dataset:Cityscapes と Mapillary Vistas datasets
- target domain の dataset は training と test に分ける
- 学習中はtarget domain のラベル情報を使わない
メトリクス及びablation studyの設定
- メトリクスはカテゴリーごとの IoU 及び mean IoU
- ablation studyは PI (previlege information)なしで効果を検証する
アーキテクチャ
generator:2 down-samplingのconv+9 residual block+2 deconv
discriminator:PatchGANのような3層
task predictor:標準的なFCN8s
privileged network:標準的なFCN8s
perceptual loss 計算時の $\phi$ :学習済みVGG19のconv1_2, conv2_2, conv3_2, conv4_2, conv5_2 からの出力
ハイパーパラメータの設定
loss の各項重み:
adversarial loss, task loss, privileged loss, perceptual loss ぞれぞれ $\alpha = 1, \beta = 0.5 \gamma = 0.1, \delta = 0.33$
data augmentation
random crop
最適化
Adam
比較モデル
- FCNs ([2])
- CDA ([3])
- LSD ([4])
- CBST ([5])
結果(1)
SYNTHIAデータセットで学習してCityscapesで評価したものは以下。

[1]Table1より
上側がcrop前の解像度320x640、下側が512x1024の場合。
各行はそれぞれのモデル、各列はカテゴリーで、最右がmean IoU。
まず mean IoUでみた場合、pribileged networkを含めたSPIGANが最も良い。
またSPIGAN-no-PI と SPIGAN(PI含む)を比較した場合、数%のmIoU改善に寄与している。
結果(2)
SYNTHIAデータセットで学習してCityscapes, 及びVitasで評価したものは以下。
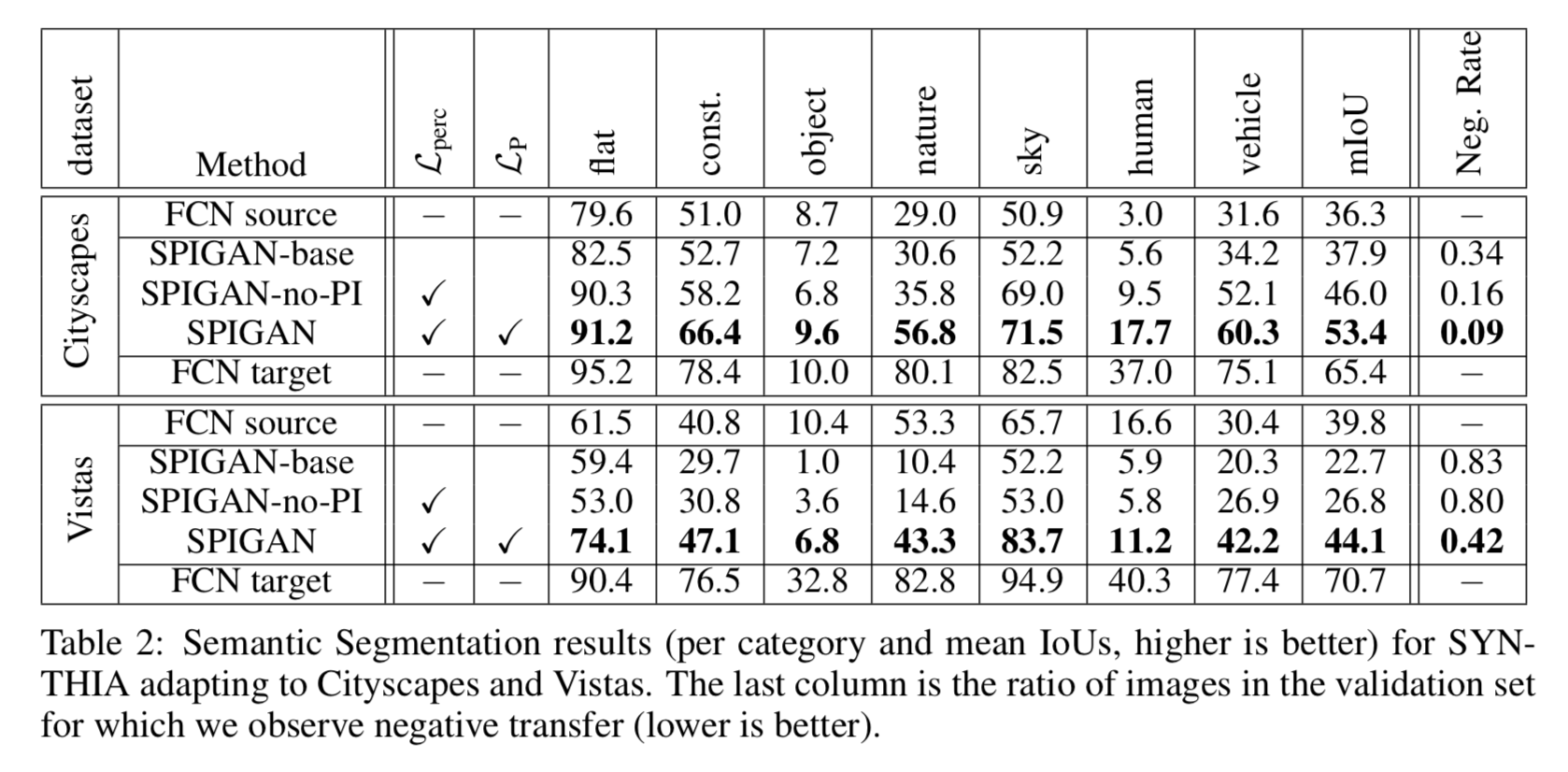 [1]Table2より
[1]Table2より
こちらはFCNsのみとの比較になるが、いずれのカテゴリーにおいてもFCNsを上回っている。
また同様に、SPIGAN-no-PI と SPIGAN(PI含む)を比較した場合、mIoU改善に寄与している。
出力例
 [1]Figure6より
[1]Figure6より
上段からsimulatorからの画像、privileged netowrk を入れない場合のadapted 画像、privileged netowrk を入れない場合のadapted 画像。
一番右側の例では、simulatorの画像に影が入っているため、privileged networkがない場合はこの部分を影がある道路と認識できず、混乱した画像となっている。
一方、privileged networkがある場合は、深さ情報から道路だとわかるためか、影のある道路をうまく表現できている。
自分の学習例
上記作成したーコードで学習させてみた結果。

左からSYNTHIAの合成画像、それをgeneratorでadaptedした画像、合成画像に対するセグメント推論(task predictorからの出力)、adapted画像に対するセグメント推論、セグメントの正解値。
合成画像がCityScapeっぽい青みがかった色になっている。
以下は20epoch学習後のCityScapeデータのvalidationに対する推論。

左からCityScape画像、それに対するセグメント推論、セグメントの正解値。
やはり学習データに対する推論に比べて精度が落ちる。特に学習データにないもの・・・例えば画像下側に映り込んだ車の一部・・・に対する推論がうまくいってない。
実装のハマりどころ
ネットワークに関しては普段からGAN系を実装していれば、特に問題無し。
SYNTHIAのデータは要注意。実際は人や車等、複数ある物体に関してインスタンスごとに色分けされている。しかしその色に規則性が見当たらない。
なので、先行研究でSYNTHIAを使った方が作成した修正データを利用した。
reference
[2] Judy Hoffman, Dequan Wang, Fisher Yu, and Trevor Darrell. Fcns in the wild: Pixel-level adversar- ial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016b.
[3] Yang Zhang, Philip David, and Boqing Gong. Curriculum domain adaptation for semantic segmen- tation of urban scenes. In International Conference on Computer Vision, 2017.
[4] Swami Sankaranarayanan, Yogesh Balaji, Arpit Jain, Ser Nam Lim, and Rama Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In Computer Vision and Pattern Recognition, 2018.
[5] Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In European Conference on Computer Vision, 2018.
[6] Qifeng Chen and Vladlen Koltun. Photographic image synthesis with cascaded refinement networks. In International Conference on Computer Vision, Oct 2017.