はじめに
INTERSPEECH 2021 というカンファレンスから以下の論文
[1] X. Cai, et. al. Speech Emotion Recognition with Multi-task Learning
のまとめ
-
論文のリンク:
https://www.isca-speech.org/archive/interspeech_2021/cai21b_interspeech.html -
GitHubコード:
https://github.com/TideDancer/interspeech21_emotion -
コンペと結果:
https://paperswithcode.com/sota/speech-emotion-recognition-on-iemocap
ここで見つけた
概要
- 音声からの感情認識(Speech Emotion Recognition: SER)を行うモデル
- ベースとするアーキテクチャは wav2vec-2.0
- 音声からtextを推定すると同時に音声から感情を分類するというマルチタスクで学習を進める
- IEMOCAPのdatasetでSOTAを達成した
related work
この分野は詳しくないので、ここも簡潔にまとめ
SER に関して昔の手法
- ピッチ、エネルギー、フォルマント、メルバンドエネルギー、メル周波数、ケプストラム係数、を特徴量として用いたり、音声レベルの特徴量を用いる
- これらの特徴量をSVMやLDA(線形判別分析)、QDA(2次判別分析)、HMM(隠れマルコフモデル)に入力して分類した
SER に関して Deep Learning 登場以後
- Deep Learning登場後初期はCNNやLSTMを用いた手法
- その後 self-attention を用いた手法が登場
Wav2Vec-2.0 に関して
- BERTが自然言語処理の様々なタスクでfine-tuneされて用いられるのと同様に、wav2vec-2.0も音声認識タスクでfine-tuneされて用いられている
- wav2vec-2.0は自己教示あり学習も行なっていて、これにより高性能なモデルとなっている
モデルのネットワーク構造
モデルのネットワーク構造は以下。
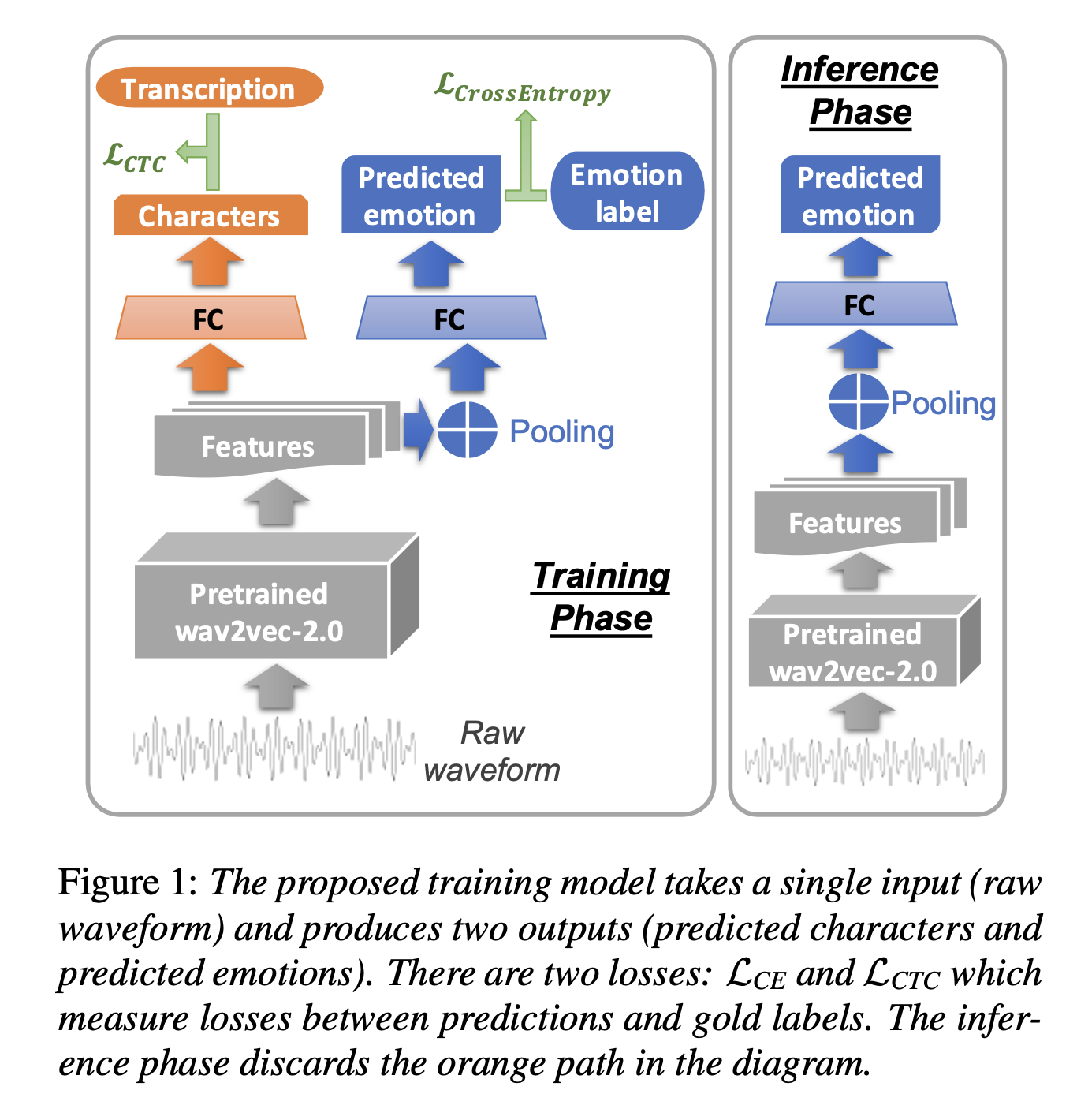
まず学習時は上図の左側。図中下の音声を事前学習したwav2vec-2.0に入力し、特徴量を出力する。
ここから感情を学習する青い部分とテキストを学習するオレンジの部分に分かれる。感情を学習する部分では特徴量をpoolingした後に全結合し、感情を推定する。
一方でテキストを学習する部分では全結合し、テキストを推定する。
学習と推論
- テキストを学習する部分は CTC lossを用いる
- 感情を学習する部分は 交差エントロピー lossを用いる
- この両者のlossを最小化するよう学習する
実験と結果
IEMOCAP datasetを用いた定量的評価
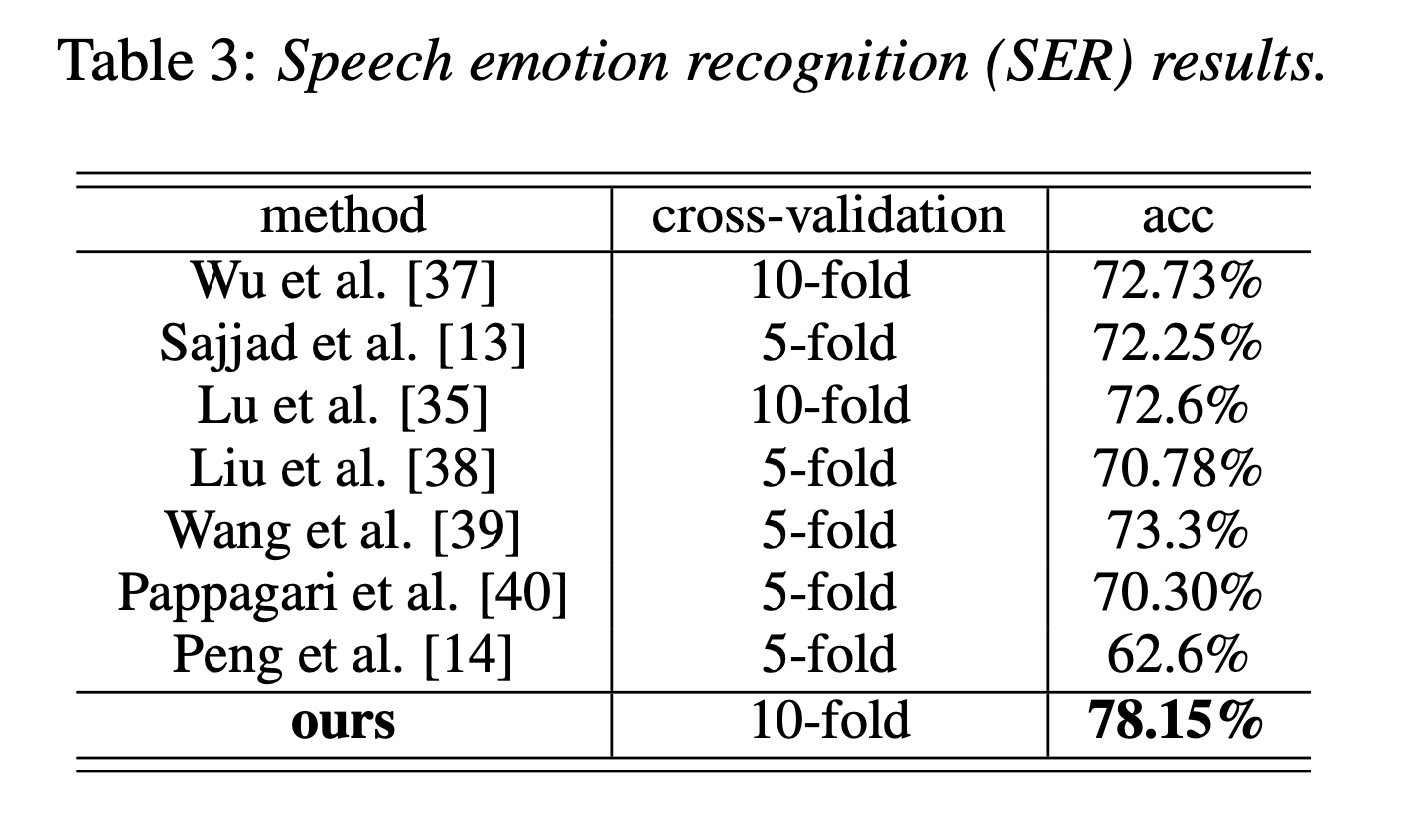
他の手法よりかなりよい。ただし、他の手法がどのようなモダリティを使っているかは不明。
ablation study
ここでは loss において
\min_{\theta, \phi} \mathcal{L} = \mathcal{L}_{\rm CE} + \alpha \mathcal{L}_{\rm CTC}
右辺1項目交差エントロピー loss と右辺2項目CTC lossとの比を調整する係数 $\alpha$ を変化させ、その精度を測定することで、テキストを学習する部分の効果を検証した。結果は以下。
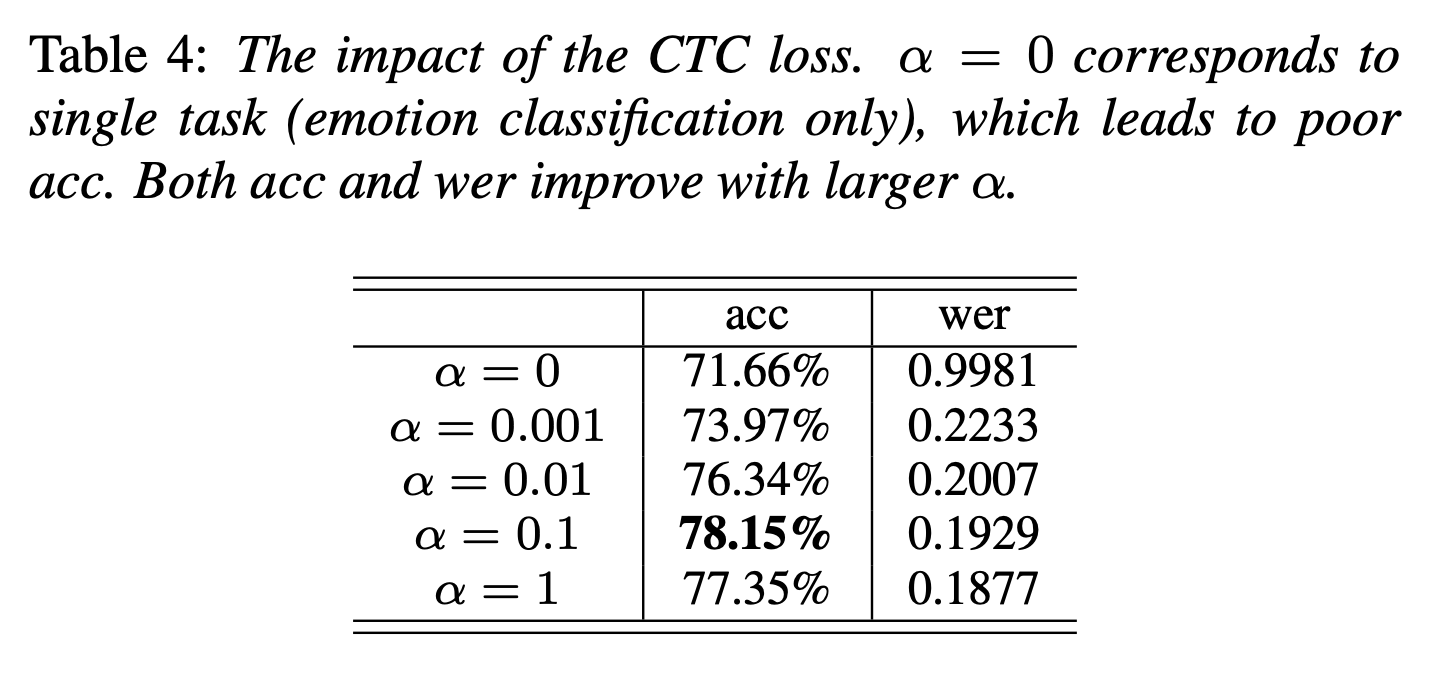
まず、αが0の時に比べて、$\alpha > 0$ の方がよいので、テキスト学習部分の効果は有ると言える。
特に $\alpha = 0.1$ の場合が最も良い。