はじめに
CVPR2019より以下の論文
[1] L. Shi, et. al."Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition".CVPR2019
のまとめ
github:
https://github.com/lshiwjx/2s-AGCN
pytorch実装、商用利用不可
概要
- 骨格から行動を推定するモデルのうち、graph convolutionを使う系
- グラフ構造を適応的にした
- また関節の位置のみでなく、四肢の長さや方向を情報として使用した
背景
骨格(関節)から行動を推定するという手法は、背景に影響されないなど汎用性の高さから近年注目を浴びている。この手法の旧来モデルはRNNや1d-convなどを使ったものだった。これに対し、Yanら[2]は2018年、最初にgraph convolutionを使ったモデルを提案し、高い精度を達成した。
しかし彼らのモデルはmanuelに決められた同一のグラフ構造を全ての層で使い、また関節の位置のみを情報として与えていた。よって以下の問題点があった。
問題点(1)manuelに与えたグラフ構造は行動推定に対して最適なものでないだろう
問題点(2)さらに各層のグラフ構造は異ってしかるべきで、全ての層に対して同じグラフ構造を適応することは最適でないだろう
問題点(3)異なる行動においては、それを推定するグラフ構造は異なるだろう
問題点(4)関節の位置情報しか使用していない
本手法では問題点(1)、(2)に対しては各層でグラフ構造を適応的にすることで対応し、問題点(3)に対してはdata固有のグラフ構造とすることで対応する。また問題点(4)に対しては四肢の長さや方向を情報として利用する。
手法
st-gcnのグラフ畳み込み
詳細は拙著
https://qiita.com/masataka46/items/78480b730df1326b883b
等参照
ここでは完結にst-gcnで提示されているグラフ畳み込みをおさらい。
${\bf f}_{in}$ :入力のfeature map
${\bf f}_{out}$ :出力のfeature map
${\bf W}_k$ :partiton strategy k に対応する重み
$\bar{\bf A}_k \in \mathbb{R}^{N \times N}$ :partiton strategy k に対応する隣接行列
${\bf A}_k = {\bf \Lambda}_k^{-\frac{1}{2}} \bar{\bf A}_k {\bf \Lambda}_k^{-\frac{1}{2}} \in \mathbb{R}^{N \times N}$ :隣接行列を正規化したもの
${\bf M}_k \in \mathbb{R}^{N \times N}$ :partiton strategy k に対応するattention mapで、各関節の重要度を示す
として、グラフ畳み込みは
{\bf f}_{out} = \sum_k^{K_v} {\bf W}_k ({\bf f}_{in} {\bf A}_{k} ) \odot {\bf M}_{k} \tag{2}
となる。
Adaptive graph convolutional layer
本論文の特徴の1番目。先に述べたように、グラフ構造におけるconnectionを適応的に、かつ各層で異なるものにする。
以下はユニットの詳細図。
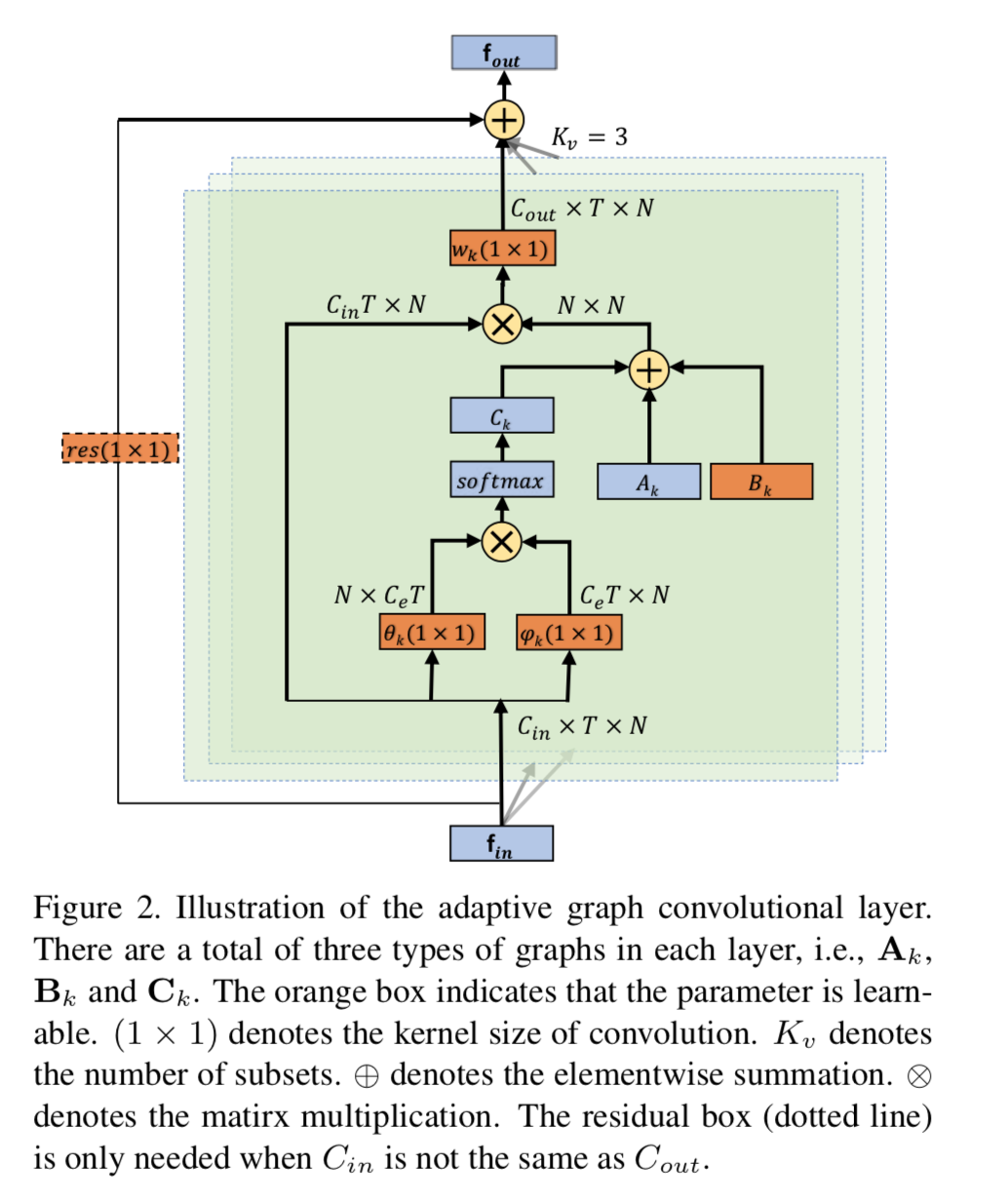
具体的には(2)式を以下のように変更する。
{\bf f}_{out} = \sum_k^{K_v} {\bf W}_k {\bf f}_{in}( {\bf A}_{k} + {\bf B}_{k} + {\bf C}_{k}) \tag{3}
以下、${\bf A}_{k}, {\bf B}_{k}, {\bf C}_{k}$ の説明。
1)${\bf A}_{k}$
(2)式と同じadjacency matrixで、学習において固定されてる
2)${\bf B}_{k}$
学習によってパラメータが変更されるmatrix。図中では学習対象を意味するオレンジ色に塗られている。(2)式の ${\bf M}_{k}$ と役割的に似てるが、maskをmultiplyするだけだと、adjacency matrixが0のconnectionは0のままなので、新たなconnectionを作ることはない。この点で異なる。
3)${\bf C}_{k}$
前者2つが入力データによらず一定であるのに対して、${\bf C}_{k}$ は入力データによって値が変わる。図では、attention的に値が決められている。
具体的には、図のようにshape(C, T, N)の入力データに対してパラメータ $\theta_k$ で 1x1 convを行ない、transposeとreshapeして(N , C x T)を生成する。
一方で同じshape(C, T, N)の入力データに対してパラメータ $\phi_k$ の 1x1 convを行い、reshapeして(C x T, N)を生成する。
この両者のドット積を計算して(N, N)のtensorを生成するが、各要素は対応するconnectionの強度のようなものを想定する。これにsoftmaxをかけて0-1に正規化し、${\bf C}_{k}$ とすると、隣接行列のようなものが生成されるだろう。
{\bf C}_{k} = softmax({\bf f}_{in}^T {\bf W}_{\theta k}^T {\bf W}_{\phi k} {\bf f}_{in})
ここで「2つのconvからドット積を計算する」という部分の解釈を考える。θ で特徴量化したある $n$ とφで特徴量化した別の n' とで類似性を計算していることになる。仮にθを上側への速度の強度、φを下側への速度の強度と考えると、上側への速度の強度が高い n と下側への速度の強度が高い n' の組み合わせがドット積の結果高くなり、最終的に隣接行列上の高い値として与えられることになる。
Two-stream networks
本論文の特徴の2番目。先に述べたように、関節の位置のみでなく、四肢の長さや方向も情報として加える。具体的には、体の中心側の関節から、末端側の関節への四肢のベクトルによって長さと方向を表現する。つまり
${\bf v}_1 = (x_1, y_1, z_1)$ :体の中心側の関節の位置
${\bf v}_2 = (x_2, y_2, z_2)$ :体の中心側の関節の位置
として、
{\bf e_{v_1, v_2}} = (x_2 - x_1, y_2 - y_1, z_2 - z_1)
とする。
またネットワークはこの図のように
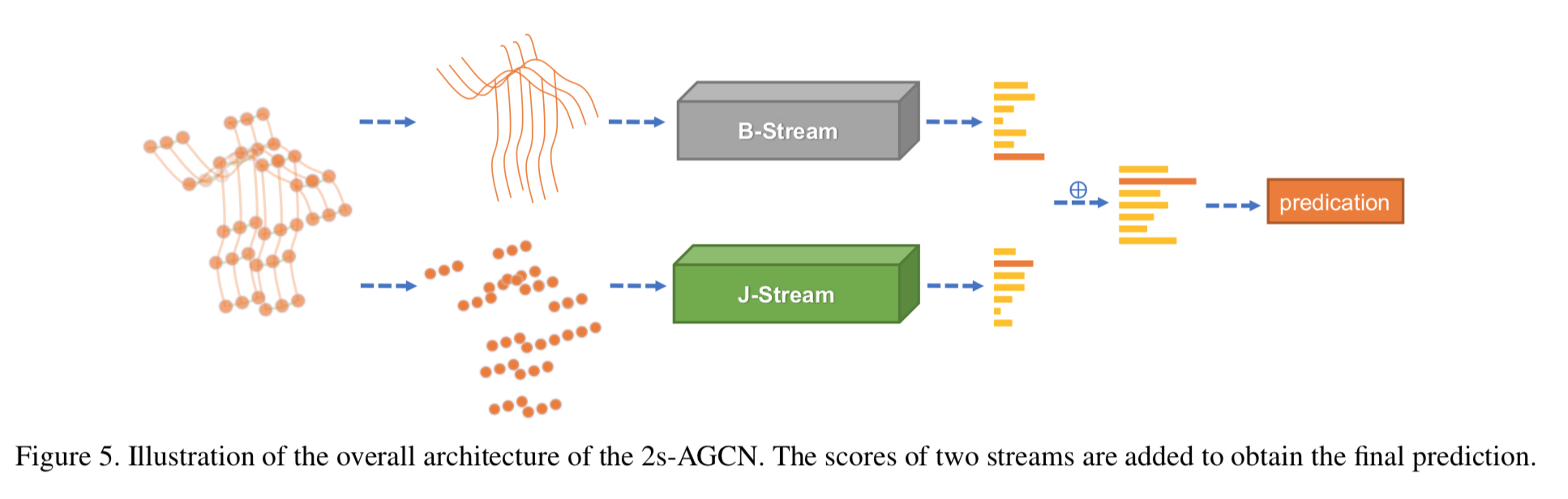
関節を入力する系統と四肢の長さ・向きを入力する系統とで完全に分ける。
学習方法
- 最適化:momentum(0.9)
- batch size:64 -> これは4つのGPUを使う場合で、手元の1080Ti(11GB)1枚だと16が限界だった
- loss: 交差エントロピー
- leraning rate: 0.1
- weight decay掛け率: 0.0001
実験と結果
ablation study
A, B, Cの効果を測定した。
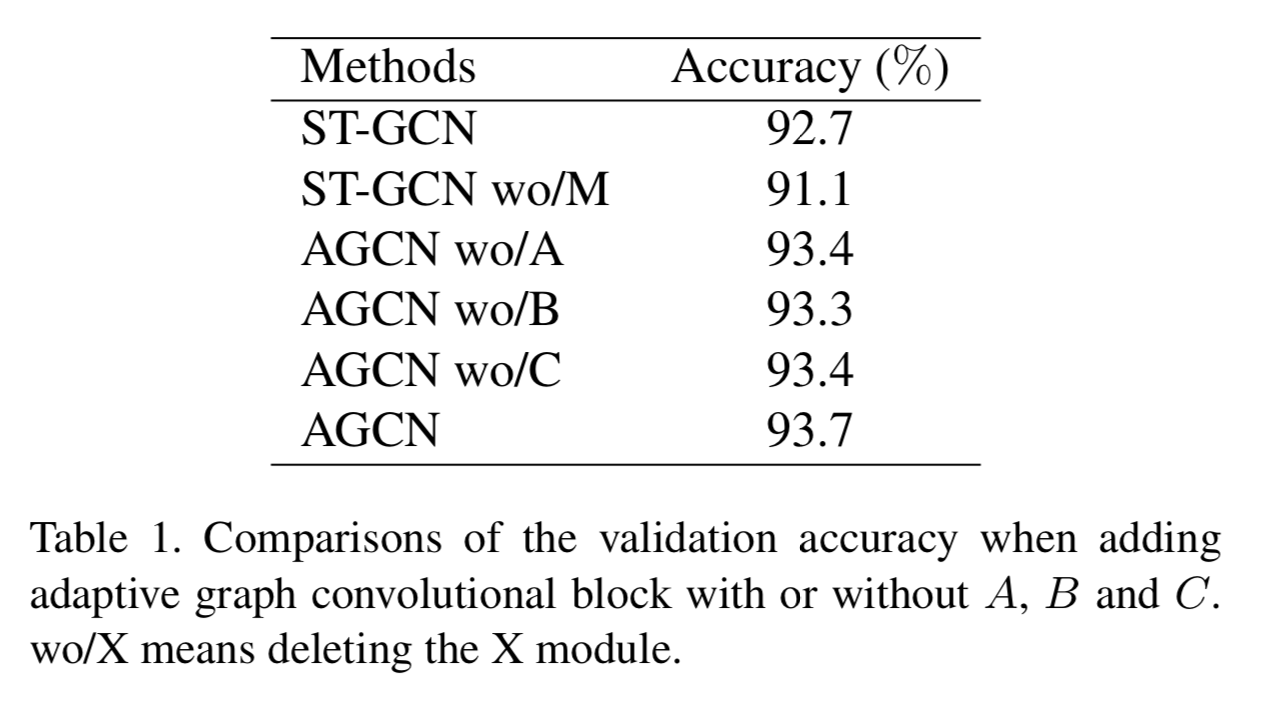
上から、ST-GCNそのもの、ST-GCNからmaskを無くしたもの、AGCN(本手法)からAを無くしたもの、AGCNからBを無くしたもの、AGCNからCを無くしたもの、AGCNそのもの(つまりABC全て入ったもの)。全て入ったものが一番よい。
また以下は左がAで、右が学習後のB(?)。

Aにないconnectionに対して、関係性を学習している。
また以下は2 streamの効果を見たもの。
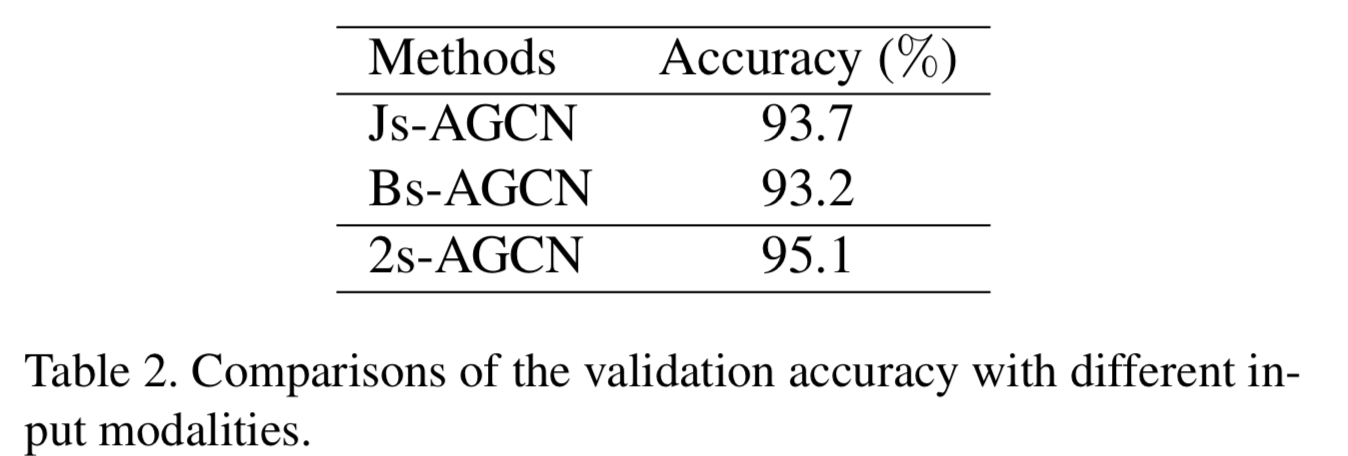
上から入力データがjoint位置単体、入力データが四肢の長さと向き、両方使った2-stream。もちろん2-streamがよい。
NTU-RGB+D 60 を用いた定量的評価
以下はNTU-RGB+D 60 datasetを用いた場合の他のモデルとのaccuracy比較。
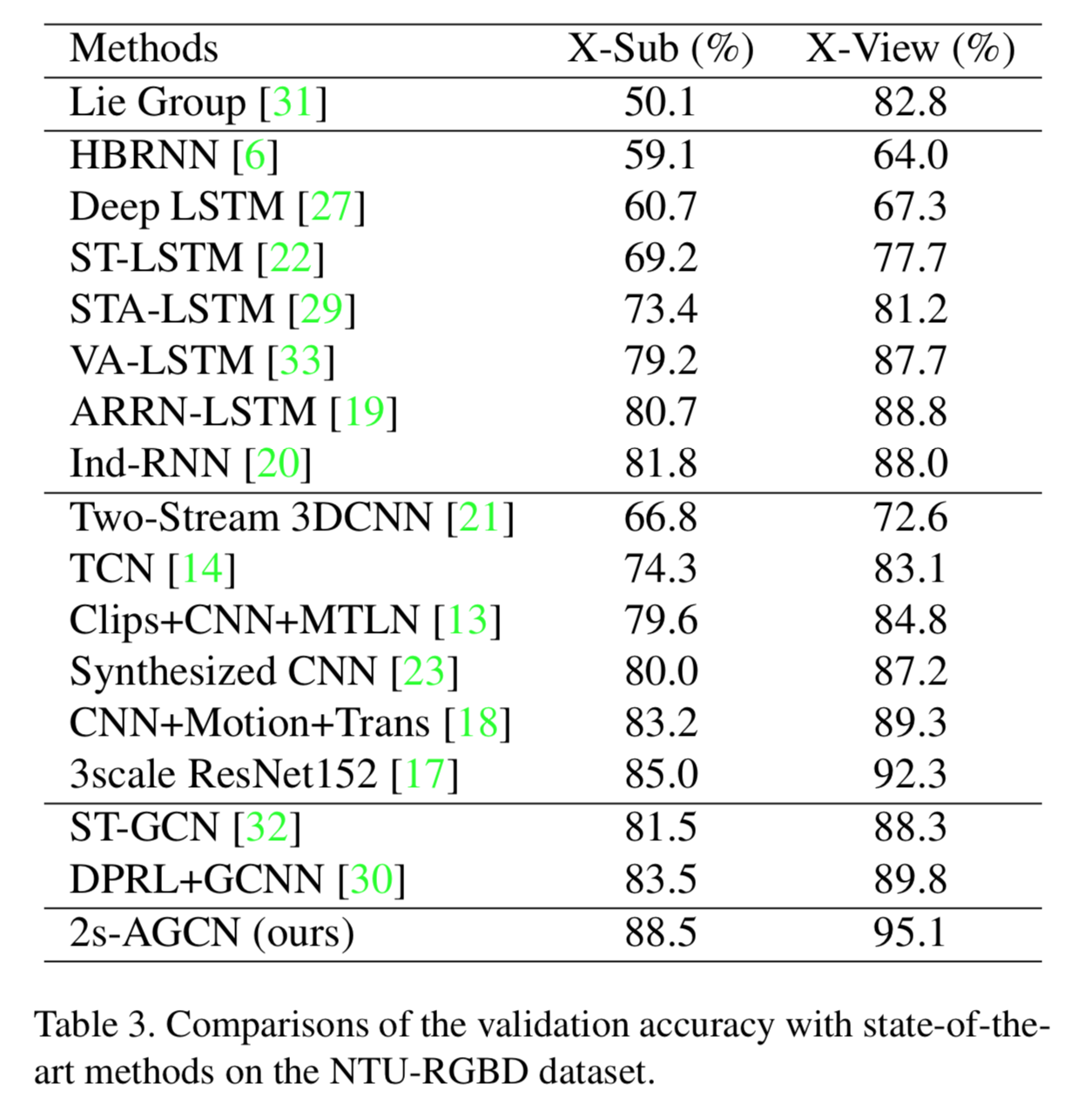
2019年時点でSOTAだった他のモデルと比較してもかなりよい。
Kinetics-Skeleton を用いた定量的比較
Kinetics-Skeleton を用いた場合の他のモデルとのaccuracy比較。
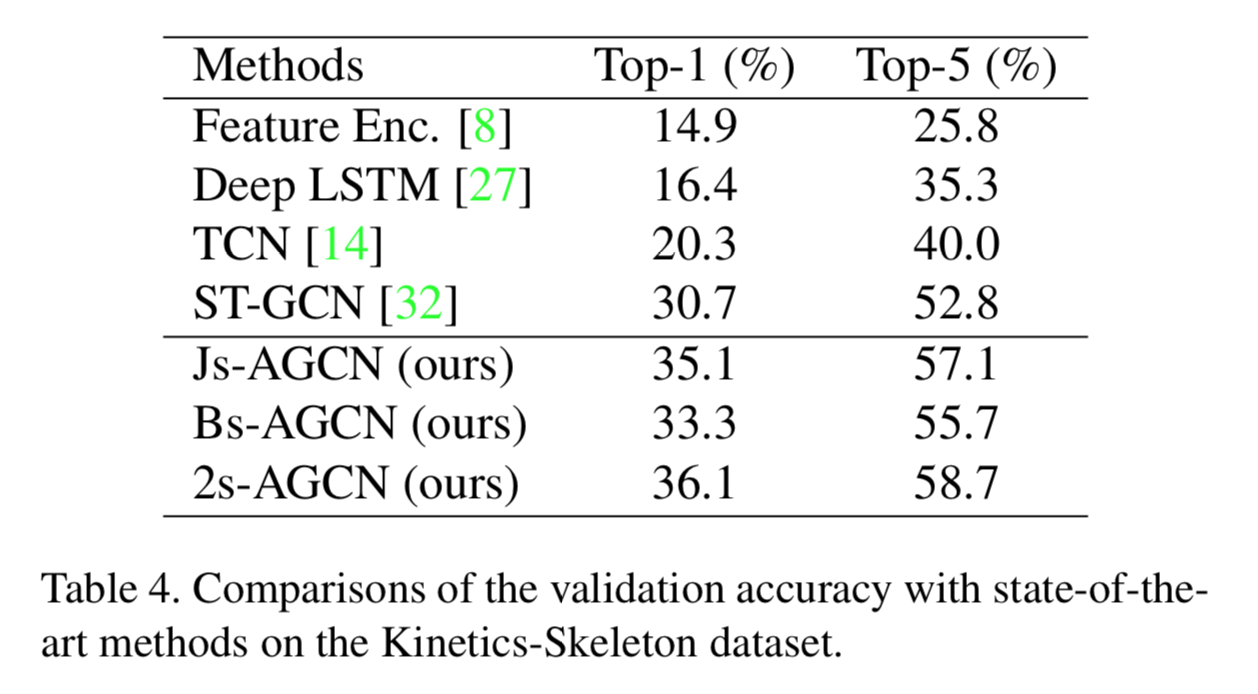
こちらも同様に精度がよい。
reference
[2] Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In AAAI, 2018