環境
GPU GTX1070
ubuntu 14.04
chainer 1.14.0
など
はじめに
Deuling Networkのコードを実装する2回目。前回はchainer/functions/connection/bilinear.pyを確認した。
http://qiita.com/masataka46/items/3ec187a5ff30fb416eae
今回はそれを踏まえてforward()とbackward()を変更していく。
forward()の変更
まず順伝播の計算を変更する。概略は以下のようになる。
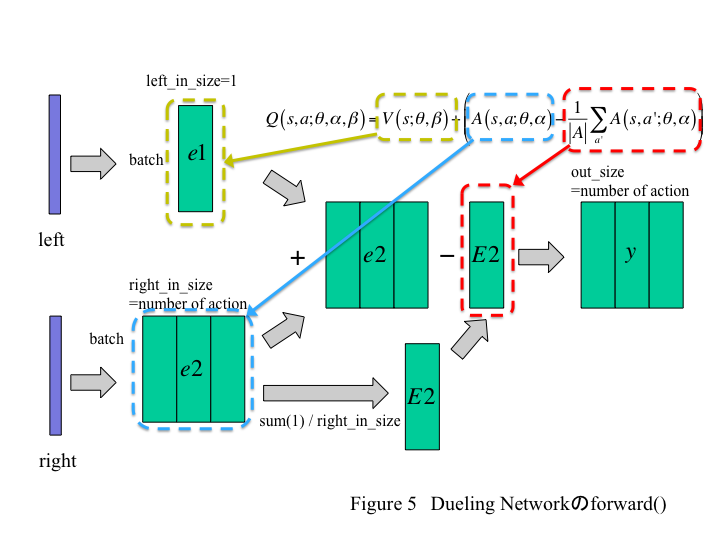
Numpyのブロードキャストという仕組みを使えば、大きさの違う行列間でも一定の法則のもとに足し引きできる。これを使っている。
まずブロードキャストでe1とe2を足す。これでe2のそれぞれの列に対してe1が足される。一方、e2を列方向に平均化したものをE2として生成する。再度ブロードキャストを使って、先に足したものからE2を引くとyが求まる。
forward()関数内は以下のように修正する。
def forward(self, inputs):
e1 = array.as_mat(inputs[0])
e2 = array.as_mat(inputs[1])
W = inputs[2]
#modified algorithm
y = e1 + e2 - e2.sum(1).reshape(len(e2), 1) / len(e2[0])
return y,
e1のbackwardを求める
まずV側へのδであるge1を求める。下図のようになるだろう。(計算間違ってたら教えてください)
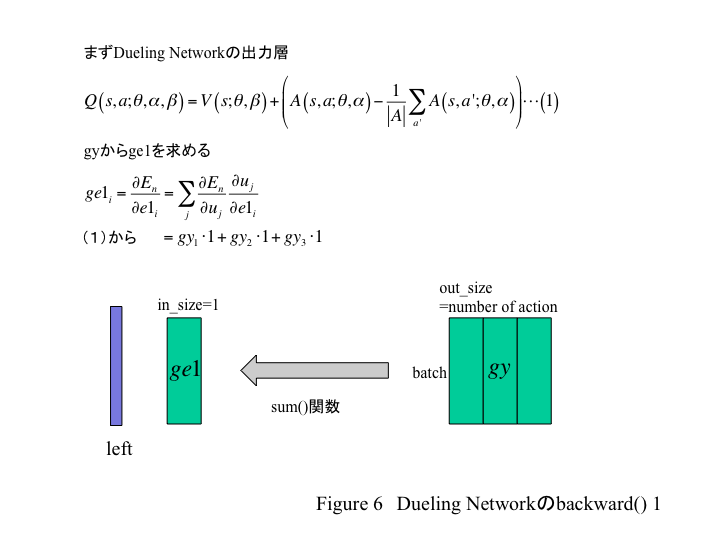
gyをsum()で列方向に足し合わせればいいだろう。
ge1 = cupy.sum(gy, axis=1).reshape(len(gy), 1).astype(dtype=gy.dtype, copy=False)
e2のbackwardを求める
次にA側のδであるe2を求める。下図のようになるだろう。
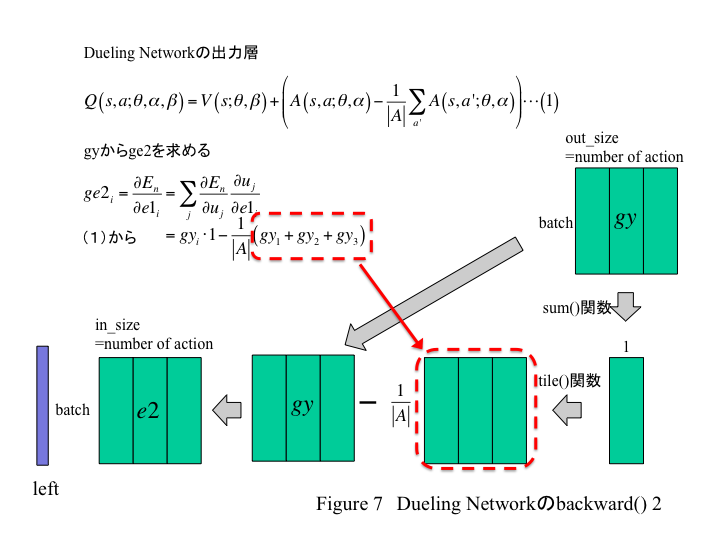
工夫が必要なのは(gy1+gy2+gy3)の部分だろうか。ここはcupy.sum()関数で値を足し、これをcupy.tile()で展開する。よってforward()のコードを以下のように書き換える。
def backward(self, inputs, grad_outputs):
e1 = array.as_mat(inputs[0])
e2 = array.as_mat(inputs[1])
W = inputs[2]
gy = grad_outputs[0]
'''
xp = cuda.get_array_module(*inputs)
if xp is numpy:
gW = numpy.einsum('ij,ik,il->jkl', e1, e2, gy)
ge1 = numpy.einsum('ik,jkl,il->ij', e2, W, gy)
ge2 = numpy.einsum('ij,jkl,il->ik', e1, W, gy)
else:
kern = cuda.reduce('T in0, T in1, T in2', 'T out',
'in0 * in1 * in2', 'a + b', 'out = a', 0,
'bilinear_product')
e1_b = e1[:, :, None, None] # ij
e2_b = e2[:, None, :, None] # ik
gy_b = gy[:, None, None, :] # il
W_b = W[None, :, :, :] # jkl
gW = kern(e1_b, e2_b, gy_b, axis=0) # 'ij,ik,il->jkl'
ge1 = kern(e2_b, W_b, gy_b, axis=(2, 3)) # 'ik,jkl,il->ij'
ge2 = kern(e1_b, W_b, gy_b, axis=(1, 3)) # 'ij,jkl,il->ik'
'''
ge1 = cupy.sum(gy, axis=1).reshape(len(gy), 1).astype(dtype=gy.dtype, copy=False)
gy_sum = cupy.sum(gy, axis=1).reshape(len(gy), 1).astype(dtype=gy.dtype, copy=False)
gy_tile = cupy.tile(gy_sum, len(gy[0])).astype(dtype=gy.dtype, copy=False)
ge2 = (gy - gy_tile / len(gy[0])).astype(dtype=gy.dtype, copy=False)
gW = cupy.zeros(len(e1[0])*len(e2[0])*len(e2[0])).reshape(len(e1[0]), len(e2[0]), len(e2[0])).astype(dtype=gy.dtype, copy=False)
ret = ge1.reshape(inputs[0].shape), ge2.reshape(inputs[1].shape), gW
if len(inputs) == 6:
V1, V2, b = inputs[3:]
gV1 = e1.T.dot(gy)
gV2 = e2.T.dot(gy)
gb = gy.sum(0)
ge1 += gy.dot(V1.T)
ge2 += gy.dot(V2.T)
ret += gV1, gV2, gb
return ret
LISで性能を検証する
LIS ver2のexampleゲームで性能を検証した。LIS ver2に関してはこちらを参照されたし。
http://qiita.com/masataka46/items/977eba5010c1f000dc1d
40万ステップほど学習させた結果が以下のグラフ。
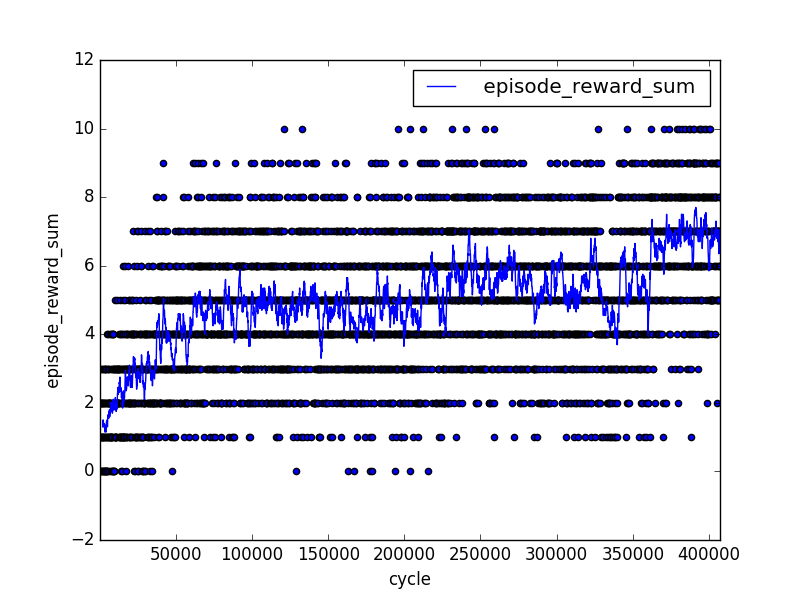
DQN(Mnih,2015)より性能が上がってる気がするな〜。ちゃんとした比較はしてないけど。
Atari 2600で性能を検証する
Atari 2600のBreakOutで性能を検証した。結果は以下のグラフ。
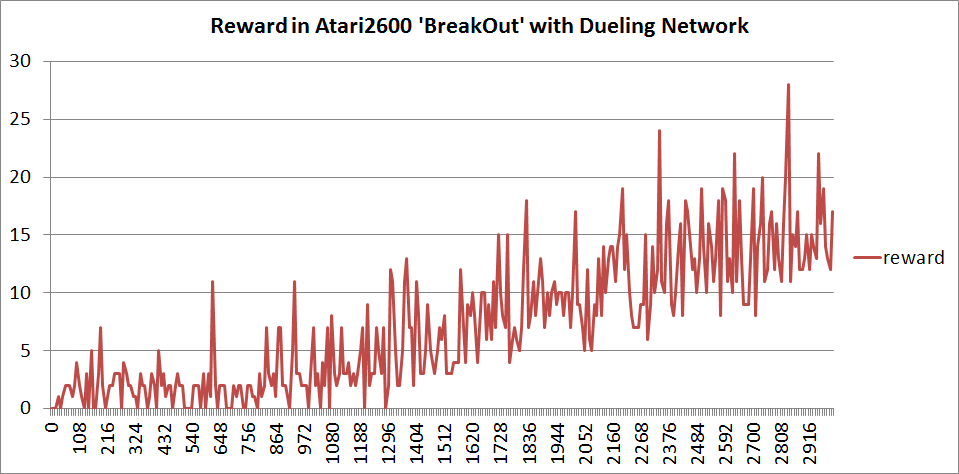
横軸がepisodeで、縦軸が各episodeで受け取ったreward。確実に上昇してるね。
コードの場所
LIS ver2用のコードはこちらにあげました。
https://github.com/masataka46/DuelingNetwork_for_LIS
Atari2600用のコードはこちらにあげました。
https://github.com/masataka46/DuelingNetwork