はじめに
NIPs2017で採択されたDA-GANの論文をまとめてみた。
NIPs上の論文ページはこちら。
http://papers.nips.cc/paper/6612-dual-agent-gans-for-photorealistic-and-identity-preserving-profile-face-synthesis
NIPs上のポスターはこちら。
https://zhaoj9014.github.io/pub/ZHAOJIAN_ID70.pdf
要点
いろんな角度の顔画像から個人を特定できると有益である。しかし多くの撮影労力とラベリング労力が必要なので、1つの顔からシミュレータでいろんな角度の顔画像を合成したい。しかしこれまでの合成された顔画像は、本物の顔画像からはほど遠く、学習に使えない。
そこで本論文DA-GANモデルでは新たな仕組みを提案する。これにより個人のidentityを保持しながら本物っぽい顔画像へと変換する。
具体的にはgeneratorで合成画像を本物っぽく変換し、auto-encoderを用いたdiscriminatorでidentityの判別を行ったり、refineされた画像と本物画像との差を縮めたりする。
通常のGANに対する変更点は以下である。
- 合成画像とそれをrefineした画像とで顔の角度を一定にするlossを加えた
- 個人のidentityを保持するlossを加えた
- adversarial lossに境界平衡正則化項をくわえた
この結果、NIST IJB-Aのベンチマークでstate-of-the-artsな結果となった。
モデル
モデルの概略図は以下。(Figure 2より)
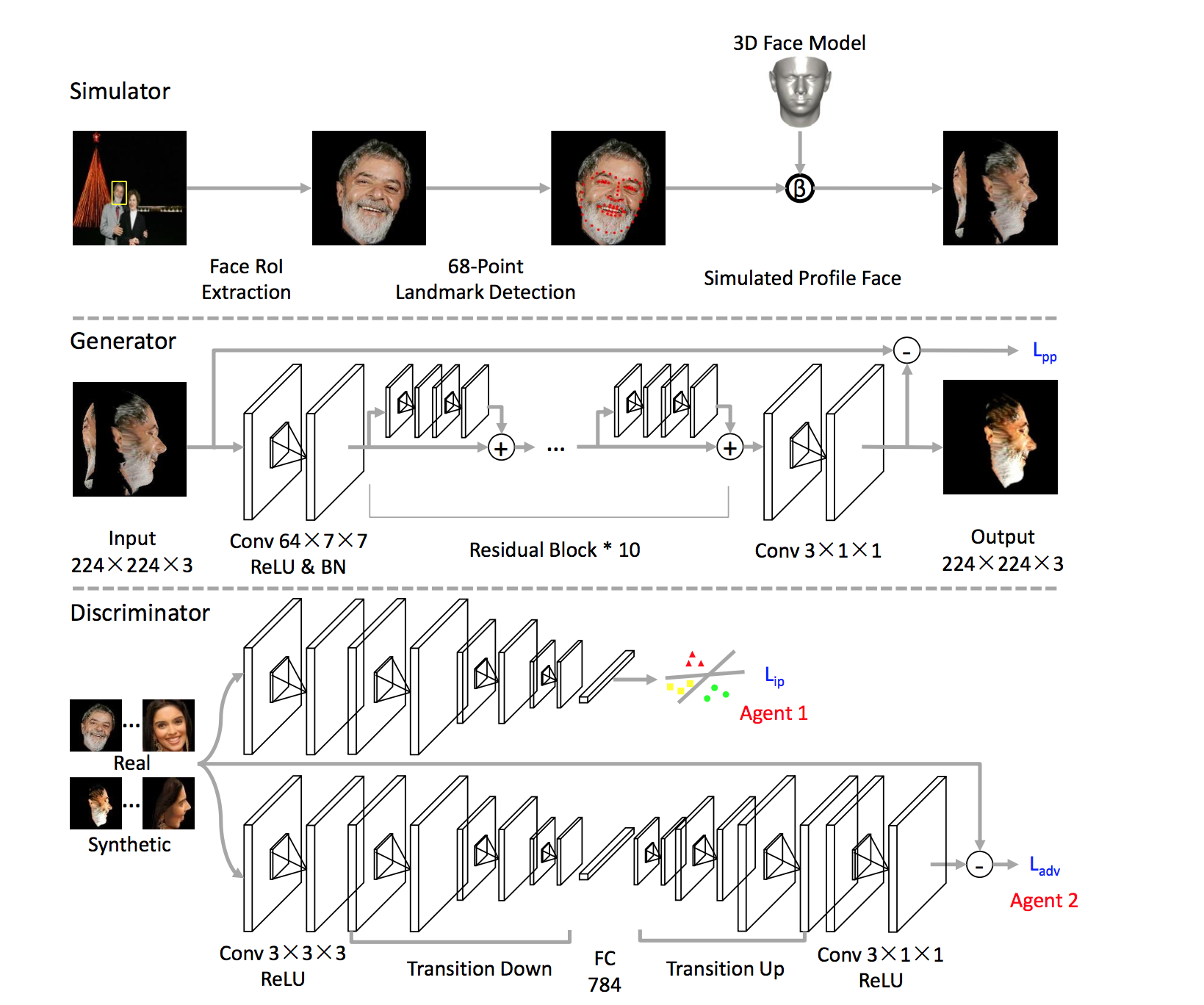
1 simulator

以下の順で顔が映った画像から任意の角度の顔画像を生成する。
- 写真から顔の領域(RoI)を切り抜く
- Recurrent Attentive Refinement(RAR)を使って68点の顔ポイントを検出する
- 3Dの顔モデルと重ね合わせる
- 任意の角度に回転させる
2 generator

この図のようにFCNとResNetを組み合わせた構造。refineした画像 $\tilde{x}$ は出力されると同時に元の画像 $x$ とのピクセルごとの差分
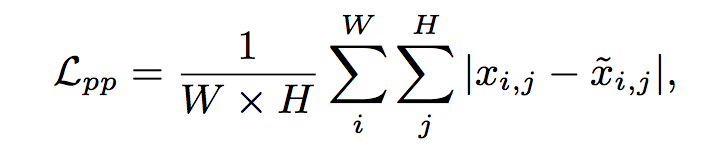
が算出される。この点はsimGANと似ている。
3 discriminator

この図のように Dual な Agent を持つ。
Agent 1 は顔のidentityを保持するよう、identityのラベルで交差エントロピーを算出する。
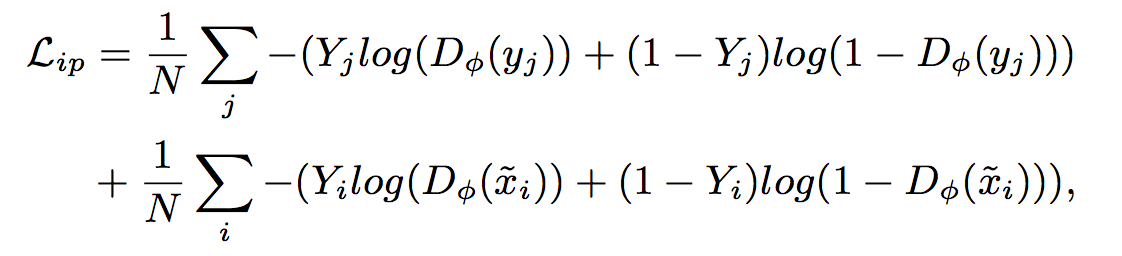
Agent 2は若干ややこしい。
まず本物なり偽物なりの顔画像を入力し、encode+decodeして元の画像サイズを出力する。
次にauto-encoderごとく、出力と入力画像との差を算出する。つまり本物画像を入れた時の差
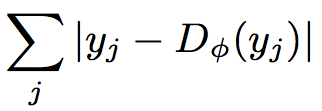
と偽物画像(refineされた画像)を入れた時の差

を求める。
次にこれらからWesserstein距離を求める。このWesserstein距離なるものがわかりづらいが、とりあえずこうすれば

よさそう。ここで$k_t$は境界平衡正則化項(boundary equilibrium regularization term)なるもので、

となるように目指すもの。具体的には
 で更新する。
で更新する。
4 Loss
discriminatorのLoss $L_{D_{\phi}}$ および generatorのLoss $L_{G_{\theta}}$ はこんな感じ。

discriminatorのlossは $L_{adv}$ に $L_{ip}$ を加えたもの。generatorのLossはさらに $L_{pp}$ を加えることでrefineによって顔の角度が変わらないようにしている。
勝手な解釈
いまいちよくわからない仕組みではあるが、独断と偏見で解釈してみる。
- $L_{pp}$ は顔の角度を保持するため
- $L_{ip}$ は顔のidentityを保持するため
この2つは問題なさそう。問題は $L_{adv}$ 。

の中で第1項はautoencoderに本物の画像を入れた時の出力 $D_{\phi}(y_{j})$ と入力画像 $y_j$ との差。出力 $D_{\phi}(y_{j})$ はencode-decodeすることで顔を表現する主要な特徴量で形成されていると考えると、その出力との差は冗長な部分・・・ノイズとか肌質とかだろうか(?)
同様に第2項目のΣ内はautoencoderに偽物の画像を入れた時の出力と入力画像 $y_j$ との差。こちらも冗長な部分になるだろうか。
ただし、偽物画像を本物っぽくするには、偽物画像の冗長な部分を本物画像のそれに近づける必要がある。よって $L_{adv}$ では両者の差を取り、これをDiscriminatorでは最小化させている。
一方で、そもそもautoencoder自体をちゃんと学習させる必要がある。generatorのLoss: $L_{G_{\theta}}$ は

であるが、$L_{adv}$ の第1項目はgeneratorに関係がないので、
$$L_{G_{\theta}}=(\sum_i | {\tilde{x_{i}}-D_{\theta} (\tilde{x_{i}})} | +\lambda_{1}L_{ip})+\lambda_{2}L_{pp}$$
となりΣの部分でautoencoderとしての学習をすることになる。
よってgeneratorのLossによりautoencoderの学習をさせつつ、discriminatorのLossで偽物画像と本物画像の本物っぽさを近づけていると言える(?)
サンプルコード(モデルとトレーニング・ループのみ)
import numpy as np
import os
import pylab
import tensorflow as tf
real_image_dir = './real_img'
syn_image_dir = './fake_img'
out_image_dir = './out_images_simGAN' #output image file
batchsize = 512
n_epoch = 100
lambda_ = 0.0001
data_num = 10000
try:
os.mkdir(out_image_dir)
except:
pass
# generator------------------------------------------------------------------
w0 = tf.Variable(tf.random_normal([4, 4, 3, 64], mean=0.0, stddev=0.05), dtype=tf.float32)
scale0 = tf.Variable(tf.ones([64]))
beta0 = tf.Variable(tf.zeros([64]))
w1_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w1_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w2_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w2_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w3_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w3_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w4_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w4_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w5_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w5_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w6_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w6_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w7_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w7_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w8_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w8_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w9_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w9_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w10_1 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w10_2 = tf.Variable(tf.random_normal([3, 3, 64, 64], mean=0.0, stddev=0.1), dtype=tf.float32)
w11 = tf.Variable(tf.random_normal([1, 1, 64, 3], mean=0.0, stddev=0.1), dtype=tf.float32)
def generator(z):
#first of all, convolve image to 64 features
conv0 = tf.nn.conv2d(z, w0, strides=[1, 1, 1, 1], padding="SAME")
conv0_relu = tf.nn.relu(conv0)
#batch normalization
batch_mean11, batch_var11 = tf.nn.moments(conv0, [0, 1, 2])
bn0 = tf.nn.batch_normalization(conv0_relu, batch_mean11, batch_var11, beta0, scale0 , 0.001)
#block1 conv-bn-relu-conv-bn-relu-plus
conv1_1 = tf.nn.conv2d(bn0, w1_1, strides=[1, 1, 1, 1], padding="SAME")
conv1_1_relu = tf.nn.relu(conv1_1)
conv1_2 = tf.nn.conv2d(conv1_1_relu, w1_2, strides=[1, 1, 1, 1], padding="SAME")
plus_1 = conv1_2 + conv0_relu
plus_1_relu = tf.nn.relu(plus_1)
#block2 conv-bn-relu-conv-bn-relu-plus
conv2_1 = tf.nn.conv2d(plus_1_relu, w2_1, strides=[1, 1, 1, 1], padding="SAME")
conv2_1_relu = tf.nn.relu(conv2_1)
conv2_2 = tf.nn.conv2d(conv2_1_relu, w2_2, strides=[1, 1, 1, 1], padding="SAME")
plus_2 = conv2_2 + plus_1_relu
plus_2_relu = tf.nn.relu(plus_2)
#block3 conv-bn-relu-conv-bn-relu-plus
conv3_1 = tf.nn.conv2d(plus_2_relu, w3_1, strides=[1, 1, 1, 1], padding="SAME")
conv3_1_relu = tf.nn.relu(conv3_1)
conv3_2 = tf.nn.conv2d(conv3_1_relu, w3_2, strides=[1, 1, 1, 1], padding="SAME")
plus_3 = conv3_2 + plus_2_relu
plus_3_relu = tf.nn.relu(plus_3)
#block4 conv-bn-relu-conv-bn-relu-plus
conv4_1 = tf.nn.conv2d(plus_3_relu, w4_1, strides=[1, 1, 1, 1], padding="SAME")
conv4_1_relu = tf.nn.relu(conv4_1)
conv4_2 = tf.nn.conv2d(conv4_1_relu, w4_2, strides=[1, 1, 1, 1], padding="SAME")
plus_4 = conv4_2 + plus_3_relu
plus_4_relu = tf.nn.relu(plus_4)
#block5 conv-bn-relu-conv-bn-relu-plus
conv5_1 = tf.nn.conv2d(plus_4_relu, w5_1, strides=[1, 1, 1, 1], padding="SAME")
conv5_1_relu = tf.nn.relu(conv5_1)
conv5_2 = tf.nn.conv2d(conv5_1_relu, w5_2, strides=[1, 1, 1, 1], padding="SAME")
plus_5 = conv5_2 + plus_4_relu
plus_5_relu = tf.nn.relu(plus_5)
#block6 conv-bn-relu-conv-bn-relu-plus
conv6_1 = tf.nn.conv2d(plus_5_relu, w6_1, strides=[1, 1, 1, 1], padding="SAME")
conv6_1_relu = tf.nn.relu(conv6_1)
conv6_2 = tf.nn.conv2d(conv6_1_relu, w6_2, strides=[1, 1, 1, 1], padding="SAME")
plus_6 = conv6_2 + plus_5_relu
plus_6_relu = tf.nn.relu(plus_6)
#block7 conv-bn-relu-conv-bn-relu-plus
conv7_1 = tf.nn.conv2d(plus_6_relu, w7_1, strides=[1, 1, 1, 1], padding="SAME")
conv7_1_relu = tf.nn.relu(conv7_1)
conv7_2 = tf.nn.conv2d(conv7_1_relu, w7_2, strides=[1, 1, 1, 1], padding="SAME")
plus_7 = conv7_2 + plus_6_relu
plus_7_relu = tf.nn.relu(plus_7)
#block8 conv-bn-relu-conv-bn-relu-plus
conv8_1 = tf.nn.conv2d(plus_7_relu, w8_1, strides=[1, 1, 1, 1], padding="SAME")
conv8_1_relu = tf.nn.relu(conv8_1)
conv8_2 = tf.nn.conv2d(conv8_1_relu, w8_2, strides=[1, 1, 1, 1], padding="SAME")
plus_8 = conv8_2 + plus_7_relu
plus_8_relu = tf.nn.relu(plus_8)
#block9 conv-bn-relu-conv-bn-relu-plus
conv9_1 = tf.nn.conv2d(plus_8_relu, w9_1, strides=[1, 1, 1, 1], padding="SAME")
conv9_1_relu = tf.nn.relu(conv9_1)
conv9_2 = tf.nn.conv2d(conv9_1_relu, w9_2, strides=[1, 1, 1, 1], padding="SAME")
plus_9 = conv9_2 + plus_8_relu
plus_9_relu = tf.nn.relu(plus_9)
#block10 conv-bn-relu-conv-bn-relu-plus
conv10_1 = tf.nn.conv2d(plus_9_relu, w10_1, strides=[1, 1, 1, 1], padding="SAME")
conv10_1_relu = tf.nn.relu(conv10_1)
conv10_2 = tf.nn.conv2d(conv10_1_relu, w10_2, strides=[1, 1, 1, 1], padding="SAME")
plus_10 = conv10_2 + plus_9_relu
plus_10_relu = tf.nn.relu(plus_10)
#after 4 ResNet block, the output is passed to conv11 layer to produce 3 feature map corresponding to input image
conv11 = tf.nn.conv2d(plus_10_relu, w11, strides=[1, 1, 1, 1], padding="SAME")
conv11_relu = tf.nn.tanh(conv11)
return conv11_relu
# discriminator_1-----------------------------------------------------------------
wd1 = tf.Variable(tf.truncated_normal([3, 3, 3, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
wd2 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
wd3 = tf.Variable(tf.truncated_normal([3, 3, 128, 256], mean=0.0, stddev=0.1), dtype=tf.float32)
wd4 = tf.Variable(tf.truncated_normal([3, 3, 256, 256], mean=0.0, stddev=0.1), dtype=tf.float32)
wd5 = tf.Variable(tf.truncated_normal([3, 3, 256, 384], mean=0.0, stddev=0.1), dtype=tf.float32)
wd6 = tf.Variable(tf.truncated_normal([3, 3, 384, 384], mean=0.0, stddev=0.1), dtype=tf.float32)
wd7 = tf.Variable(tf.truncated_normal([3, 3, 384, 384], mean=0.0, stddev=0.1), dtype=tf.float32)
wd8 = tf.Variable(tf.random_normal([28 * 28 * 384, 784], mean=0.0, stddev=0.05), dtype=tf.float32)
def discriminator_1(x):
# layer d1 convolution
conv1 = tf.nn.conv2d(x, wd1, strides=[1, 1, 1, 1], padding="SAME")
conv1_relu = tf.nn.relu(conv1)
# layer d2 convolution and max pooling
conv2 = tf.nn.conv2d(conv1_relu, wd2, strides=[1, 1, 1, 1], padding="SAME")
conv2_relu = tf.nn.relu(conv2)
# layer d3 convolution
conv3 = tf.nn.conv2d(conv2_relu, wd3, strides=[1, 2, 2, 1], padding="SAME")
conv3_relu = tf.nn.relu(conv3)
# layer d4 convolution
conv4 = tf.nn.conv2d(conv3_relu, wd4, strides=[1, 1, 1, 1], padding="SAME")
conv4_relu = tf.nn.relu(conv4)
# layer d5 convolution and max pooling
conv5 = tf.nn.conv2d(conv4_relu, wd5, strides=[1, 2, 2, 1], padding="SAME")
conv5_relu = tf.nn.relu(conv5)
# layer d6 convolution
conv6 = tf.nn.conv2d(conv5_relu, wd6, strides=[1, 1, 1, 1], padding="SAME")
conv6_relu = tf.nn.relu(conv6)
# layer d7 convolution
conv6 = tf.nn.conv2d(conv6_relu, wd7, strides=[1, 2, 2, 1], padding="SAME")
conv7_relu = tf.nn.relu(conv6)
#reshape
conv7_relu_reshape = tf.reshape(conv7_relu, [-1, 28 * 28 * 384])
#layer d8 fully-connected
fc8 = tf.matmul(conv7_relu_reshape, wd8)
#softmax function
fc8_softmax = tf.nn.softmax(fc8)
return fc8_softmax
# discriminator_2-----------------------------------------------------------------
ww1 = tf.Variable(tf.truncated_normal([3, 3, 3, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
ww2 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
ww3 = tf.Variable(tf.truncated_normal([3, 3, 128, 256], mean=0.0, stddev=0.1), dtype=tf.float32)
ww4 = tf.Variable(tf.truncated_normal([3, 3, 256, 256], mean=0.0, stddev=0.1), dtype=tf.float32)
ww5 = tf.Variable(tf.truncated_normal([3, 3, 256, 384], mean=0.0, stddev=0.1), dtype=tf.float32)
ww6 = tf.Variable(tf.truncated_normal([3, 3, 384, 384], mean=0.0, stddev=0.1), dtype=tf.float32)
ww7 = tf.Variable(tf.truncated_normal([3, 3, 384, 384], mean=0.0, stddev=0.1), dtype=tf.float32)
ww8 = tf.Variable(tf.random_normal([28 * 28 * 384, 784], mean=0.0, stddev=0.05), dtype=tf.float32)
ww9 = tf.Variable(tf.random_normal([784, 28 * 28 * 384], mean=0.0, stddev=0.05), dtype=tf.float32)
ww10 = tf.Variable(tf.truncated_normal([3, 3, 384, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
ww11 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
scale11 = tf.Variable(tf.ones([128]))
beta11 = tf.Variable(tf.zeros([128]))
ww12 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
ww13 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
scale13 = tf.Variable(tf.ones([128]))
beta13 = tf.Variable(tf.zeros([128]))
ww14 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
ww15 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=0.1), dtype=tf.float32)
scale15 = tf.Variable(tf.ones([128]))
beta15 = tf.Variable(tf.zeros([128]))
ww16 = tf.Variable(tf.truncated_normal([3, 3, 128, 3], mean=0.0, stddev=0.1), dtype=tf.float32)
def discriminator_2(x):
# layer d1 convolution
conv1 = tf.nn.conv2d(x, ww1, strides=[1, 1, 1, 1], padding="SAME")
conv1_relu = tf.nn.relu(conv1)
# layer d2 convolution and max pooling
conv2 = tf.nn.conv2d(conv1_relu, ww2, strides=[1, 1, 1, 1], padding="SAME")
conv2_relu = tf.nn.relu(conv2)
# layer d3 convolution
conv3 = tf.nn.conv2d(conv2_relu, ww3, strides=[1, 2, 2, 1], padding="SAME")
conv3_relu = tf.nn.relu(conv3)
# layer d4 convolution
conv4 = tf.nn.conv2d(conv3_relu, ww4, strides=[1, 1, 1, 1], padding="SAME")
conv4_relu = tf.nn.relu(conv4)
# layer d5 convolution and max pooling
conv5 = tf.nn.conv2d(conv4_relu, ww5, strides=[1, 2, 2, 1], padding="SAME")
conv5_relu = tf.nn.relu(conv5)
# layer d6 convolution
conv6 = tf.nn.conv2d(conv5_relu, ww6, strides=[1, 1, 1, 1], padding="SAME")
conv6_relu = tf.nn.relu(conv6)
# layer d7 convolution
conv6 = tf.nn.conv2d(conv6_relu, ww7, strides=[1, 2, 2, 1], padding="SAME")
conv7_relu = tf.nn.relu(conv6)
# reshape
conv7_relu_reshape = tf.reshape(conv7_relu, [-1, 28 * 28 * 384])
# layer d8 fully-connected
fc8 = tf.matmul(conv7_relu_reshape, ww8)
#layer d9 fully-connected
fc9 = tf.matmul(fc8, ww9)
#reshape
fc9_reshape = tf.reshape(fc9, [-1, 28, 28, 384])
# layer d10 convolution
conv10 = tf.nn.conv2d(fc9_reshape, ww10, strides=[1, 1, 1, 1], padding="SAME")
conv10_relu = tf.nn.relu(conv10)
#layer d11 deconvolution
batch_size11 = tf.shape(conv10_relu)[0]
deconv11_shape = tf.stack([batch_size11, 56, 56, 3])
deconv11 = tf.nn.conv2d_transpose(conv10_relu, ww11, deconv11_shape, strides=[1, 2, 2, 1], padding='SAME')
deconv11_relu = tf.nn.relu(deconv11)
# layer d12 convolution
conv12 = tf.nn.conv2d(deconv11_relu, ww12, strides=[1, 1, 1, 1], padding="SAME")
conv12_relu = tf.nn.relu(conv12)
#layer d13 deconvolution
batch_size13 = tf.shape(conv12_relu)[0]
deconv13_shape = tf.stack([batch_size13, 112, 112, 3])
deconv13 = tf.nn.conv2d_transpose(conv12_relu, ww13, deconv13_shape, strides=[1, 2, 2, 1], padding='SAME')
deconv13_relu = tf.nn.relu(deconv13)
# layer d14 convolution
conv14 = tf.nn.conv2d(deconv13_relu, ww14, strides=[1, 1, 1, 1], padding="SAME")
conv14_relu = tf.nn.relu(conv14)
#layer d15 deconvolution
batch_size15 = tf.shape(conv14_relu)[0]
deconv15_shape = tf.stack([batch_size15, 224, 224, 3])
deconv15 = tf.nn.conv2d_transpose(conv14_relu, ww15, deconv15_shape, strides=[1, 2, 2, 1], padding='SAME')
deconv15_relu = tf.nn.relu(deconv15)
# layer d16 convolution
conv16 = tf.nn.conv2d(deconv15_relu, ww16, strides=[1, 1, 1, 1], padding="SAME")
conv16_relu = tf.nn.relu(conv16)
output = x - conv16_relu
return output
alpha_ = 0.001
gamma_ = 0.5
lambda_1 = 0.025
lambda_2 = 0.03
lr = 0.00005
kt = tf.Variable(tf.zeros([128]), dtype=tf.float32)
# placeholder
x_ = tf.placeholder(tf.float32, [None, 224, 224, 3]) #synthetic image
y_ = tf.placeholder(tf.float32, [None, 224, 224, 3]) #real image
d_real_p = tf.placeholder(tf.float32, [None, 2]) #target
d_fake_p = tf.placeholder(tf.float32, [None, 2])
# case of real image
out_dis_real_1 = discriminator_1(y_)
out_dis_real_2 = discriminator_2(y_)
loss_ip_real = -tf.reduce_sum(d_real_p * tf.log(out_dis_real_1))
# case of refined image
refined_img = generator(x_)
out_dis_fake_1 = discriminator_1(refined_img)
out_dis_fake_2 = discriminator_2(refined_img)
loss_ip_fake = -tf.reduce_sum(d_fake_p * tf.log(out_dis_fake_1))
loss_adv = kt * out_dis_real_2 - out_dis_fake_2
loss_pp = tf.reduce_mean(x_ - refined_img)
loss_g = - loss_adv + lambda_1 * loss_ip_fake + lambda_2 * loss_pp
loss_d = loss_adv + loss_ip_real
kt = kt + alpha_ * (gamma_ * out_dis_real_2 - out_dis_fake_2)
# train
train_dis = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(loss_d,
var_list=[wd1, wd2, wd3, wd4, wd5, wd6, wd7, wd8
ww1, ww2, ww3, ww4, ww5, ww6, ww7, ww8, ww9, ww10, ww11,
ww12, ww13, ww14, ww15, ww16, scale11, scale13, scale15,
beta11, beta13, beta15])
train_gen = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(loss_g,
var_list=[w0, w1_1, w1_2, w2_1, w2_2, w3_1, w3_2, w4_1, w4_2, w5_1, w5_2,
w6_1, w6_2, w7_1, w7_2, w8_1, w8_2, w9_1, w9_2, w10_1, w10_2, w11])
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# training loop
for epoch in range(0, n_epoch):
for i in range(0, len(data_num), batchsize):
#####################
# make x as np array from real images
# make z as np array from synthetic images
#####################
#make target
d_real = np.array([1.0, 0.0], dtype=np.float32).reshape(1, 2)
d_real_ = np.tile(d_real, (batchsize, 1))
d_fake = np.array([0.0, 1.0], dtype=np.float32).reshape(1, 2)
d_fake_ = np.tile(d_fake, (batchsize, 1))
sess.run(train_gen, feed_dict={x_:x, d_fake_p: d_real_})
sess.run(train_dis, feed_dict={x_:x, y_:y, d_real_p:d_real_, d_fake_p:d_fake_})