はじめに
CVPR2019から以下の論文
[1] K. Sun, et. al. "Deep High-Resolution Representation Learning for Human Pose Estimation" CVPR2019
のまとめ
CVF open access:
https://openaccess.thecvf.com/content_CVPR_2019/papers/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.pdf
公式コード:
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
既に様々な解説が出てるので、ここでは以下の点に焦点を絞ってまとめ。
概要
- 2D のhuman pose estimation系のモデルでtop-down系である
- 高解像度を維持したアーキテクチャーであることが特徴
- 具体的には、高解像度を維持したメインの経路が存在し、それに対して低解像度化した経路を加えている
- これら高解像度の経路と低解像度の経路は何度も繰り返しfusionする
- このようなアーキテクチャによって、COCO dataset、MPⅡ datasetで高い精度を達成した
これまでのアーキテクチャ
以下は(著者らが言うところの)pose estimationなどで用いられる代表的な4つのアーキテクチャ。
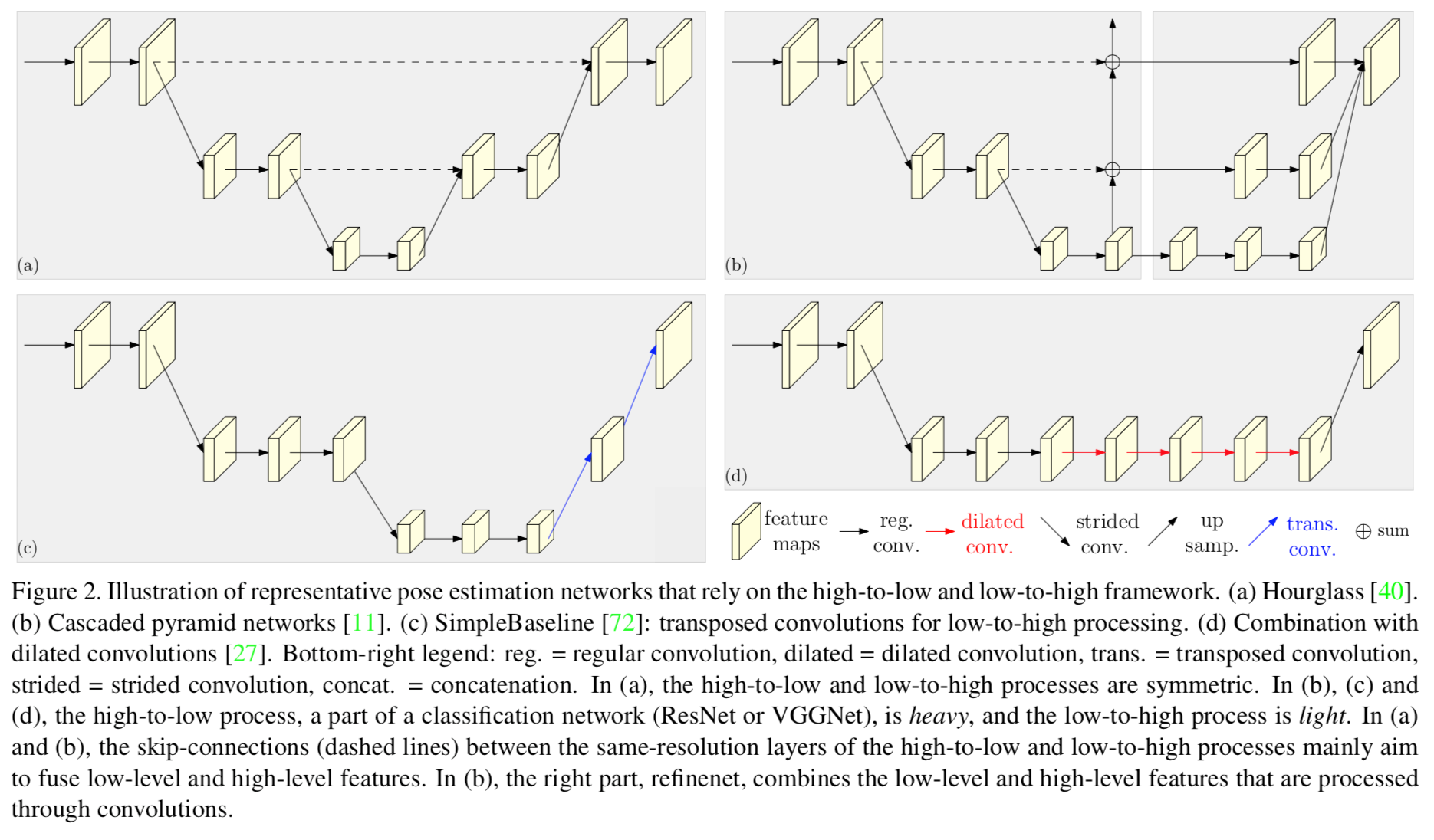
(a) Hourglass系
(a)はHourglass([2])系のアーキテクチャ。
前半でhigh-to-lowで解像度を小さくしながら特徴量を高度化し、後半でその特徴量を高解像度化していく。
前半と後半で対照となっている。途中にskip-connectionが存在。
(b) Cascaded pyramid network系
(b)は[3]等で用いられているCascaded pyramid network系。
前半のhigh-to-lowの部分が巨大で、おおよそImageNetで学習済みResNetのような巨大モデルの一部を用いる。low-to-highは軽め。終盤に複数の解像度の特徴量をconcatする。途中にskip-connectionが存在。
(c) SimpleBaseline系
(c)は[4]で用いられているアーキテクチャ。
(b)と同様high-to-lowが重い。low-to-highはdeconv(transpose conv)を使用。
(d) dilated convを用いる系
(d)は[5]などで用いられているdilated convを用いたアーキテクチャ。
重いhigh-to-lowの後、delated convを用いる。
HRNetのアーキテクチャ
本手法HRNetでは以下の図のように
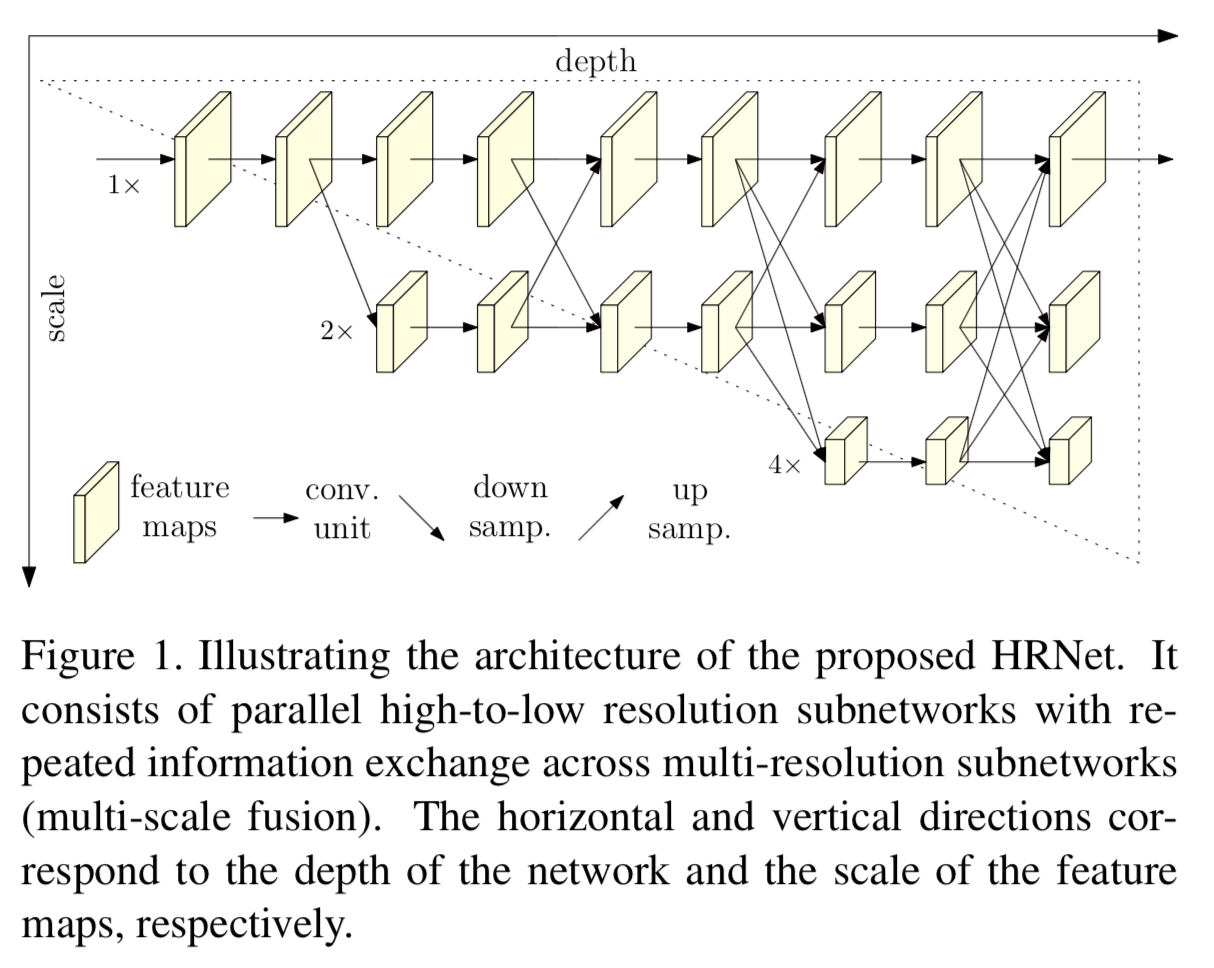
高解像度の経路がまず存在し、それをhigh-to-lowした経路が現れ、それらが平行に進む。さらに途中で何度か異なる経路の特徴量をfusionさせる。
高解像度の経路からみると、低解像度で高度に特徴量かされたものが混じるので、高度な特徴量が高解像度化される効果を期待している。
その他
- top-down系
- heatmapを使う系で、targetはそれのみ
- アーキテクチャ内の各ユニットはResidualなblock
実験と結果
COCO datasetに対する定量的評価
以下はCOCO datasetのtest dataに対する他のモデルとの精度比較表。
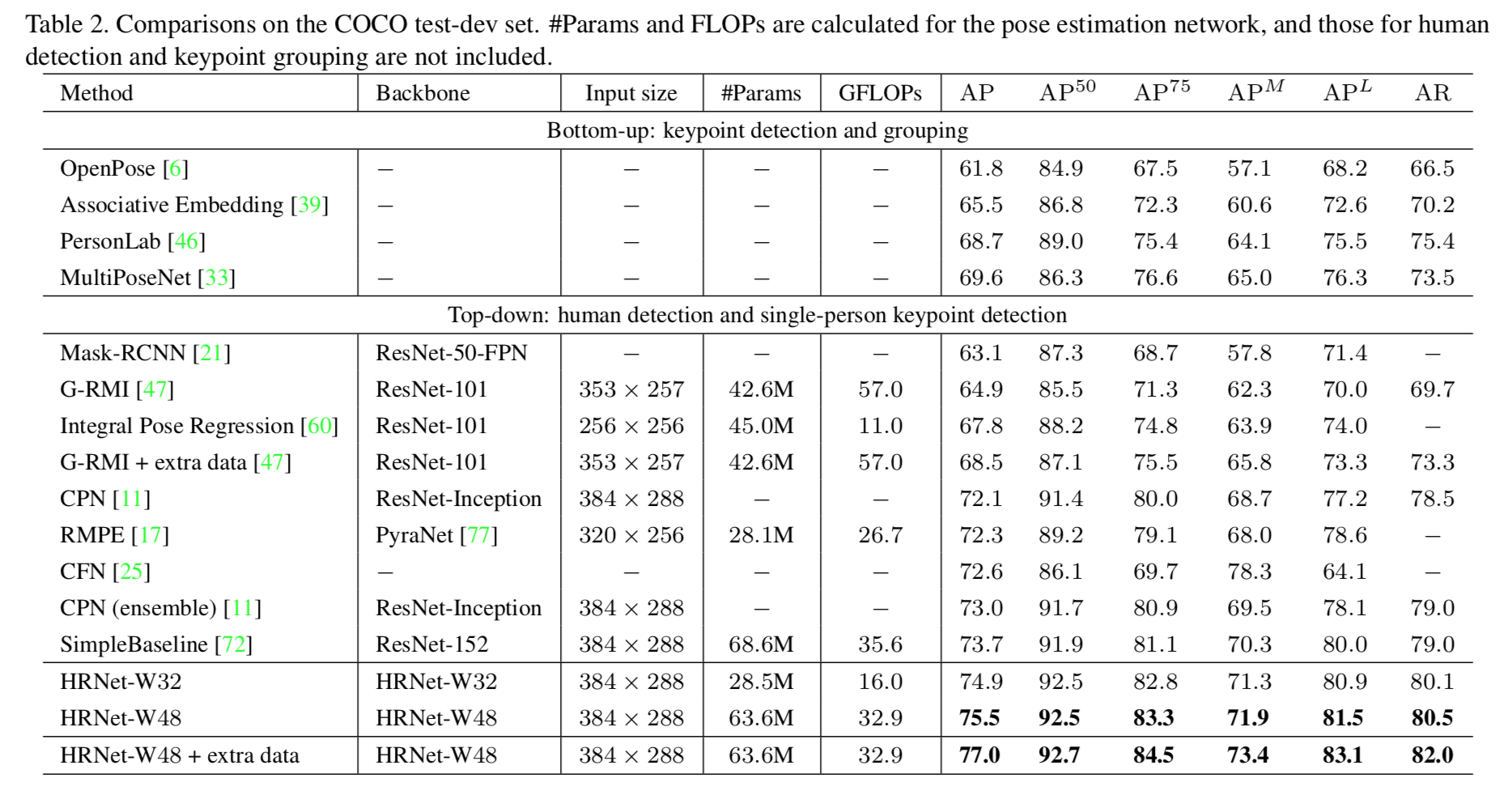
CPNやSimpleBaselineと比較しても精度がよい。
MPII datasetに対する定量的評価
MPII datasetのtest dataに対する他のモデルとの精度比較表。

PCKのtotalでみた場合、[6]と同様に最高精度。
PoseTrack2017に対する定量的評価
PoseTrack 2017 のtest dataに対するmAPとMOTAは以下。
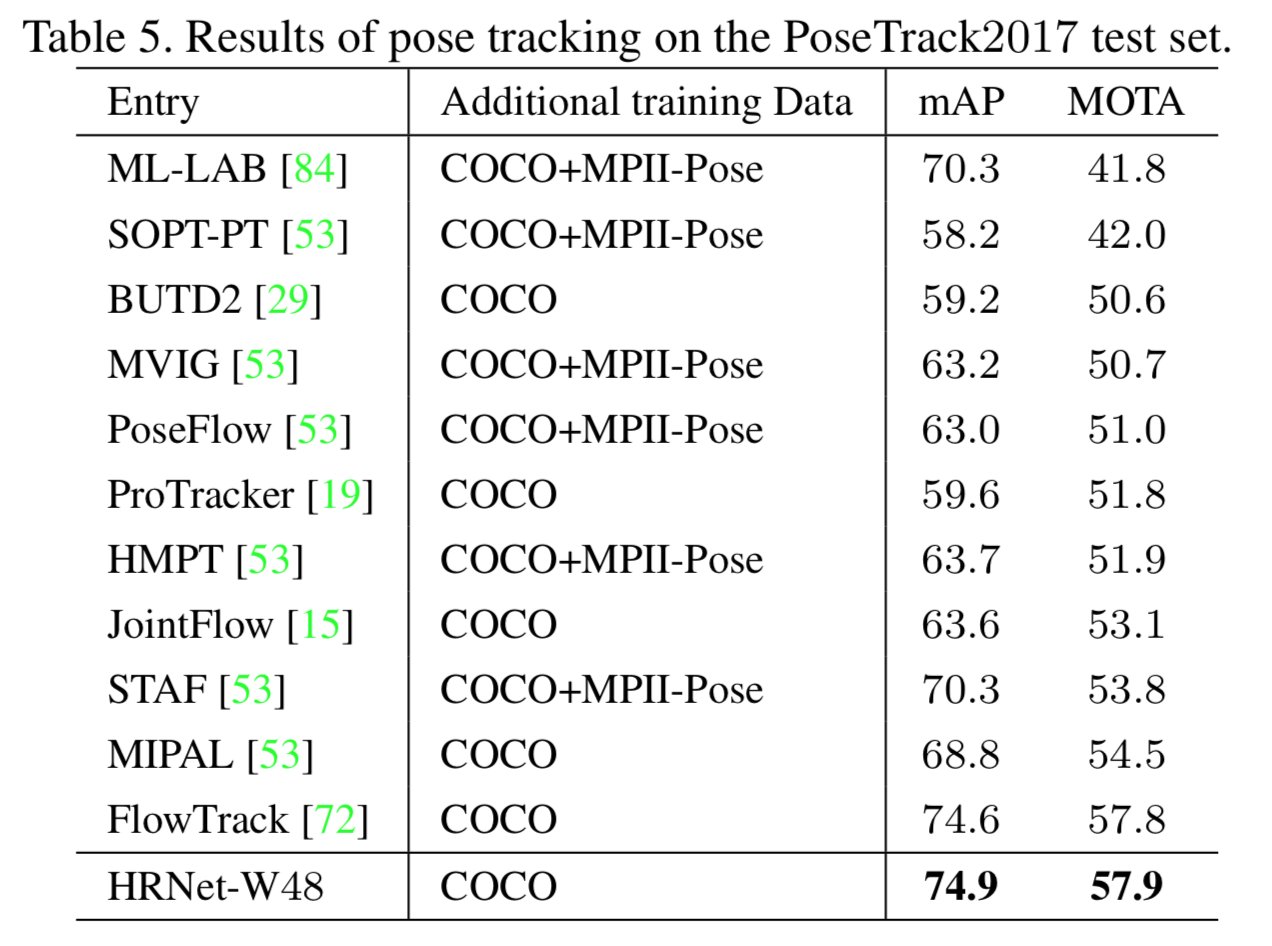
こちらも最高精度。
fusionのablation study
高解像度と低解像度を途中でfusionするmulti-scale fusionの効果を検証。

AP 数パーセントの上昇に寄与している。
入力サイズと精度・速度の関係
以下は入力サイズを変えた場合の精度(AP)と速度(Gflops)の変化
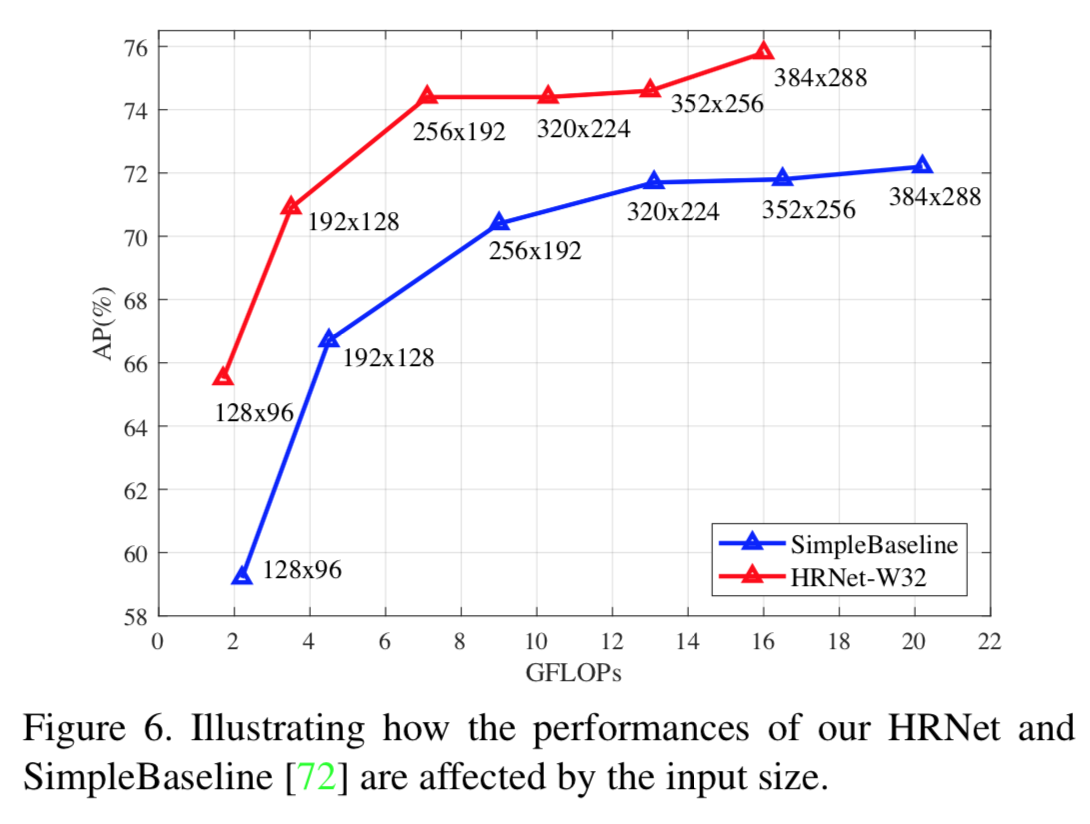
入力サイズを大きくすると当然、速度は低下するが、精度は緩やかに上昇。
256x192あたりで精度がサチッてるので、タスクによってはこのサイズでよいかも。
reference
[2] A. Newell, K. Yang, and J. Deng. Stacked hourglass net- works for human pose estimation. In ECCV, pages 483–499, 2016
[3] Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, and J. Sun. Cascaded pyramid network for multi-person pose estimation. CoRR, abs/1711.07319, 2017
[4] B. Xiao, H. Wu, and Y. Wei. Simple baselines for human pose estimation and tracking. In ECCV, pages 472–487, 2018.
[5] E.Insafutdinov,L.Pishchulin,B.Andres,M.Andriluka,and B. Schiele. Deepercut: A deeper, stronger, and faster multi- person pose estimation model. In ECCV, pages 34–50, 2016.
[6] W. Tang, P. Yu, and Y. Wu. Deeply learned compositional models for human pose estimation.