はじめに
CVPR2018 から 以下の論文
[1] D. C. Luvizon, et. al "2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning", CVPR2018
のまとめ
arXiv:
https://arxiv.org/abs/1802.09232
著者らのコード:
https://github.com/dluvizon/deephar
Keras で実装されてる
現状では日本語でまとめた記事は見当たらない
概要
- 単眼 RGB 画像から 2D、3D の姿勢推定を行うと同時に2D, 3Dの行動推定も行うモデル
- これら全てをend-to-endの学習で行うことで精度を上げる
- そのため Soft-argmax なるものを用いて heatmap から微分可能な方法で peak を取得する
背景
2D 姿勢推定や 3D 姿勢推定は既に高精度のモデルが提案されている。またこの姿勢を利用した行動推定も様々なモデルが提案されている。
しかし、姿勢推定を行ったのちに行動を推定するまで end-to-end で行うモデルはほとんどない。
近年の姿勢推定の多くは heatmap を推定し、その argmax を計算して peak を取得し、それを関節位置とする。その後、この情報を行動推定に利用する。よって argmax を用いる段階で backpropagation できなくなるため、end-to-end な学習はできない。
本手法で用いる Soft-argmax はこれに対する解決策。
全体のアーキテクチャ
全体のアーキテクチャは以下。
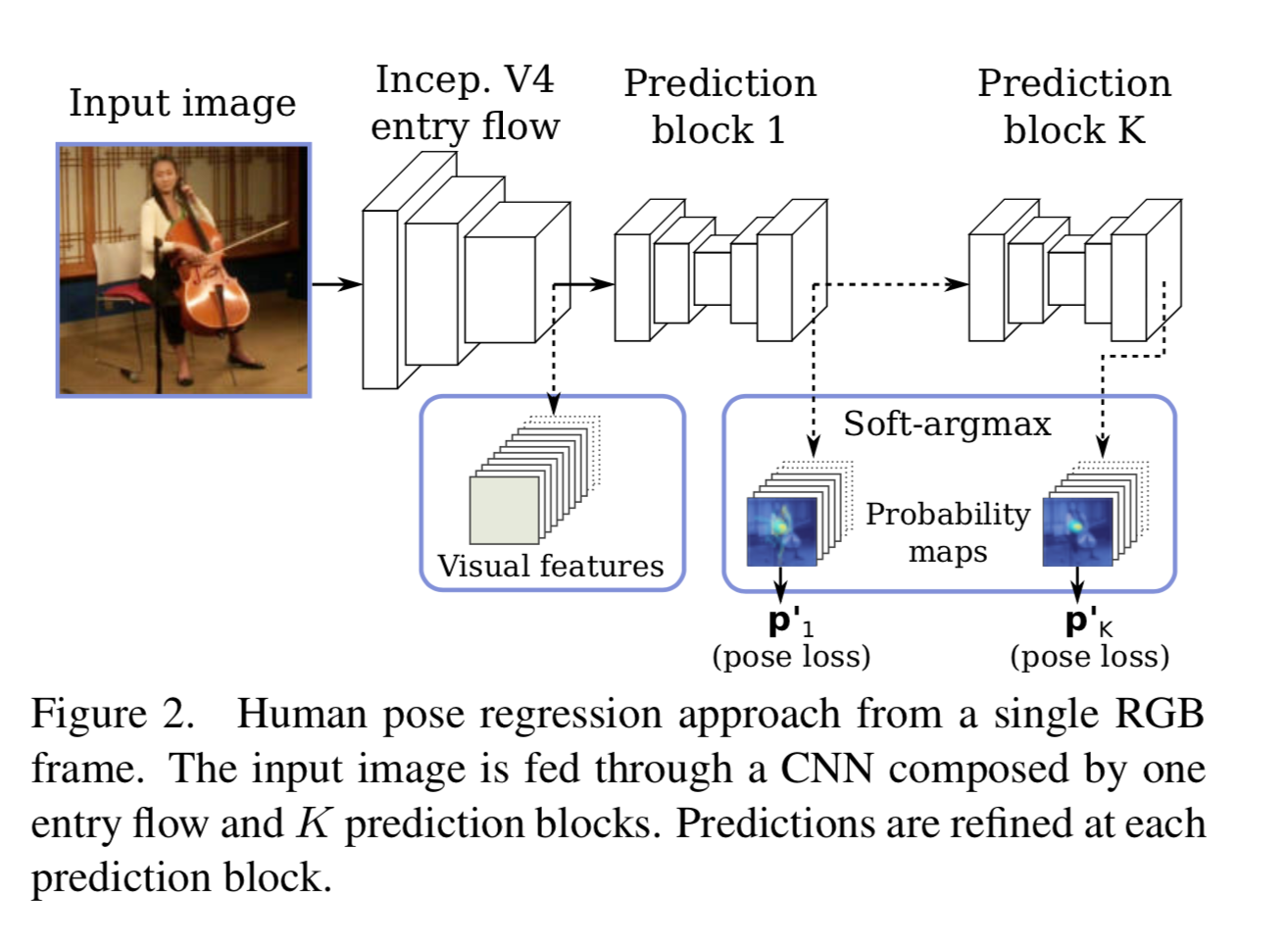
このように人の画像 ${\bf{I}} \in \mathbb{R}^{X \times H \times 3}$ を入力し、 probability map $\hat{P} \in \mathbb{R}^{N_j \times D}$ (heat map に soft-max したもの)を出力する。これに Soft-argmax なるものを作用させて関節位置を出力する。
network としては inception-v4 から feature map を出力し、その後 prediction block を多段にして、それぞれから probability map を出力する。
Soft-argmax なるもの
本手法の核心、Soft-argmax の仕組み。
2D の Soft-argmax
以下が概略図。
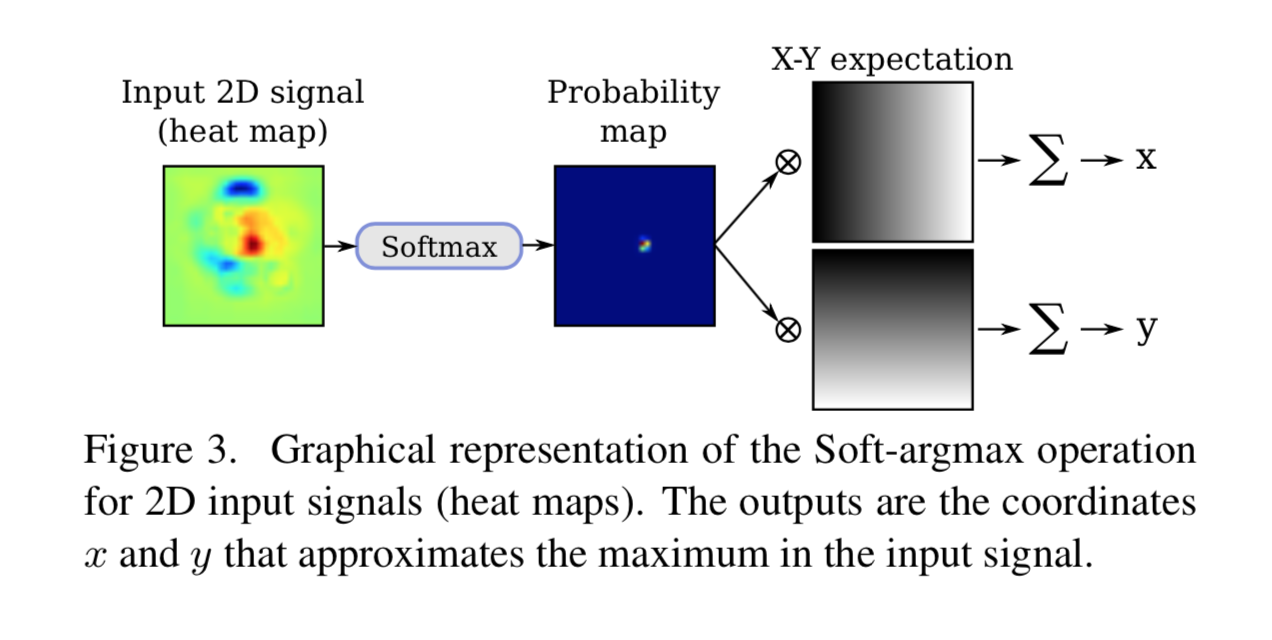
まず、heat map $\bf{x}$ に対し画像の全ピクセルに関する soft-max をかけて probability map $\Phi ({\bf{x}})_{l,c}$ とする。
これに対して、x 軸、及び y 軸の値を持つ画像との Hadamard 積を求め、画像の縦横で足し合わせる。
そうすると、各軸に対して、分布の期待値を求めることになるので、画像上の位置が求まる。
\begin{equation}
\Phi ({\bf{x}} )= \left( \sum^{W_{\bf{x}}}_{c=0} \sum^{H_{\bf{x}}}_{t=0} \frac{c}{W_{\bf{x}}} \Phi ({\bf{x}})_{l,c}, \sum^{W_{\bf{x}}}_{c=0} \sum^{H_{\bf{x}}}_{t=0} \frac{l}{H_{\bf{x}}} \Phi ({\bf{x}})_{l,c} \right)^T \tag{1}
\end{equation}
具体的な値で考える。以下ではわかりやすくするために (1) 式のような相対座標ではなく整数値の座標で表示している。
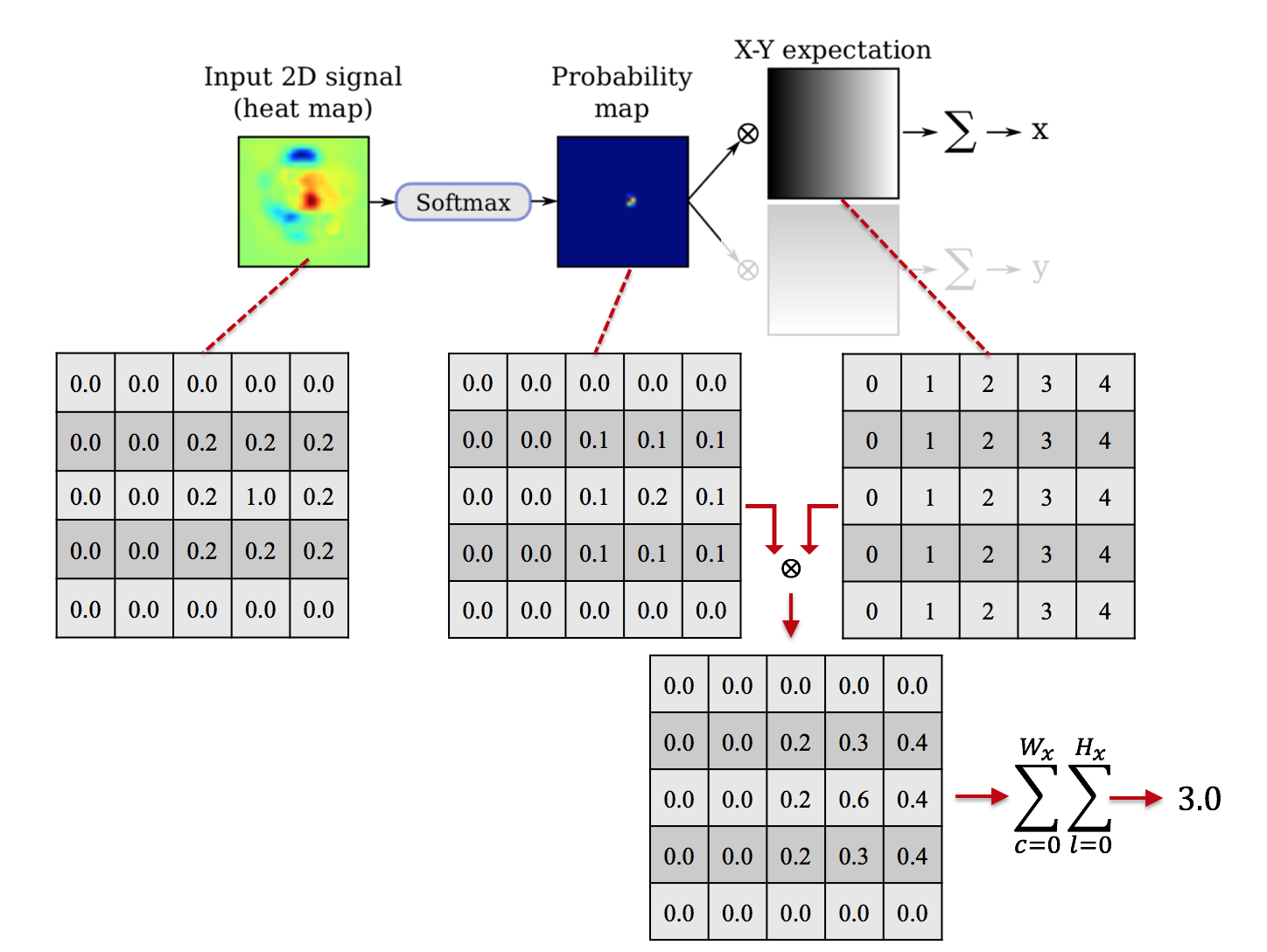
左側のような heatmap に対して、全ピクセルに対して soft-max をとって、その右の probability map になる。
それに対してその右、X軸を刻んだ map を pixel-wise でかけると、その下のようなものになる。
これを全ピクセルに渡って集計すると $3.0$ となる。これが求める $x$ 軸の位置。
$y$ 軸方向に関して同様で、
 右側、$y$ の値を刻んだ map を pixel-wise でかけて、その下のようなものになる。
右側、$y$ の値を刻んだ map を pixel-wise でかけて、その下のようなものになる。
これを全ピクセルに渡って集計すると $2.0$ となり、$y$ 軸の位置が求まる。
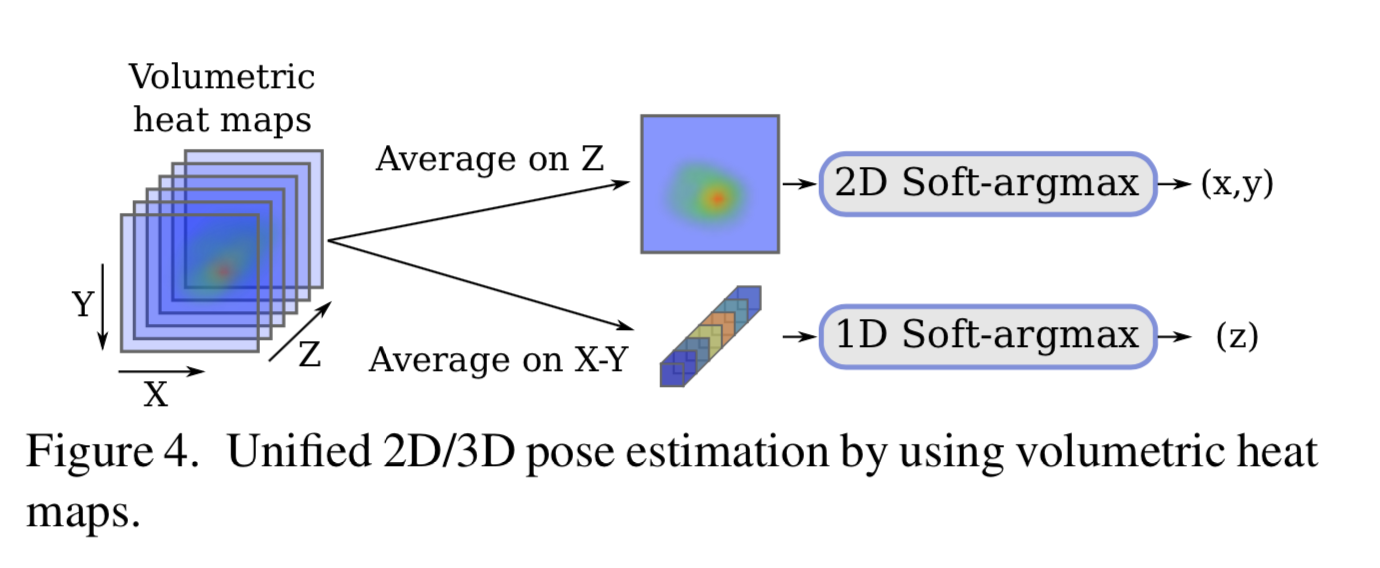
3D の Soft-argmax
3D の場合は voxel に対して同じことをすると思いきや、そうではなく、以下の様に 2D と depthとに分けたのちに、それぞれに対して Soft-argmax を実施する。
行動認識
行動認識まで含めたモデルの全体像は以下。
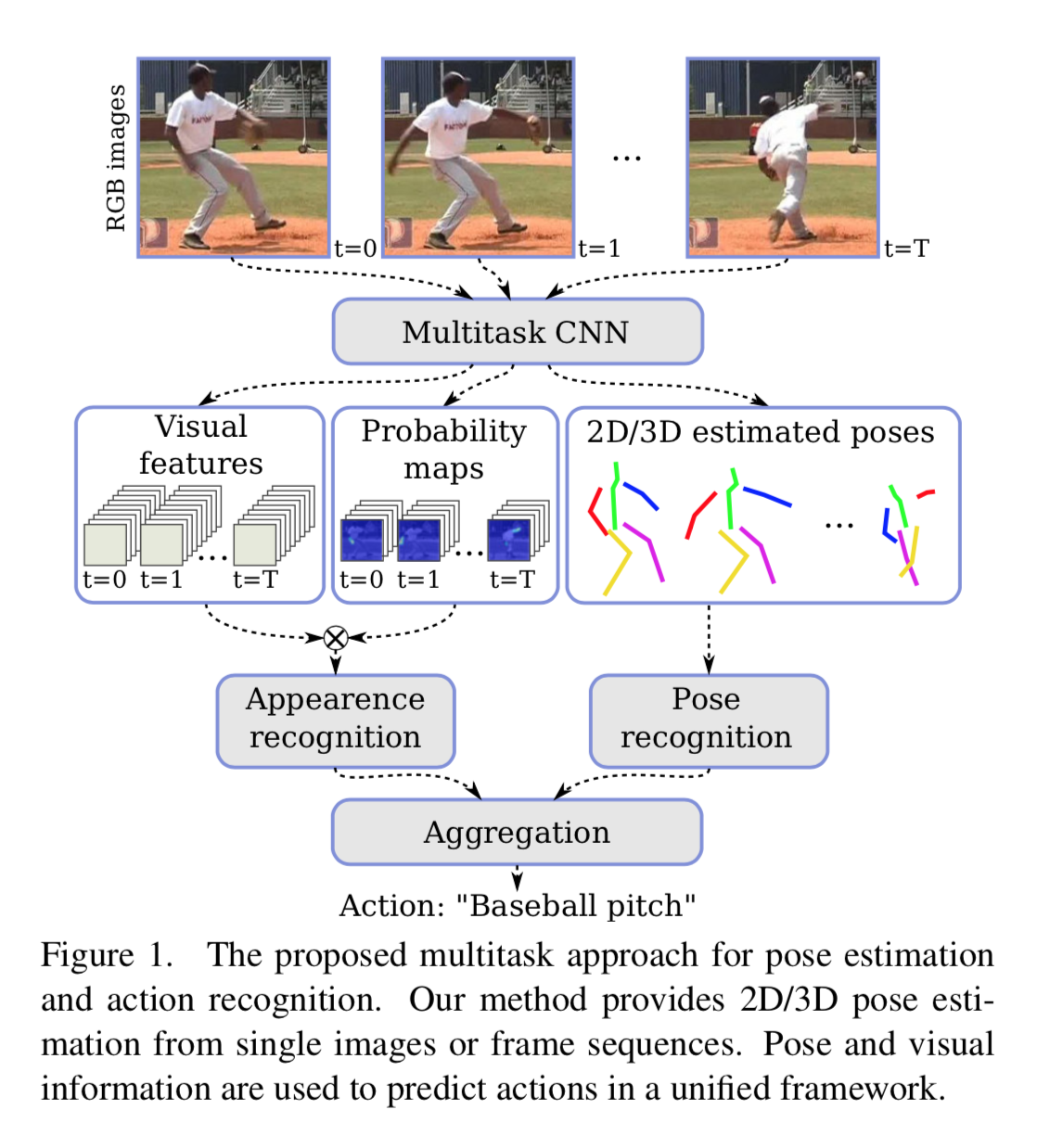
右側は推定した骨格を使って行動認識する流れ。ただ骨格だけだと、例えば耳に受話器を当てて電話をしてるのか、あるいはジュースを飲んでるのかは判別しにくい。
そこで左側の画像の特徴量ベースな流れを作り、行動認識に利用する。
1. pose-based recognition
まずこの部分、
推定した 2D or 3D の骨格から何をしてるのか推定する部分。
ここはこのように
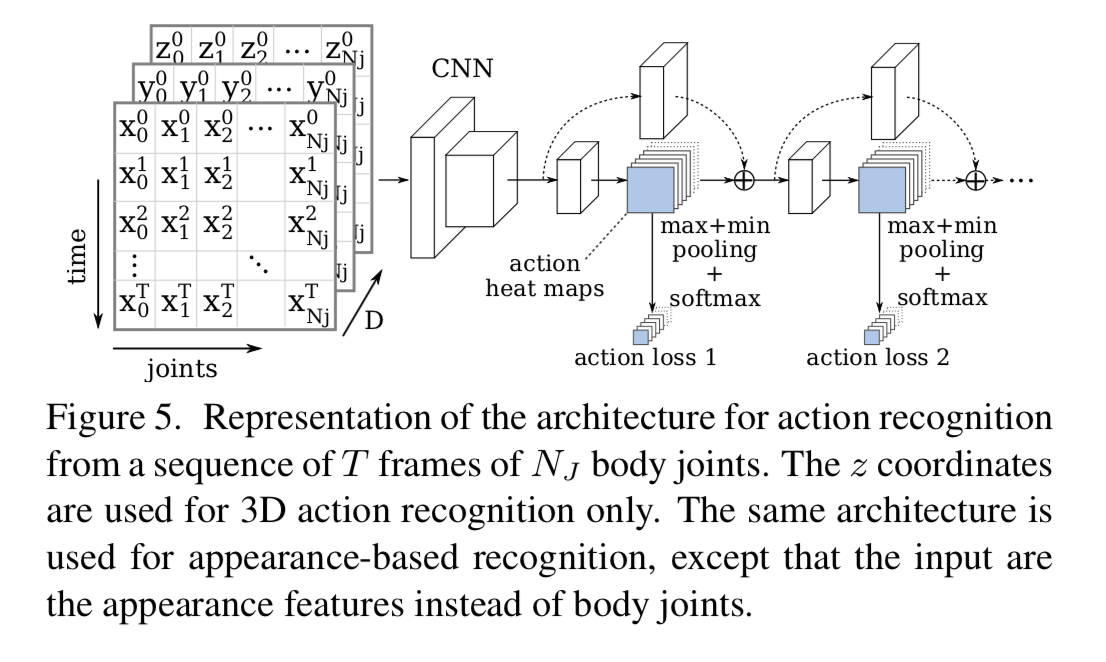
convolutionを使用する。
具体的には横に各関節の座標、縦に時間、チャンネル方向に各軸を取った画像に対して畳み込む。何回か畳み込んだ後に、多段のモジュールで更に畳み込む。
各モジュールからの feature map に対して max pooling と min pooling し、softmaxして出力とする。
2. appearance-based recognition
次にこの部分。

まずvisual features $F_t \in \mathbb{R}^{W_f \times H_f \times N_f}$と probability maps $M_t \in \mathbb{R}^{W_f \times H_f \times N_J}$ とを multiply する。
両者はネットワークのここ
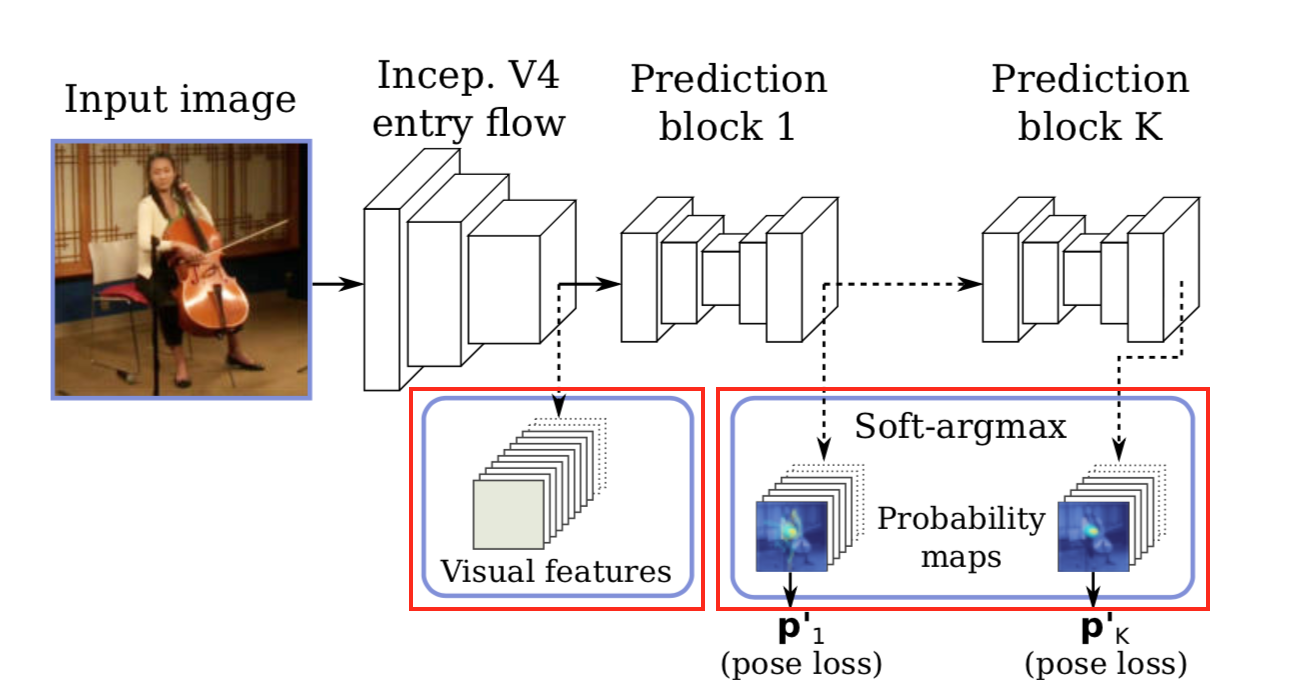
から出力されたもの。つまり visual features は特徴量抽出機である Inception-v4 から出た特徴量であり、 probability maps は heat map に soft-max をかけた各関節の probability を表す map。
これらをチャンネル方向に総当たりで multiply する。なので、特徴量内のあるチャンネル $F_{t, c}$ で考えると、それに対して全ての $M_t$ と multiply された結果、 $N_J$ チャンネルが出力されるが、それぞれのチャンネルは対応する関節付近の特徴量のみ抽出されている。。
この出力に対して画像の縦横に関して合計し、$V_t \in \mathbb{R}^{N_J \times N_f}$ が求まる。実際には時間 t それぞれに対して求めるので、 $V \in \mathbb{R}^{T \times N_J \times N_f}$ となる。
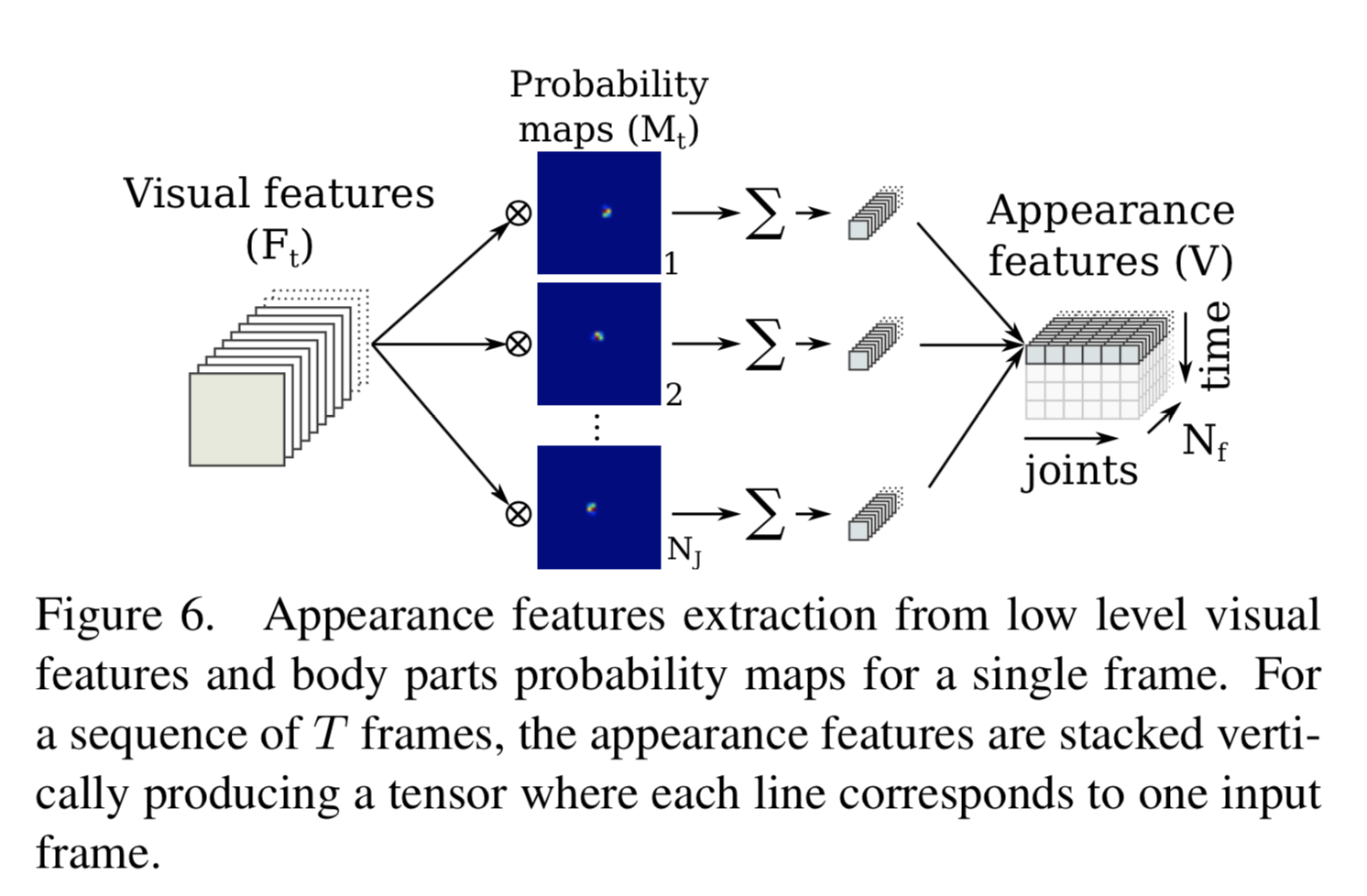
この $V$ に対して、上図の最右のように横方向に $N_j$ 、縦方向に時間、チャンネル方向に $N_f$ と結合させ、テンソルとする。この並びは pose-based recognition からの出力に一致している。
3. Action aggregation
せっかくテンソルの軸を揃えたが、最後は全結合で両者(pose-based recognition と appearance-based recogtion)を結合するみたい。
loss
1. pose estimation タスクのロス
以下の elastic net loss。
L_{\bf{p}} = \frac{1}{N_J} \sum^{N_J}_{n=1} ( \| \hat{{\bf p}_n} - {\bf p}_n\|_1 + \| \hat{{\bf p}_n} - {\bf p}_n\|_2^2)
${\bf p}_n$ はground truthの第 $n$ 関節座標で、$\hat{{\bf p}_n}$ はそのprediction。
2. action recognition の loss。
分類タスクなので交差エントロピー。
実験の概要
1. 用いるデータセット
- MP2 Human Pose Dataset
- Human 3.6M
- Penn Action
- NTU RGB+D・・・3D action recognition 用
2. メトリクス
- 2D pose estimation・・・PCKh, AUC
- 3D pose estimation・・・MPJPE(mean per joint position error)
- 2D action recognition・・・Accuracy
- 3D action recognition・・・Accuracy
実験の結果
1. MP2 dataset を用いた 2D pose estimationの実験結果
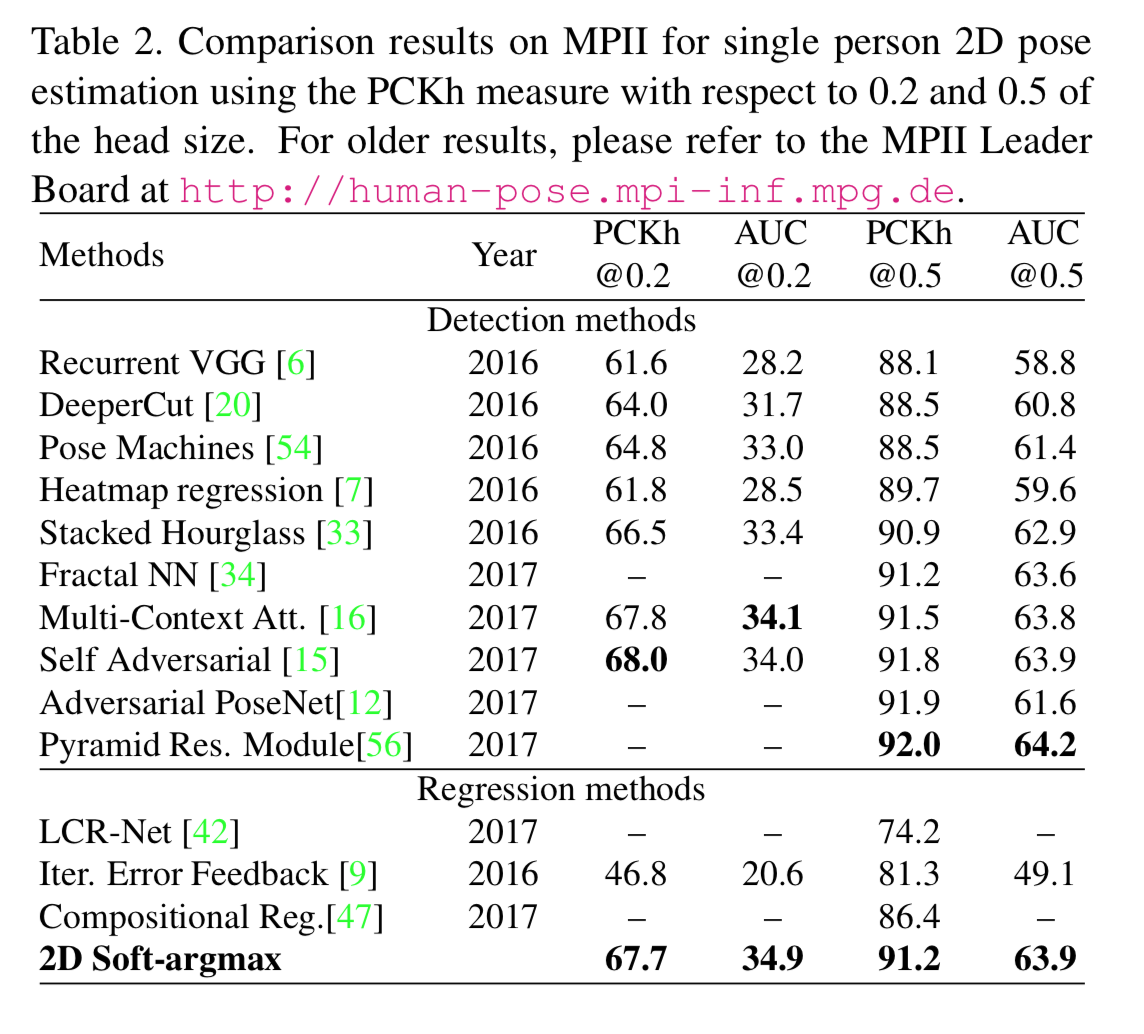
他の手法と比べてまぁまぁいい。
2. Human 3.6M dataset を用いた 3D pose estimationの実験結果
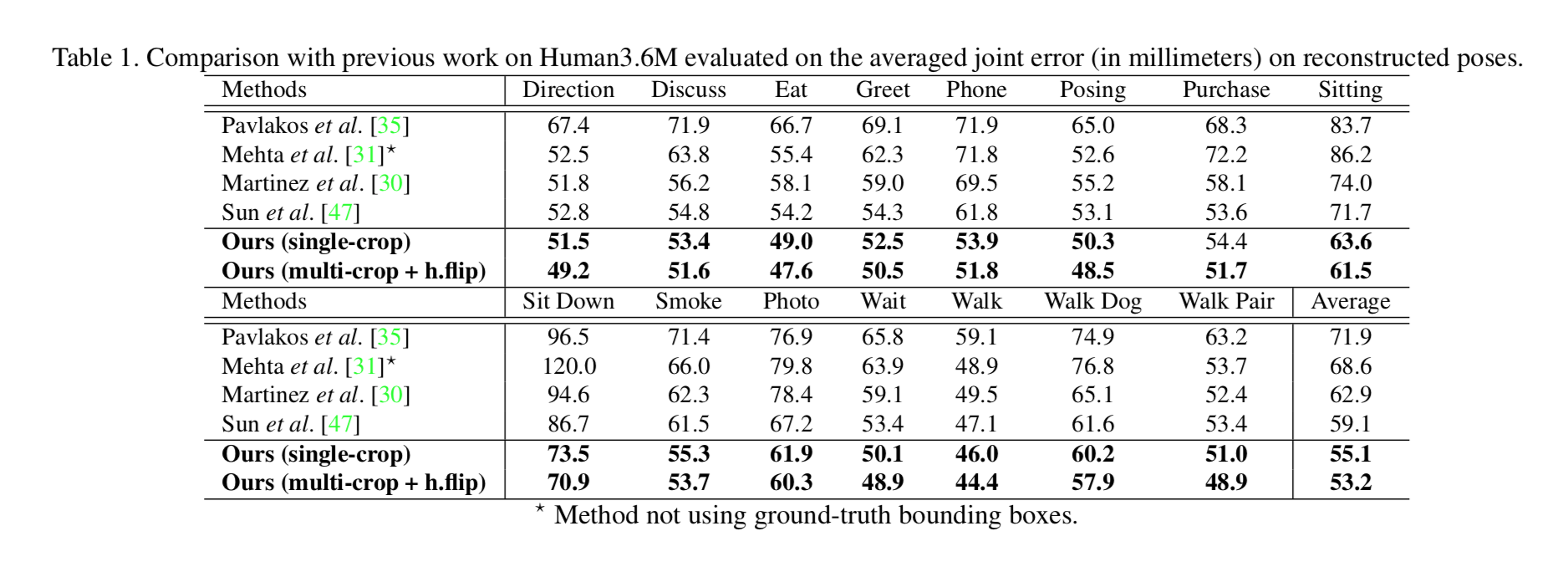
他の手法より軒並みよい。
3. MP2 dataset を用いた2D action recognition の実験結果
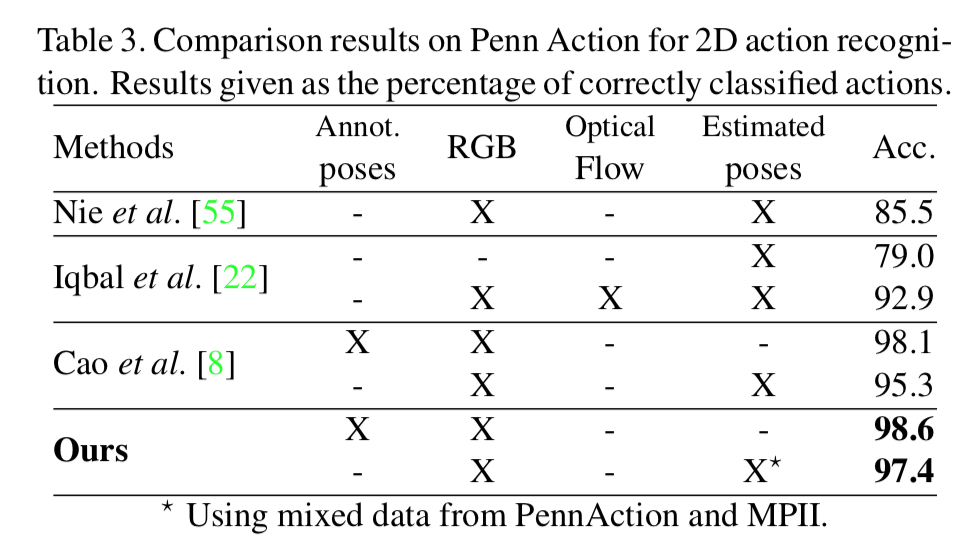
これもよい。
4. NTU for 3D dataset を用いた 3D action recognition の実験結果
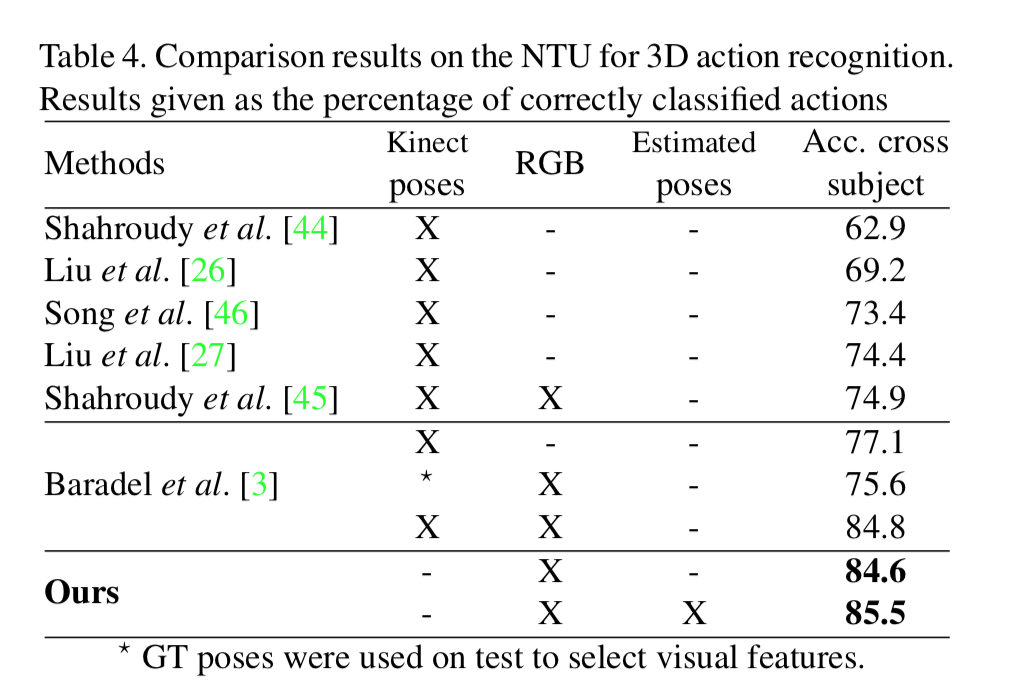
kinect のdepth情報を使ってなくても結構よい。
5. ablation study
action recognition における各要素の効果は以下。
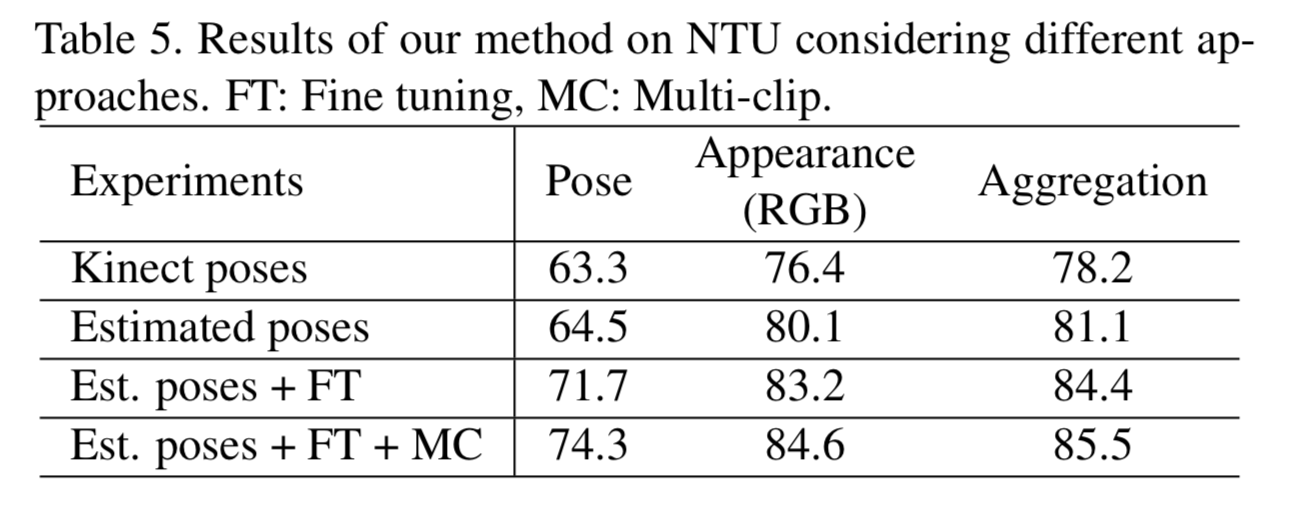
例えば、上から2行目の Estimated poses に注目すると、estimatied pose(pose-based recognition) の流れだけだと 64.5、それに Appearance RGB (appearance-based recognition)の流れが加わると80.1、両者の結合だと81.1。
pose-based recognition の効果はイマイチな気がする。
個人的な感想
骨格推定から行動推定まで end-to-end な学習を行うため導入した Soft-argmax なるものは、面白いと思う。
しかし、あくまで1画面に1個人のみ写ってる場合でないと変な値になるはずなので、前処理の段階で画像から1人の領域を切り抜けるかが重要。
また1個人のみが写っていても、例えば人を前から写したものか、後ろから写したものか分かりにくい場合、右肩のprobability mapのpeakは2箇所に分散し、Soft-argmaxをかけるとその中間の首あたりの座標が出力されてしまうだろう。
なので、人の写りが悪い場合は不向きな手法と思われる。
peak が複数ある場合に、複数の座標が微分可能な形で求まるような手法があれば面白いが。。。