はじめに
来月開催されるCVPR2018のHP内、main conference
http://cvpr2018.thecvf.com/program/main_conference
の中にsegmentation関係の論文があったので、arXivで検索して読んでみた。
[1]C. Yuらの「Learning a Discriminative Feature Network for Semantic Segmentation」
https://arxiv.org/abs/1804.09337
概要
semantic segmentationは以下2つの問題を抱えている。
1)intra-class inconsistency
同じクラスの物体なのに違うクラスの物体と判断してしまう問題
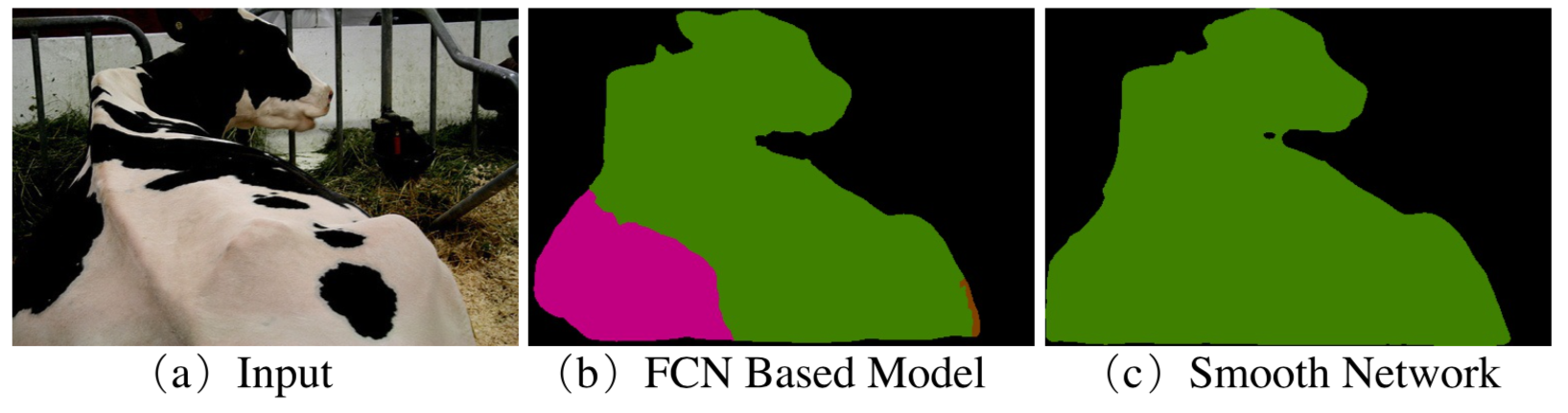
[1]のFigure 1より
この図の(b)において、左下の領域は同じ牛(緑)の一部にも関わらず、馬(ピンク)と認識されている。
2)inter-class indistinction
異なるクラス間の物体を同じクラスと判断してしまう問題
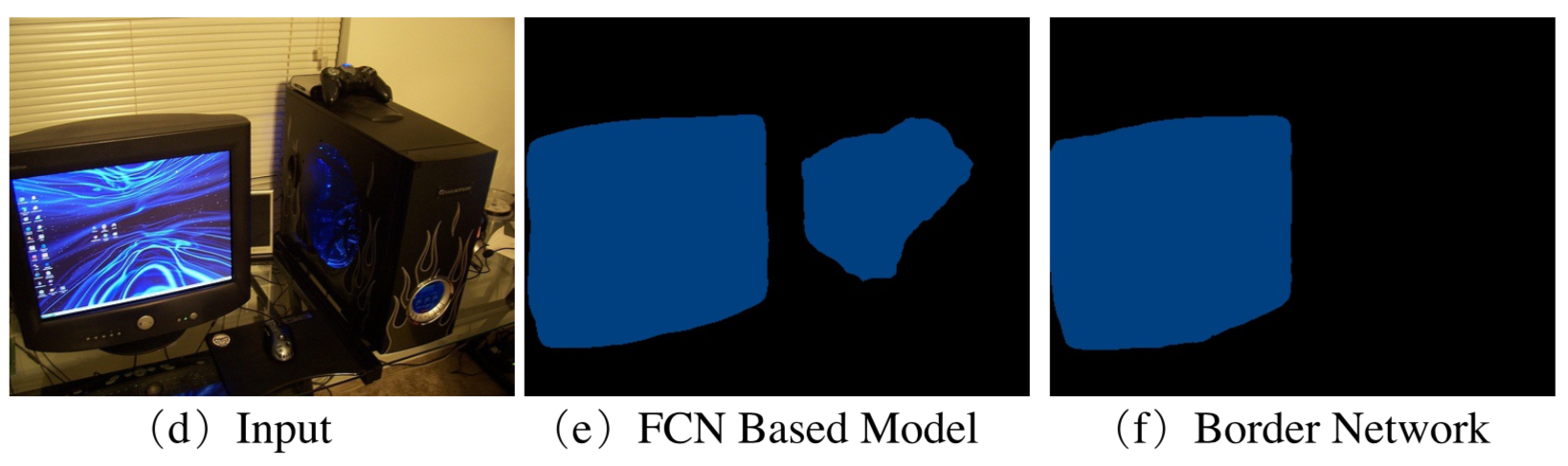
[1]のFigure 1より
この図の(e)においてパソコンの本体がTV-monitorと認識されている。
作成したモデル
上記2つの問題に対応するため Discriminative Feature Network というものを作った。具体的には以下の2つを含むモデル。
1)intra-class inconsistency の対応策として Smooth Network。
2)inter-class indistinction の対応策として Border Network。
アーキテクチャ
全体像
全体像はこんな感じ。
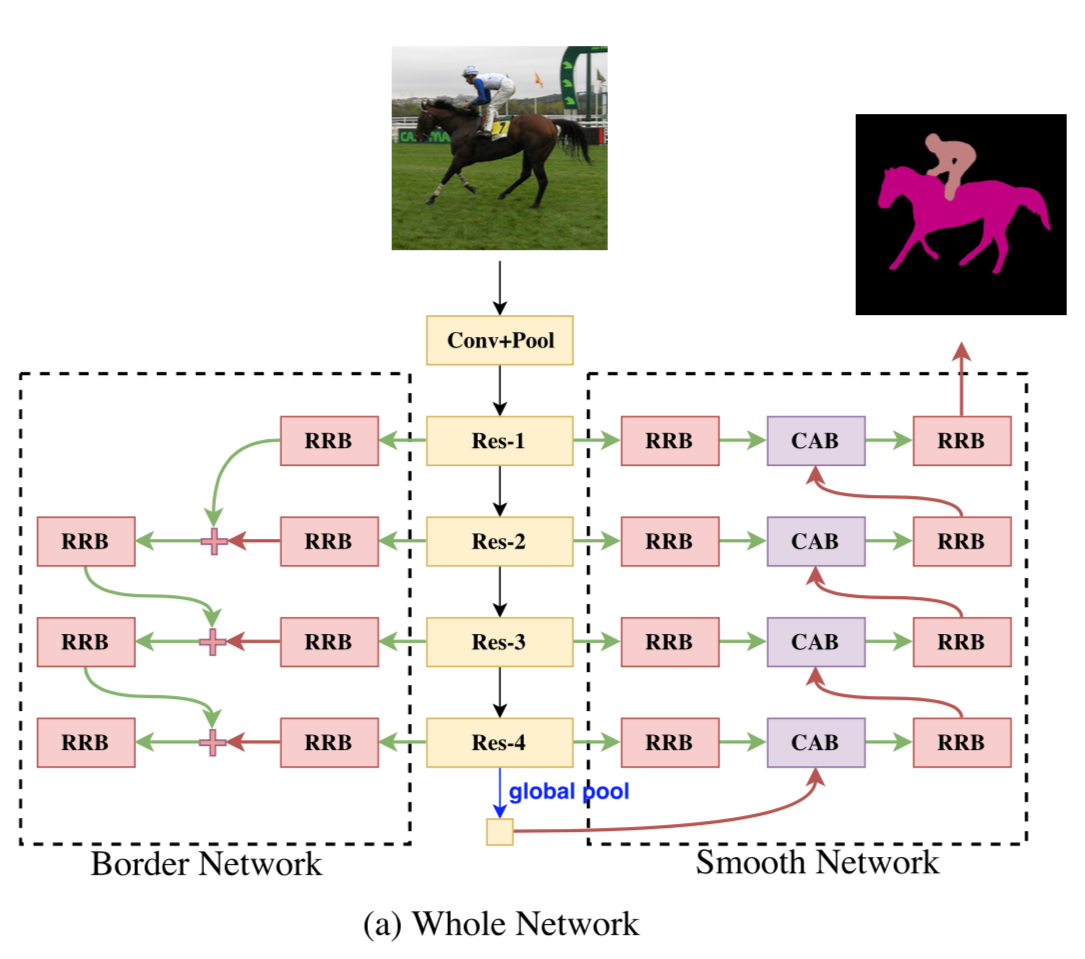
[1]のFigure 2より
このうち、以下の青い矢印部分に注目すると、
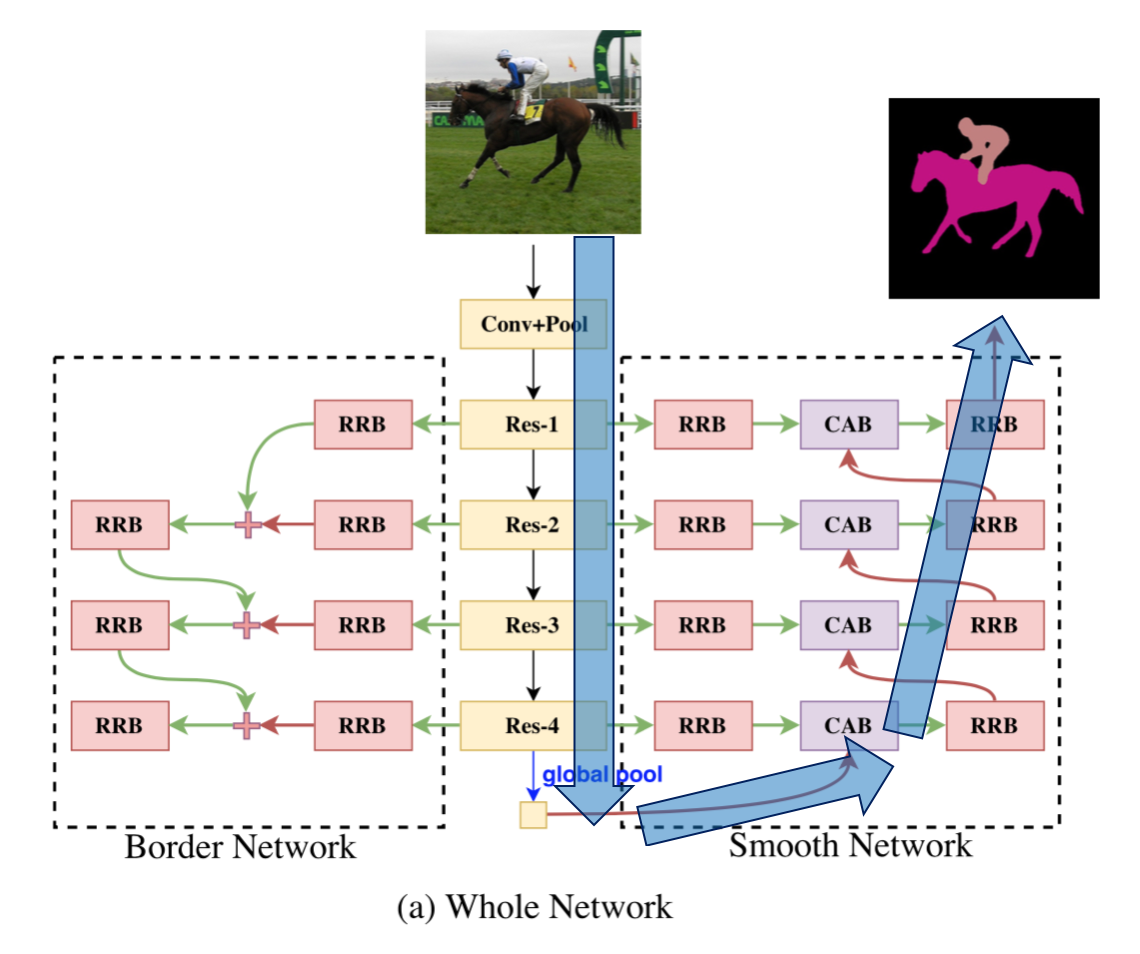
encorde して decordeしてる。それに対してshort cutの経路があるので U-Net等の構造に似ている。
RRB(Refinement Residual Block)ブロック
この中でRRBと書かれてるブロックは以下。
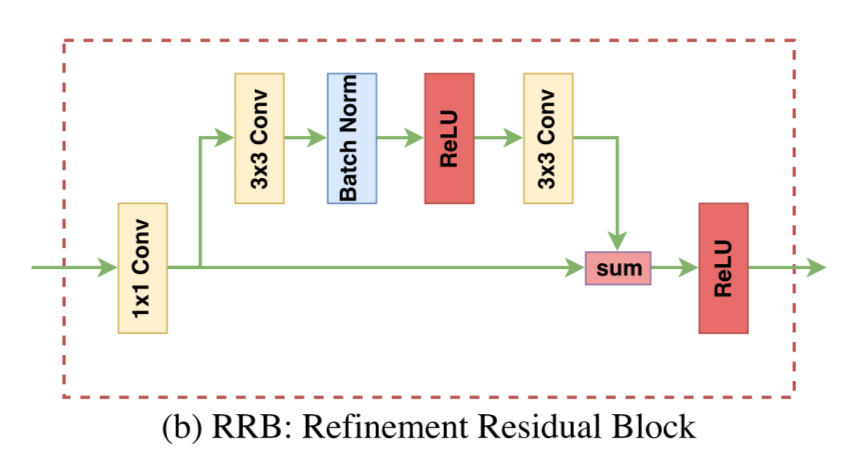
はじめに1x1 convで畳み込む。それを二手に分け、下側の経路ではそのまま流し、上側の経路では3x3conv、BN、Relu、3x3 convで特徴量化。両者を足してReluする。
element wiseで足すのでResNetのResidual Blockのように上側の経路が残差となる。これがより高次の特徴量で、下側の経路は位置的な情報か?
CAB(Channel Attention Block)ブロック
CABと書かれたブロックは以下。
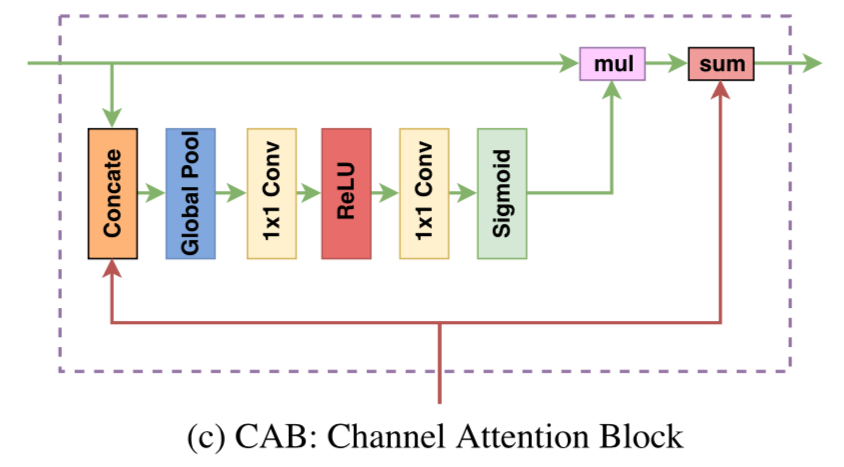
下からより高層から来た広範囲でより高次元なcontextを持ったfeature mapが上がってくる。それが2手に別れて、右側の経路は低層からの情報をelement wiseで足す。
この時に足されたいのは低層のcontextではなく、位置的な情報。よってcontexは崩さないように前の層の情報を変換したい。
その変換するためのユニットが中央のAttention経路。ここで低層と高層の情報をconcatenateしてglobal average poolingでベクトル化し、1x1 conv、relu、1x1 convして、最後はsigmoidをかけて[0,1]の値とする。
これを低層の情報にかけることで、低層のcontextを高層のようなcontextに変換する。
以下はCABの模式図。
Smooth Network
上記全体図の右側。intra-class inconsistencyに対応。U-Net等との比較で述べるとCABにより低い層のcontextが変換されてるので、高い層のcontextが生かされる。
よってより高次でより広範囲な特徴を拾うことができる。
これにより「同じ牛なのに一部が馬」という状況が改善されると期待される。
Boarder Network
上記全体図の左側。inter-class indistinctionに対応。ここの仕組みは次章のfocal lossを使用することでclassとclassとのboarder付近をより明確に判断できるようになる。
Focal Loss
Boarder Networkからの出力に対して以下のlossで学習させる。
FL(p_k) = -(1 - p_k)^\gamma \log{p_k}
$\gamma$が0の時は通常の交差エントロピーとなる。なので交差エントロピーをより一般化したものと考えることもできる。
このlossは以下の論文が元ネタのよう。
[2] T. Lin, et. al"Focal Loss for Dense Object Detection"
https://arxiv.org/abs/1708.02002
このloss関数がどのような形状かはわかりづらいが、論文[2]中のグラフを拝借すると以下のよう。
 [2]のFigure 1より
[2]のFigure 1より
結局$(1-p_k)$より対数部分が効いてきて交差エントロピーのようにはなるが、漸近の仕方が異なる。
$\gamma = 0$の交差エントロピーから$\gamma$を増していけば、値が小さくなる。特に図中のwell-classified examplesと書かれた部分が顕著。
つまりこのfocal lossを使うことで、既に識別性能が得られたピクセル(つまり物体の中央付近?)に関しては効いてこず、識別性能が低いピクセル(つまりボーター付近)に対して効いてくる。
Loss
Loss全体としては、上記のfocal lossに加えて通常の交差エントロピーとなる。
\begin{eqnarray}
l_s &=& SoftmaxLoss(h;w) \\
l_b &=& FocalLoss(y;w) \\
L &=& l_s + \lambda l_b
\end{eqnarray}
focal lossに対する掛け率 $\lambda$ は 0.1 など使う。
実験と結果
使ったデータセット
定番のPascal VOCやCityscapesで実験している。
ベースにしたアーキテクチャ
ImageNetで学習したResNet-101がベース。FCN4のフレームワークを使ってる。
データ水増し
- subtraction
- horizontal flip
- randomly scaling ・・・(0.5倍、0.75倍、1倍、1.5倍、1.75倍)
GAP使ってるのでランダムスケーリングが可能。
各要素の効果
1. random scaleの効果
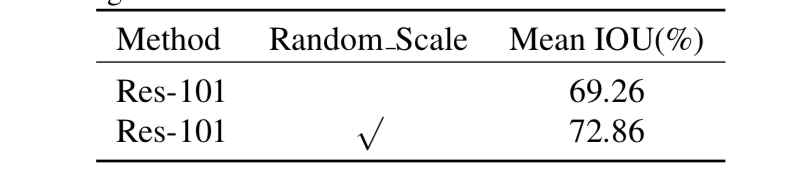 [1]Table 1より
結構効いてる。これを可能とするGAPを含めて効果あり。
[1]Table 1より
結構効いてる。これを可能とするGAPを含めて効果あり。
2. RRB、GP、CAB、DSの効果
以下4つ
- RRB:refinement residual block
- GP:global pooling branch
- CAB:channel attention block
- DS:deep supervision
の効果
 RRBの効果が大きい。CABの効果は1%くらい
RRBの効果が大きい。CABの効果は1%くらい
3. border networkの効果
 border networkの効果は微妙w。
border networkの効果は微妙w。
4. 各層(stage)からの出力画像
 [1]Figure 7より
一番左がground truth。その右が低層(stage 1)からの出力。右に行くほど高層を経た出力。
[1]Figure 7より
一番左がground truth。その右が低層(stage 1)からの出力。右に行くほど高層を経た出力。
高層にいくほどより全体のcontextを捉えて精度が上がってる。boarderも低層では物体全体というよりは物体のパーツをborderと捉えているが、高層では1つの物体(class)のborderを鮮明に認識している。
他のモデルとの比較
pascal VOCでの比較
 DeepLabv3+にも勝ってる。へぇ〜、って感じ。
DeepLabv3+にも勝ってる。へぇ〜、って感じ。
Cityscapesでの比較
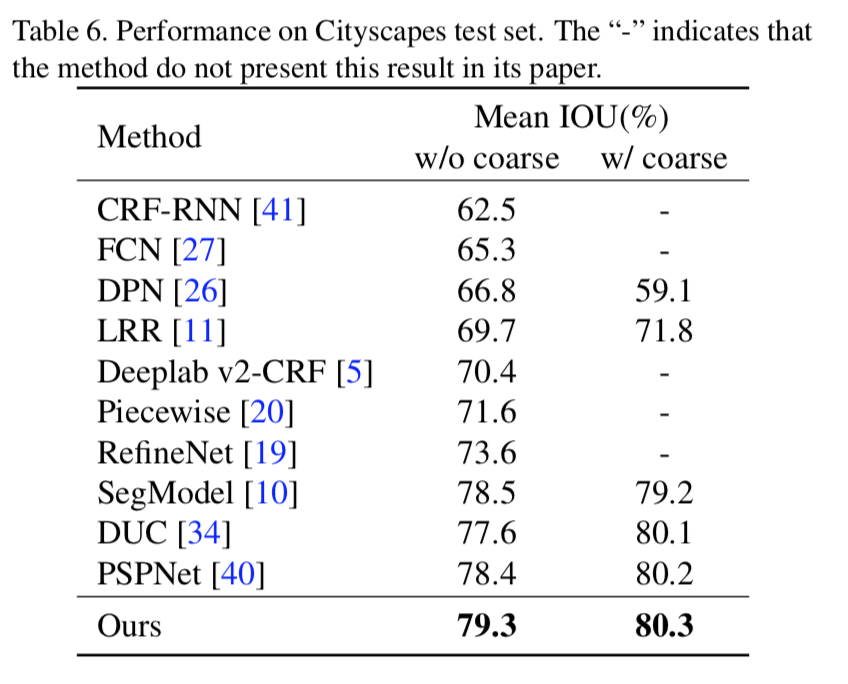 これも微妙にPSPNetを上回ってる。DeepLabv3+は??
これも微妙にPSPNetを上回ってる。DeepLabv3+は??
出力画像例
 いいとこ取りした可能性はあるが、かなり鮮明に細いところまでsegmentationできてる。
いいとこ取りした可能性はあるが、かなり鮮明に細いところまでsegmentationできてる。
結論
今回提案したDFN(Discriminative Feature Network)はSmooth NetworkとBorder Networkという2つを導入することでいい精度が出た。
個人的感想
Smooth Networkは精度の向上に大いに貢献しているが、Border Networkは1%程度の精度上昇と、頑張った割には効果が低い。
ただ僅差のstate-of-the-artなので、1番取るための最後の1押しとしては絶大な効果、とも言えるね。
ただ半年後にDeepLabv4とか出たら駆逐されそうw。