はじめに
CCV2019より以下の論文
[1] A. Gordon, et. al. "Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras" ICCV2019.
のまとめ、その(2)
その(1)はこちら
https://qiita.com/masataka46/items/a509381657b98adc6036
ここではオクルージョン対応、ネットワーク、ロス、実験結果について。
物体のオクルージョン対応
この論文の特徴の1つ。
以下の図のようにカメラ位置の変化によりオクルージョンが発生する。
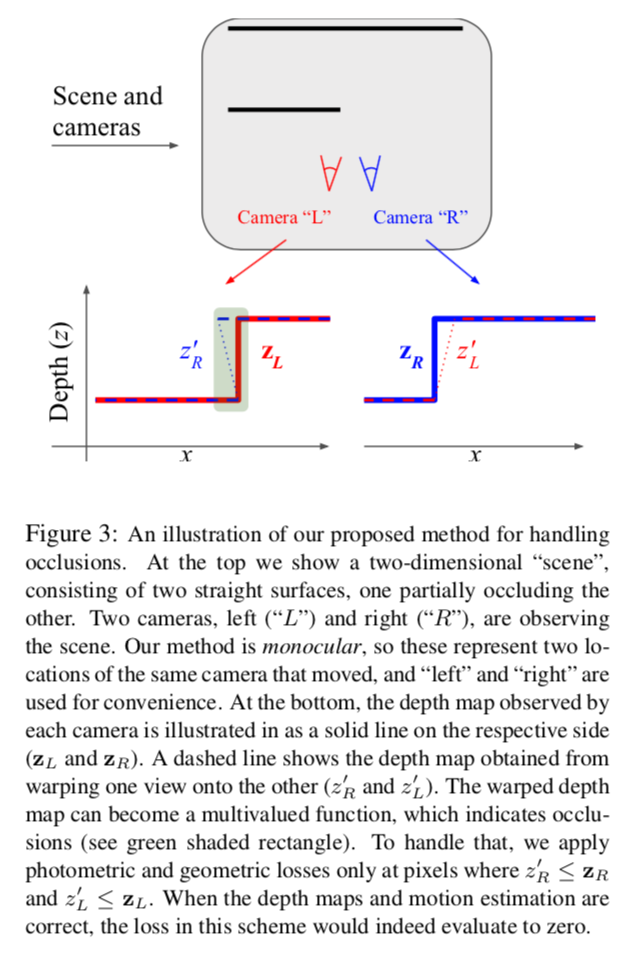
図の上で2つの物体(線)をカメラから見てる。赤が左位置のカメラから見た場合、青は右位置のカメラから見た場合。下の図は各視点から物体を見た場合のdepth map。
例えば左カメラから物体を見ると、depth mapは左下の赤の実線($z_L$)のようになるだろう。
一方で右カメラから物体を見ると、depth mapは右下の青の実線($z_R$)のようになるだろう。ここで注意点は、左カメラから見た場合に隠れていた奥の物体の一部が右カメラでは見える点。
右カメラのdepth mapをtransformすると、左下図の青い点線($z_R'$)となるだろう。右カメラから余分に見えていた部分は緑の領域のように手前の部分と奥の部分で重なってしまう。つまり奥の物体の一部がオクルージョンしている。
この状況に対応するため、lossの際には $z_R' < z_R$ とする。そうすると緑の領域が弾かれる。
ネットワークのアーキテクチャ
ネットワークは
- 単眼RGB画像からdepthを推定するもの
- 2枚の隣接するRGB画像からカメラの外部パラメータ、内部パラメータ、物体の動きを推定するもの
の2つ。
1) depthを推定するネットワーク
ResNetのblock18個からなるUNet構造。最後の活性化関数はsoftplus。
2) カメラ内部・外部パラメータや物体の動きを推定するネットワーク
FlowNet([2])のようなUNet構造。
loss
- depth に関しては occulusion aware な上記のオクルージョン対応したもの) L1
- 移動物体に関しては occulusion aware な cycle consistency を用いる
- SSIM も使うがオクルージョン対応で修正している
実験と結果
定量的評価
KITTI datasetを用いた場合のdepthの各メトリクス類の他モデルとの評価値は以下。
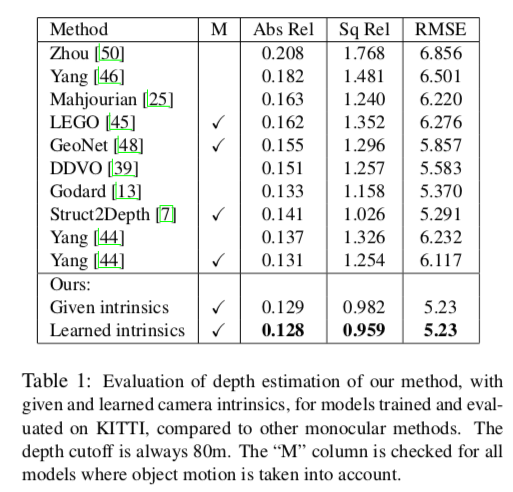
SOTAを達成。
定性的評価
以下はYouTube8M

このデータではカメラの内部座標は不明だが、ちゃんと推論できている。