はじめに
Netで見つけた以下の論文
[1] Y. Sun, et. al "Human activity recognition based on time series analysis using U-Net"
のざっくりしたまとめ。
acceptされたjournal等は不明。
arXiv:
https://arxiv.org/abs/1809.08113
概要
- 時系列データを解析して人の行動認識を行うモデル
- 旧来手法のsliding windowで切り取ったsequentialごとに行動を付与するのではなく、各時刻ごとに行動を付与する
- これをU-Net構造を用いることで達成
従来の機械学習を用いた手法
機械学習を用いて時系列データを解析し、人の行動認識を行うモデルの従来手法(deep learning 以前)は論文をざっくりまとめるとこんな感じか?
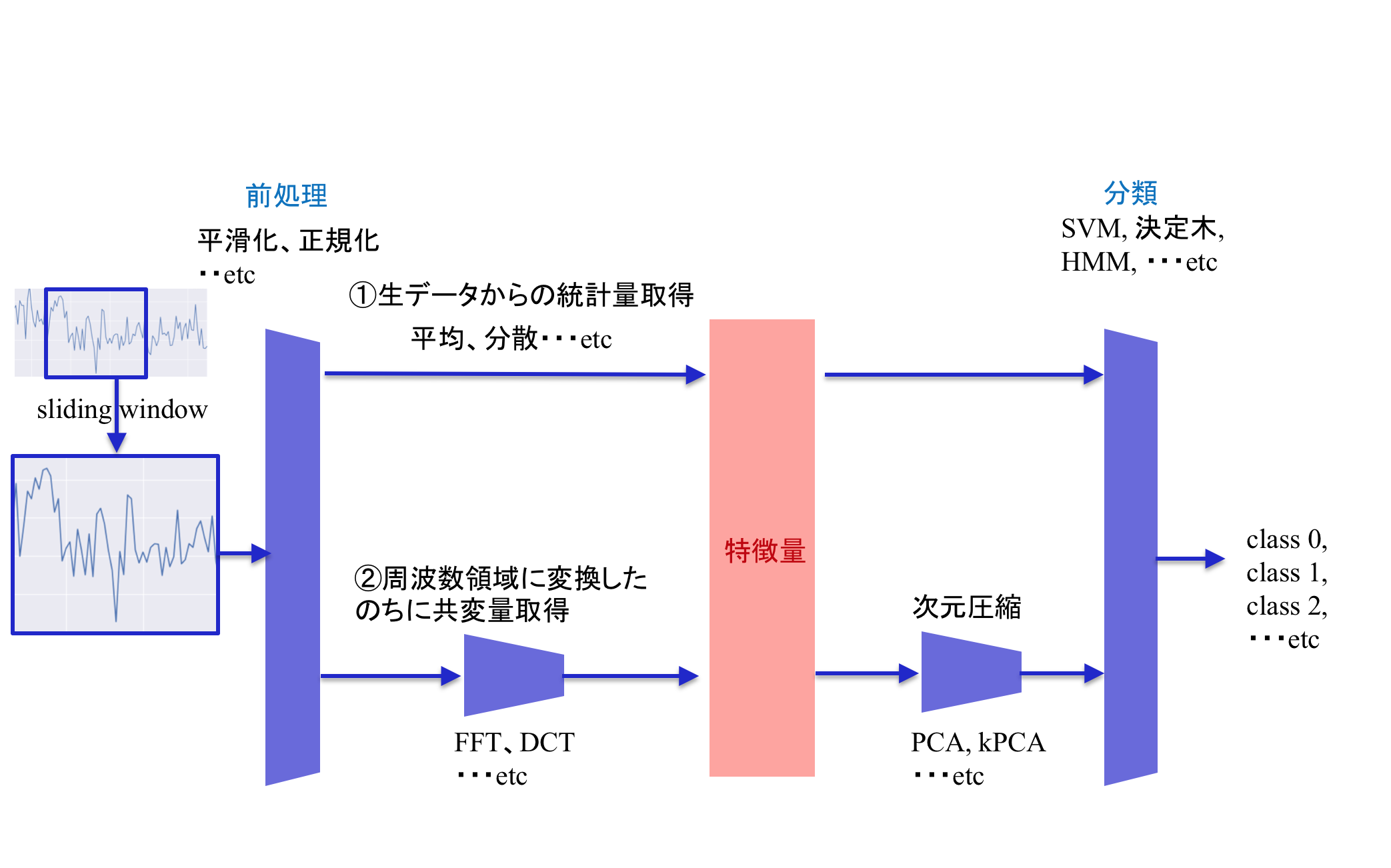
1)まず時系列データから一部のsequentialを切り取る。
2)それに前処理を施す。
3)次に特徴量を抽出する。これは生データから抽出する場合とFFTなどで周波数領域に飛ばし、そこから抽出する場合がある。
4)最後に特徴量を用いて行動の分類をする。SVMや決定木などを用いる。全ての特徴量を用いる場合と、次元圧縮してから用いる場合がある。
これらはハンドメイドな特徴量抽出器なので、最終的な分類精度が頭打ち。
deep learningを用いた従来手法
これに対し、deep learningを用いると以下の図のような感じか?

1)やはり時系列データから一部のsequentialを切り取る。
2)それに前処理を施す
3)1-d conv や RNN を用いて特徴量抽出&分類を一気に行う。論文にはないが3、4年前に流行った2-d convも入れてみた。
特徴量抽出器も学習することで精度の向上が期待できる。
しかし著者が言うところの「multi-class window problem」は残る。
これは、sliding windowで切り取ったsequentialに対して常に1つの行動が付与されるという問題。行動の切り替わり部分では2つ以上の行動が対応するはず。
提案手法のアーキテクチャ
提案手法は以下。

U-Net構造を用いることで、各時刻に対する行動を付与できる。これで「multi-class window problem」を克服できる。
実験と結果
7つのdatasetで他の手法とaccuracy, F1-scoreで比較した結果は以下。

表示している数値は各datasetにおけるaccuracy, F1値を平均したもの。
U-Netが一番高い。