はじめに
CVPR2018から以下の論文
[1] J. Tremblay, et. al. "Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization"
のまとめ。
arXivのリンク
https://arxiv.org/pdf/1804.06516.pdf
概要
- 自動的に合成して作ったデータが、object detectionタスクにおいても有効であることを初めて実証した
- domain randomizationというデータ拡張のテクニックを使ってデータを生成した
- この合成データセットのみで学習したモデルは、virtualなKITTIの合成データで学習したモデルを上回った
- この合成データセットで学習したモデルを人がアノーテーションしたデーセットでの学習に転移させることで、後者のみによる学習の精度を上回った
背景
deep neural networkの学習には膨大なアノーテーションが欠かせないが、これはなかなか入手しにくい。
そこで幾つかのタスクでは合成したデータを用いて学習する手法が用いられてきた。
しかし、合成したデータは photorealism に欠ける。
そこで、合成したデータを用いる場合はランダムなテクスチャーを加える事で、この問題を回避した。(domain randomization)
本手法はこの domain randomization(以下DR)をobject detect用に拡張して利用する。
拡張した Domain Randomization(DR)
以下の図([1] Figure 1)で説明すると・・・
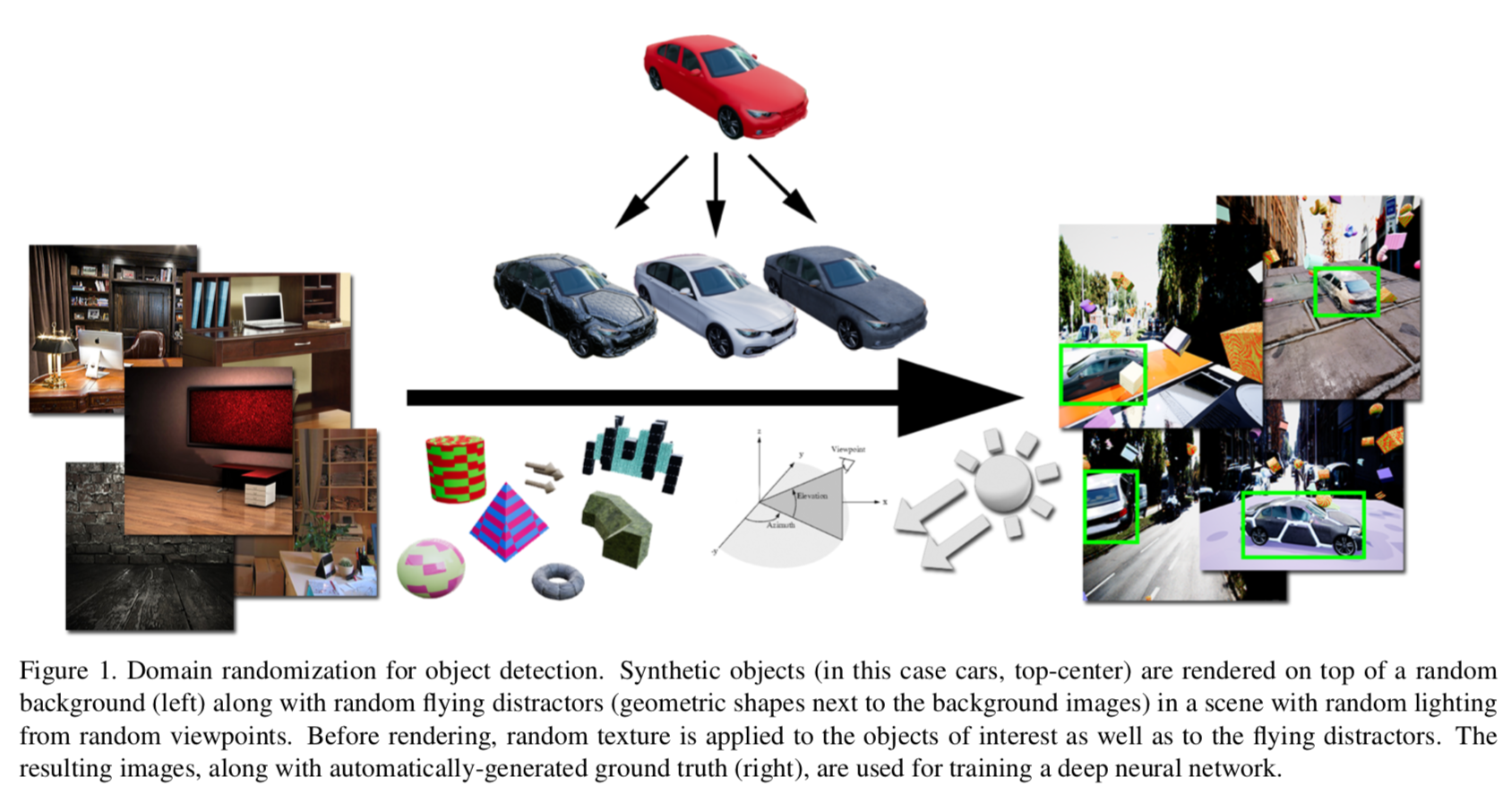
まず図の中央上側は合成した複数の車の3D モデル。
一方、図の左側はそれぞれの背景。この背景に車を置く。
この時、図の中央左寄りにある三角錐とか球などの幾何学的な形状(flying distractors)を加える。
また撮影するカメラは任意の位置にし、ライトも任意の形状のものを任意の位置に配置する。
これにより生成された画像は図の右側。同時にアノーテーションも取得する。
具体的に生成された画像は以下の図[1]Figure2

上側は virtual KITTI というKITTIに似せて作ったデータセット、下側が本手法で合成した画像。
本手法と virtual KITTI との比較実験
設定
本手法で合成したデータで学習したモデルと、virtual KITTIで学習したモデルとを精度で比較した。
比較に用いたモデルは、1)Faster-RCNN、2)R-FCN、3)SSD。
メトリクスは、IoUが0.5を超えてるバウンディングボックスに対して true/falseを計算。
比較の結果
結果は以下の[1]Table 1。

おおよそ本手法の方がよさげ。
bounding boxの出力例
bounding boxの出力例は以下。

precision-recall curve
precision-recall curve は以下。
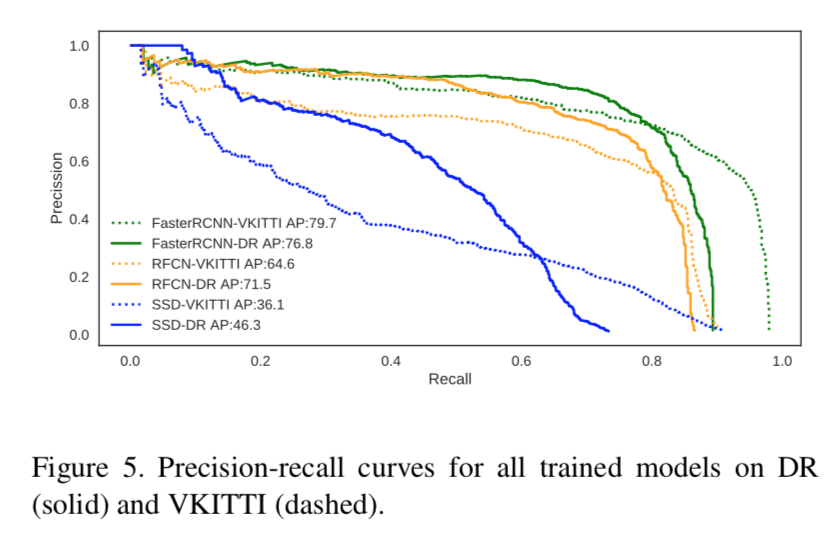
recallが低いところでは本手法の方がprecisionが高いが、逆にrecallを上げるとprecisionで劣る。
実際のKITTIデータで転移学習した時の結果
実際のKITTIデータで転移学習した時の結果は以下。
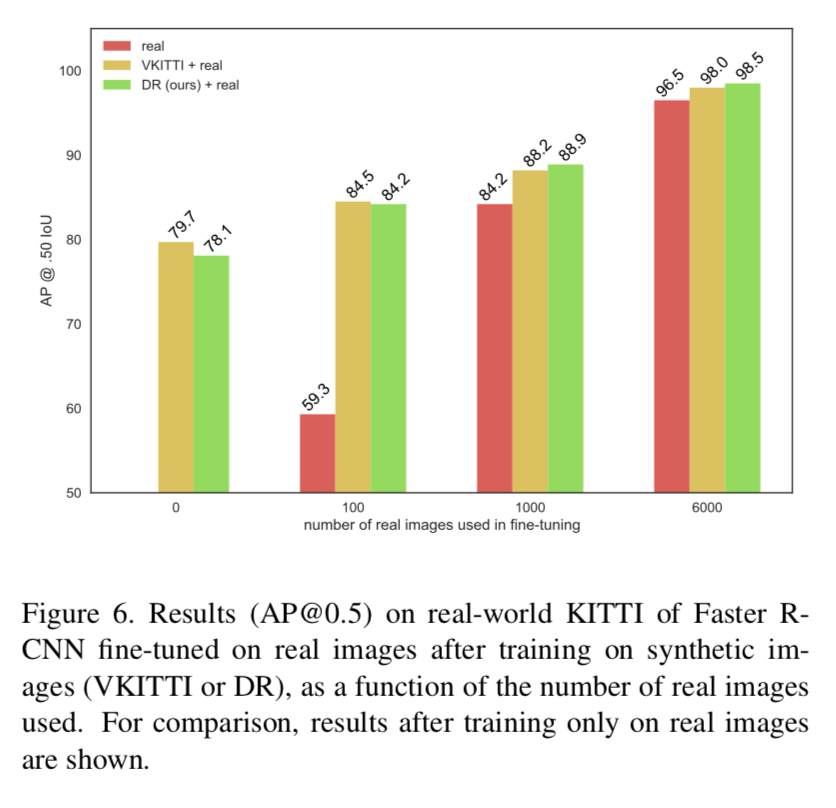
本手法で事前学習してから転移させた方が性能がいい。
ablation study
本手法におけるそれぞれのテクニックのどれが効いてるかを知るため、各テクニックの1つを落として学習させた結果は以下。

ライトの位置を固定させたものが一番性能が悪い。つまりライトの位置をランダムにすることが一番効いている。
Reference
[2] J. Tobin, et. al. "Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World"