浜崎あゆみ形態素解析botの作成から始動まで
1.はじめに
pythonを学習し始めて、約2か月。何か形になるものを作りたいと思って、大好きな浜崎あゆみさんの歌詞っぽいつぶやきをするTwitter botを作成して、やっと自動で動くようになりました。
同じ方法を用いれば、誰でも好きなアーティストのbotを作成することができます。
実際に稼動しているbot
https://twitter.com/masarin11262
なお、現在はソースを修正しツイートする際にフォローとフォロアーを解析し、自動的にフォロバする仕様になっています。
ぜひフォローしてください。
botの仕様
- プログラミング言語:python3.5.2
- Twitterの作動:TwitterAPIを使用
- Twitterの操作:Tweepyを使用
- 形態素解析:Janomeを使用
- 自動可動の方法:ダミープログラムとともにherokuにアップし、スケジューラーを用いる
Twitterとの連携はこちらを参考にしました。
[Python] OAuth認証でTwitter連携/ログインを実装する
https://qiita.com/mikan3rd/items/686e4978f9e1111628e9
2.コード
bot本体のコード
ファイル名:「tweet.py」
※このコードを「tweet.py」という名前のファイルに保存します。
# coding: utf-8
from janome.tokenizer import Tokenizer
import re
import random
import tweepy
sentence = ''
def parse(text):
t = Tokenizer() # Tokenizerオブジェクトを生成
tokens = t.tokenize(text) # 形態素解析を実行
result = [ ] # 形態素を格納するリスト
for token in tokens:
result.append(token.surface)
return(result)
def kashi_read():
# 歌詞の入ったテキストファイルを指定
filename = "text.txt"
with open(filename, "r", encoding = 'utf_8') as f:
text = f.read()
# 空白をカンマ(、)に変換 改行を(。)に変換
text=re.sub(' ','、',text)
text=re.sub(' ','、',text)
text=re.sub('\n','。',text)
return(text)
def markov_dic(wordlist):
# マルコフ辞書の作成
markov = {}
p1 = ''
p2 = ''
p3 = ''
for word in wordlist:
# p1、p2、p3のすべてに値が格納されているか
if p1 and p2 and p3:
# markovに(p1, p2, p3)キーが存在するか
if (p1, p2, p3) not in markov:
# なければキー:値のペアを追加
markov[(p1, p2, p3)] = []
# キーのリストにサフィックスを追加(重複あり)
markov[(p1, p2, p3)].append(word)
# 3つのプレフィックスの値を置き換える
p1, p2, p3 = p2, p3, word
return markov
def generate(markov):
""" マルコフ辞書から文章を作り出す
"""
global sentence
# markovのキーをランダムに抽出し、プレフィックス1~3に代入
p1, p2, p3 = random.choice(list(markov.keys()))
# 単語リストの単語の数だけ繰り返す
count = 0
while count < 40:
# キーが存在するかチェック
if ((p1, p2, p3) in markov) == True:
# 文章にする単語を取得
tmp = random.choice(markov[(p1, p2, p3)])
# 取得した単語をsentenceに追加
sentence += tmp
# 3つのプレフィックスの値を置き換える
p1, p2, p3 = p2, p3, tmp
count += 1
# 最初に出てくる句点(。)までを取り除く
sentence = re.sub('^.+?。', '', sentence)
# 最後の句点(。)から先を取り除く
if re.search('.+。', sentence):
sentence = re.search('.+。', sentence).group()
# 閉じ括弧を削除
sentence = re.sub('」', '', sentence)
#開き括弧を削除
sentence = re.sub('「', '', sentence)
#全角スペースを削除
sentence = re.sub(' ', '', sentence)
def overlap():
""" 重複した文章を取り除く
"""
global sentence
sentence = sentence.split('。')
if '' in sentence:
sentence.remove('')
new = []
for str in sentence:
str = str + '。'
if str=='。':
break
new.append(str)
new = set(new)
sentence=''.join(new)
import tweepy
# 各種キーをセット'AYUAYUAYUAYUAYUAYAU'のところは自分のキーを入力
CONSUMER_KEY = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
CONSUMER_SECRET = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
ACCESS_TOKEN = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
ACCESS_SECRET = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# APIインスタンスを作成
api = tweepy.API(auth)
# 歌詞をテキストファイルから読み込み
text=kashi_read()
# 歌詞をわかち書きしてリストにする
wordlist = parse(text)
# マルコフ辞書の作成
markov=markov_dic(wordlist)
print("ayubot始動")
while(not sentence):
#ツイートする本文を作成
generate(markov)
#重複する部分を削除
overlap()
# カンマ(、)を空白に戻す
sentence=re.sub('、',' ',sentence)
# 句点(。)を改行に戻す
sentence=re.sub('。','|n',sentence)
# ツイートする本文の後にタグを付ける(#浜崎あゆみ #形態素解析 #ayu)
sentence=sentence+'\n'+'#浜崎あゆみ'+'\n'+'#形態素解析'+'\n'+'#ayu'
# ツイートの実行
api.update_status(status=sentence)
ダミーファイルのコード
ファイル名:index.py
※このコードを「index.py」という名前のファイルに保存します。
こちらにあったのをそのまま利用してます。
herokuへのデプロイ:「簡単!Herokuで動くTwitter botをPythonで実装する」
http://qiita.com/enomotok_/items/41275dd904c8aa774e72
# -*- coding: utf-8 -*-
import os
from bottle import route, run
@route("/")
def hello_world():
return "ayumi hamasaki Just the beginning 20 第2章 ~sacrifice" # ここで返す内容は何でもよい
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
3.歌詞の収集
4.歌詞
ネットからコピーしてきて、テキストファイルに貼り付けます。保存するときに、文字のコードを「UTF-8」とすることがポイントです。歌詞の意味を考えながら適当に改行や空白を入れます。
なお、こちらの2つサイトは歌詞のコピーが可能です。(曲の名前で検索した時にURLでわかります)
まあ、大好きな歌詞ですからコピーできない場合は頑張って打ちましょう。
最近の曲もあります↓
https://genius.com/artists/Ayumi-hamasaki
古い曲しかありません↓
http://lyrics.jetmute.com/index.php
(テキストファイルの様子)
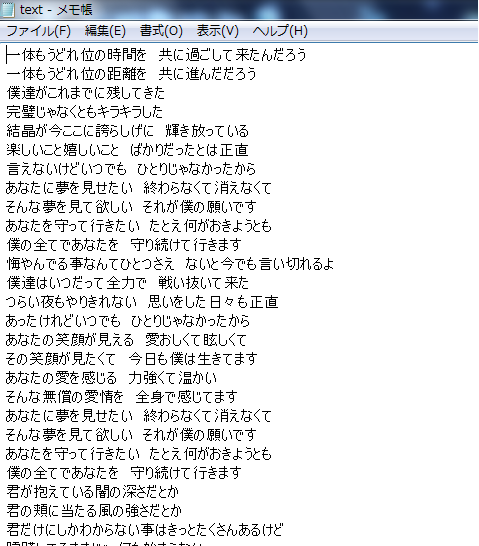
そして、このファイルを「text.txt」ファイルという名前のテキストファイルで、「index.py」及び「tweet.py」と同じフォルダに保存します。
これだけで、手動で起動させればツイートすることができます。
「text.txt」に保存される歌詞の数が少ないと、元の歌詞がそのまま生成されるケースが多いですが、歌詞をある程度増やすと元の歌詞から少し内容異なるセンテンスがツイートされます。
例えば、これは「Trauma」の歌詞がそのままツイートされています。
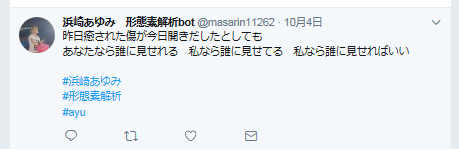
単純にこの行が選択されただけです。
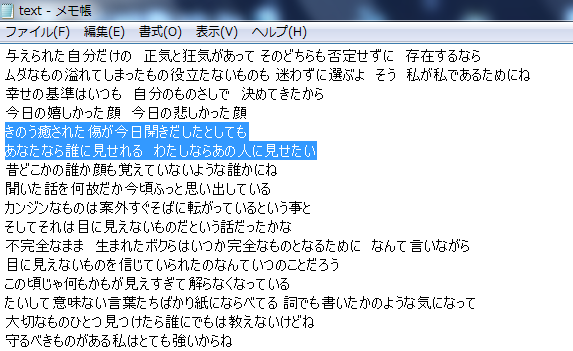
こちらは、うまく形態素解析されています。
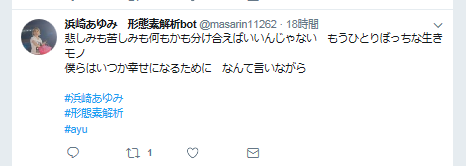
「悲しみも苦しみも何もかも分け合えばいいんじゃないなんて」
「今のふたりなら信じられるはず もうひとりぼっちじゃないから」
「人はみんないつだってひとりぼっちな生きモノ」
「僕らはいつか幸せになるために 生きて行くんだって 思う日があってもいいんだよね」
「不完全なまま 生まれたボクらはいつか完全なものとなるために なんて言いながら」
という4つのセンテンスから生成されていて、何となく意味が通じるツイートです。
これだけでそれぽい歌詞を手動でツイートすることが可能です。
4.Herokuへのデプロイとcronの設定
TwitterAPIの設定やコードの作成は割りとスムーズにできましたが、これを自動で実行させるためにレンタルサーバーへディプロイするのにかなりてこずりました。
理由は、botをサーバー上で起動させる方法をよく理解していなかったことと、後で説明する「Procfile」ファイルです。結論から先に述べておきますと、「Procfile」を保存する際の文字コードは「ANSI」で、ファイルの種類は拡張子がないただのファイルです。
① 大きな勘違い
PCをネットに接続した状態で、プログラムを定期的に何らかの処理(例えば1時間に1回、ツイートする)をするだけならば、現在の時刻を取得し、ある時刻を過ぎたら処理を行うループを常に実行させておけば簡単に実現できます。もしくは、Windowsのタスクスケジューラーを用いて設定した時刻になったらプログラムを起動させることによっても可能です。
しかし、いずれの方法も本質的には自分のPCから処理をしていることに違いはありません。そうではなく、自分のPCを起動させずに何かを処理させるにはどうすればいいのかといろいろ調べていると、個人ならレンタルサーバーなるものを利用すると手軽できることがわかりました。そこで、「Heroku」というレンタルサーバーが無料で扱いやすそうなので、これを用いることにしました。
ただ、ここで大きな勘違いをしており、レンタルサーバーというのは「yahooシティーズ」のようなホームページを作成するサイトみたいなものと思っていました。つまり、サーバー上でプログラムが起動するというのは、ホームページにアクセスすると画面に何かが表示されるようなものだと理解したのです。そして、プログラムをサーバーにデプロイした後の実行は、そのURLにアクセスすれば実行され、cronという機能はURLにアクセスする操作を自動で定期的にしてくれるものだと早とちりしてしまいました。
この理解も半分は当たってはいますが、「URLにアクセスすれば実行される」と思い込んでいたために、デプロイした際に何十回アクセスしてもbotが起動せず、デプロイをやり直すことの繰り返しでした。
後にわかるように、この勘違いはProcfileをきちんと理解していなかったことによるものです。逆に言えば、冒頭の文字コードも含めて「Procfile」を理解し正しく扱えればHerokuへのデプロイとcronの設定は誰でも簡単にできます。
② Herokuのアカウント登録など
まず、Herokuにアカウント登録し、Heroku toolbeltのインストール等を行います。
Herokuの登録:https://signup.heroku.com/
登録方法などはこちらを参考にしました。
【Python+heroku】Python入れてない状態からherokuで何か表示するまで(前編)
https://qiita.com/it_ks/items/afd1bdb792d41d0e1145
【Python+heroku】Python入れてない状態からherokuで何か表示するまで(後編)
https://qiita.com/it_ks/items/ca6c7f6e8fc89e49e46d
なお、基本的にはスムーズに行きましたが、公開鍵の登録にちょっとつまづきました。
こちらを参考にして、公開鍵の登録を行ってください。
HerokuでSSH公開鍵(public key)を登録する方法(と削除して再登録する方法)
http://blog.infinity-dimensions.com/2012/02/heroku-public-key-add.html#!/2012/02/heroku-public-key-add.html
③ Herokuへのデプロイ
それでは、いよいよHerokuへのデプロイを説明します。
まず、フォルダを1つ用意し、「index.py」(ダミーファイル)と「tweet.py」(bot本体)と「text.txt」(歌詞が入力されたテキストファイル)を格納します。
ここでは、フォルダ名を「ayuchan」としています。
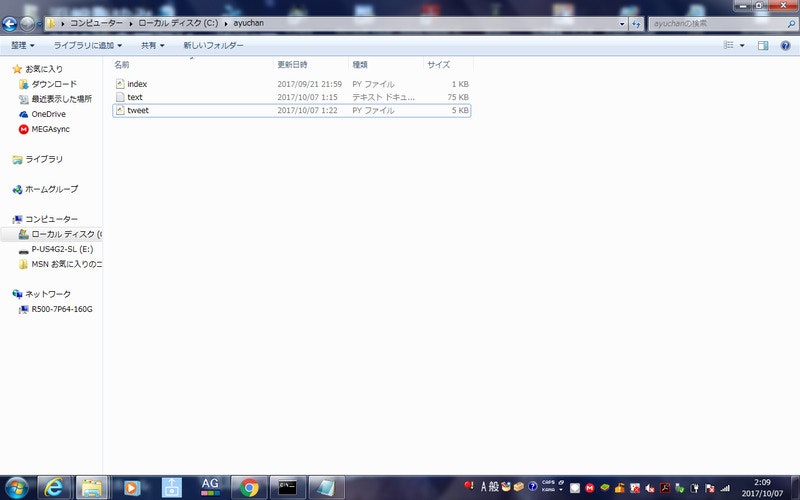
次に、「Procfile」ファイルを用意します。
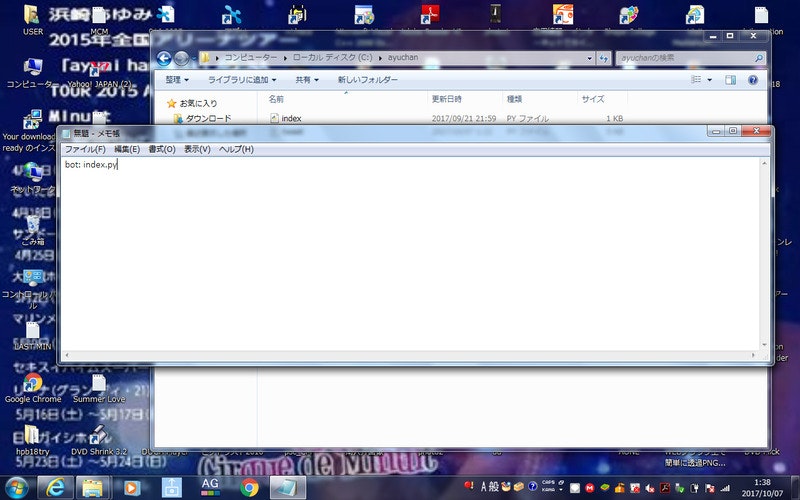
「Procfile」ファイルとは、簡単に言えばHerokuにデプロイするときに指定されるURLにアクセスした際に起動するプログラムを指定するものです。
ここでは、ダミーファイルを指定し、内容は
bot: index.py
とします。なお、「bot」の部分は何と記載してもよく、:(コロン)の後は半角スペースを入力し、起動するプログラム(正確にはコマンド名)の名称を入力するもので、
<コマンド名>: <実行するコマンド>
という書式になります。
この「Procfile」で注意すべきことは、
- (1)ファイル形式はテキスト(.text)ではなく、拡張子のないただのファイルとすること
- (2)ファイルを保存する際は文字コードを「ANSI」とすること
- (3)URLにアクセスしてもbotが起動するわけではない
ということです。
メモ帳を使って、ファイル形式を拡張子のない「ただのファイル」とするためには、まずファイルの種類を「すべてのファイル」とします。
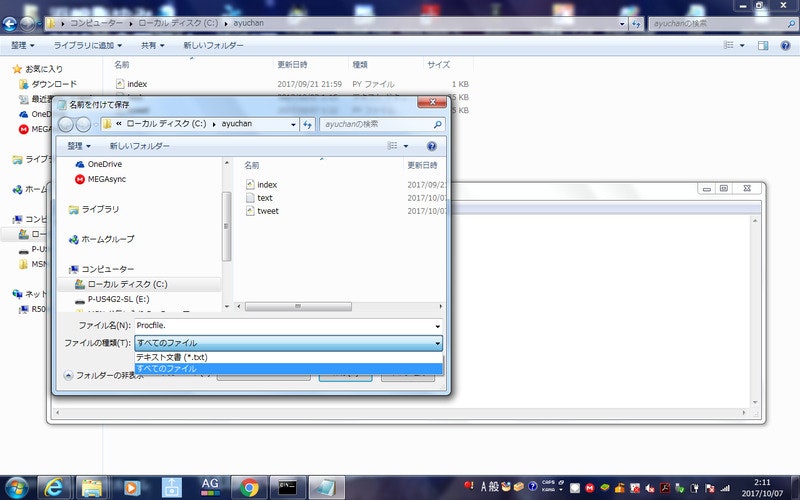
そして、ファイル名は、ファイルの名前入力した後、「.」だけを入力します。ここでは、ファイルの名前を「Procfile」とするので、ファイル名を「Procfile.」とします。
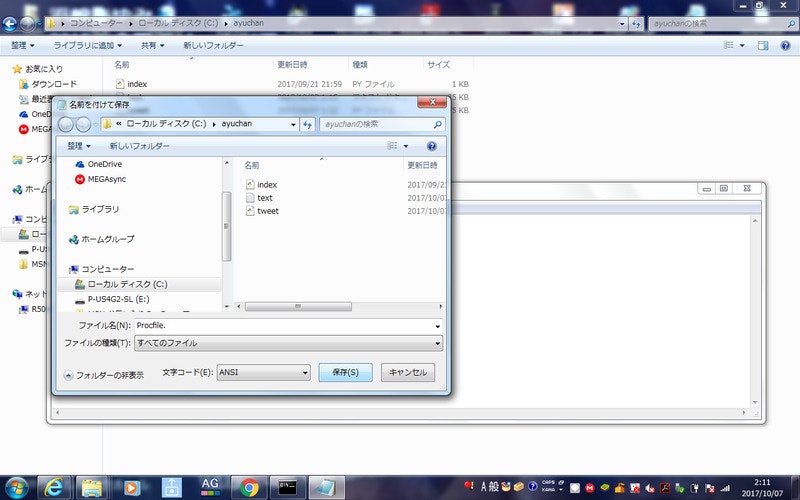
そして、文字コードを「ANSI」として、「index.py」等を格納したフォルダ(ayuchan)に保存します。
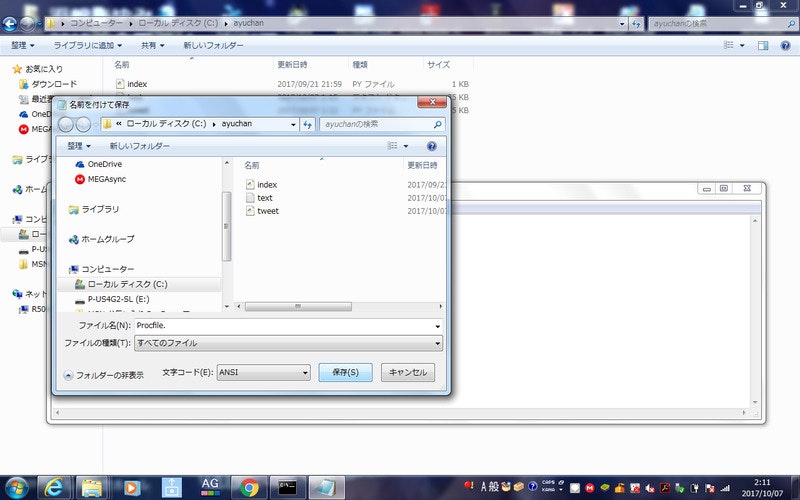
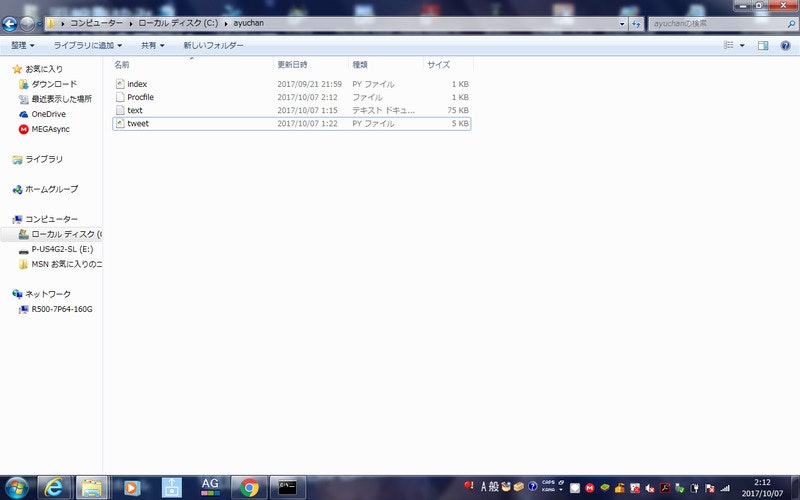
これで、フォルダ「ayuchan」の中には、「index.py」「tweet.py」「text.txt」「Procfile」が格納されることになります。
次のこのフォルダの中に「requirements.txt」というテキストファイルを用意します。この「requirements.txt」(以下、「r.t.ファイル」と略します)には、プログラムに使用されているJanomeやtweepyのバージョン等の情報が記載されます。恐らく、このr.t.ファイルに記載された情報に従って必要なモジュール等がHerokuにデプロイされるのだと思われます。
さて、このr.t.ファイルは自分で内容を入力する必要はありません。コマンドプロンプトでの簡単なコマンド入力で作成することができます。
まず、先ほどindex.pyやProcfile等のファイルを格納したフォルダにコマンドプロンプトから入ります。
使用するコマンド
cd 〔フォルダ名〕 フォルダに入る
cd.. フォルダから1つ上の階層のフォルダに移動する。
cd..
cd ayuchan
ここでHerokuにログインします。
heroku login
メールアドレスとパスワードを聞かれるので、Herokuのアカウントに登録したメールアドレスとログインパスワードを入力します。
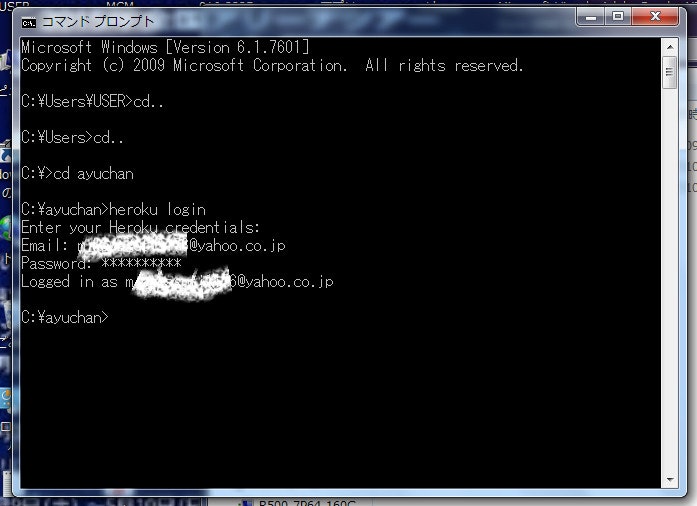
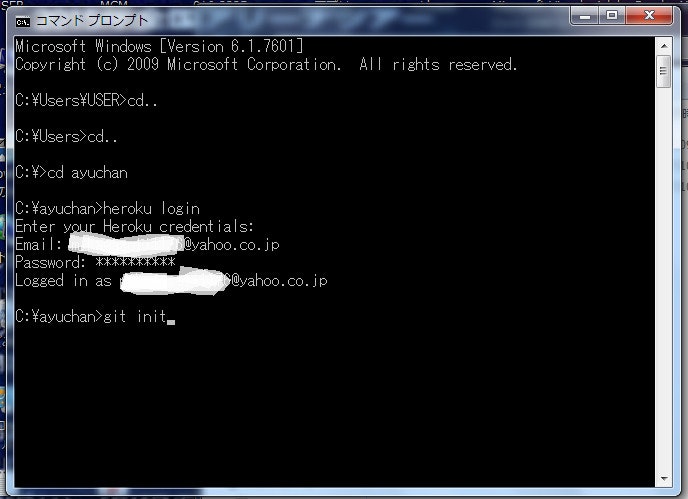
次にこのフォルダに貼ったままの状態で、git initと入力します。コマンドの意味がイマイチわかりませんが、git~というコマンドをこのフォルダで利用できるようにするための操作だと思います。
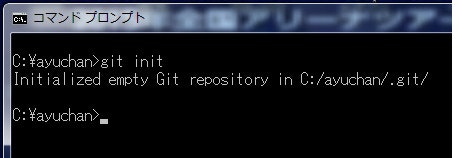
git init
Initialized empty Git repository in C:/ayuchan/.git/ と応答があり、フォルダの中に「git」という新たなフォルダが自動生成されます。
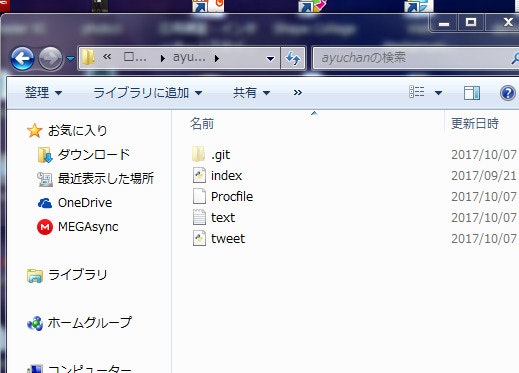
ここで、いよいよr.t.ファイルを自動作成します。
pip freeze -> requirements.txt
コマンドプロンプトにこのように入力するだけで自動作成されます。
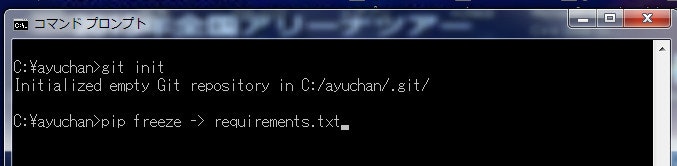
フォルダの中を見ると「requirements.txt」が生成されていることがわかります。
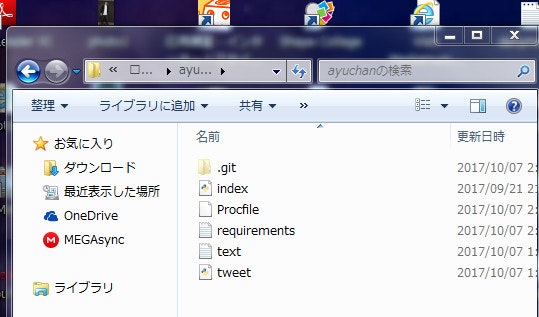
ファイルを開いてみるとこんな内容です。
次に、git add .と入力します。なお、「add」と「.」(ピリオド)の間には、半角スペースを入力します。
git add .
~~~
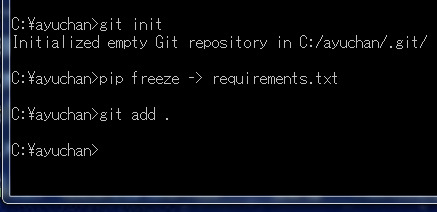
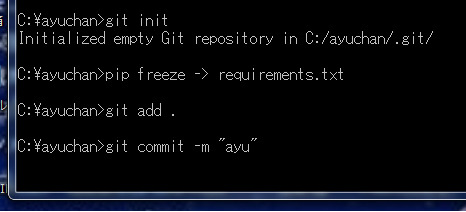
続いて、`git commit -m "XXX"`と入力します。なお、"XXX"部分は何を入力しても良いようです。
~~~
git commit -m "XXX"
~~~
`create mode ~`というメッセージが走ればOKです。
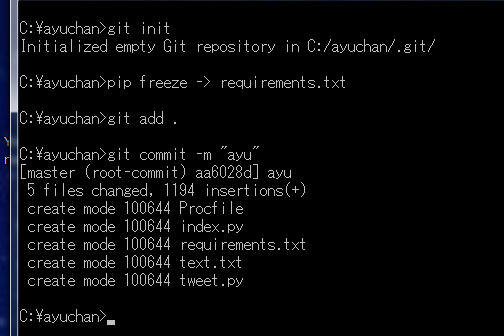
次に、Herokuのサーバー上にアプリをデプロイするための箱のようなものを作ります。
`heroku create 〔アプリ名〕`
なお、アプリ名の入力が無くても問題はありません。その場合は、自動で適当な名前が付けられます。
ここでは、アプリ名を「ayuchan」としました。
~~~
heroku create ayuchan
~~~
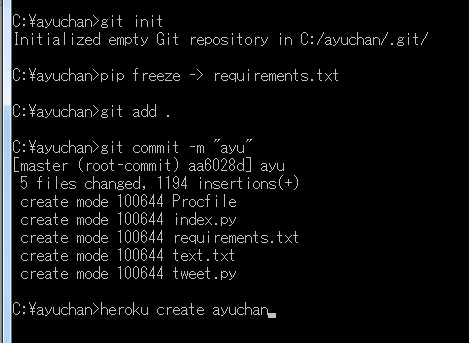
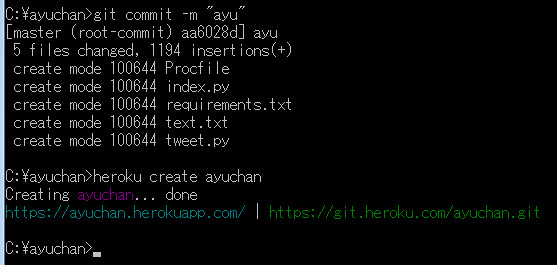
HerokuのWebサイトを見ると、「ayuchan」ができているのが確認できます。
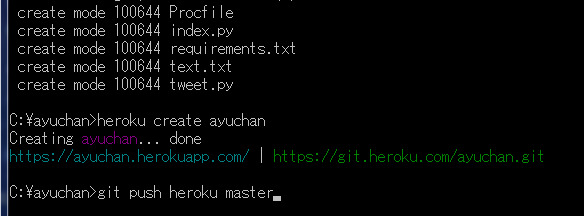
いよいよこれでデプロイする準備ができました。先ほど作ったHerokuのサーバーの箱にプログラムを実際に入れます。
`git push heroku master`と入力します。
~~~
git push heroku master
~~~
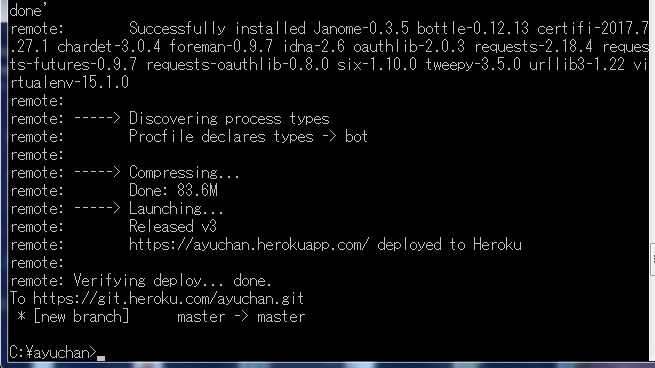
たくさんメッセージが走って5分くらいで完了です。
正常に動作するか、PCからサーバー上のプログラムを動かしてみます。
このコマンドは、実際にHeroku上のプログラムを動かします。
`heroku run 〔プログラムの種類 ファイル名〕`
~~~
heroku run python tweet.py
~~~
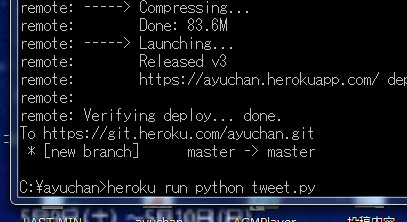
`Running python tweet.py on ayuchan....`との表示が、実際でHeroku上で動いていることを示しています。なお、「ayubot始動」というのはプログラムの`print("ayubot始動")`によるものです。
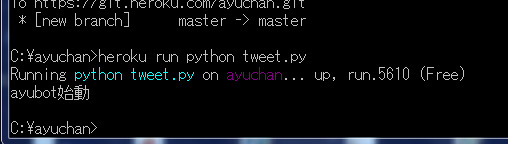
実際にTwitterの画面を見るとツイートされています。
これはHerokuという世界のどこかのサーバーにあるコードを東京都品川区にあるノートPCから操作してツイートしたものです。ちょっと感動(笑)
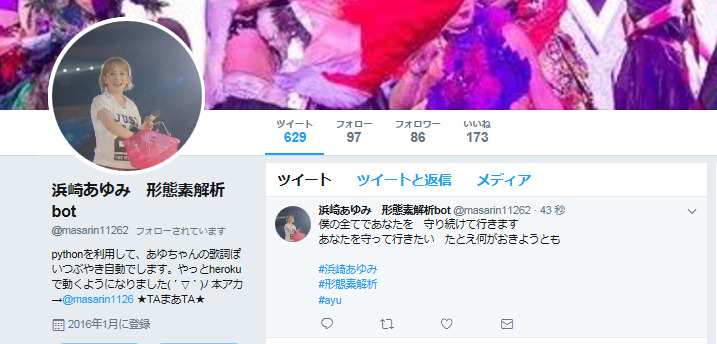
うまく作動することが確認できたら、Herokuのサイトにアクセスして**cron**の設定をします。
**cronとはアプリが自動で作動する時間を設定することができる機能**です。
デプロイしたアプリ「ayuchan」を選択します。
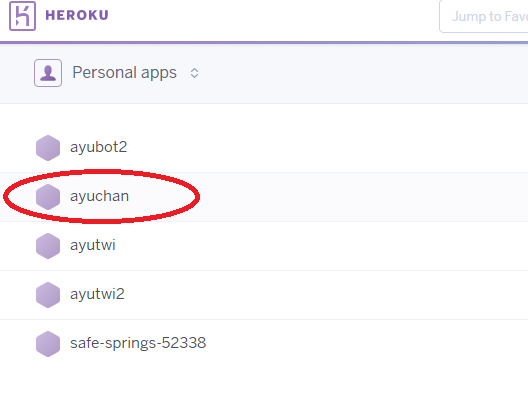
続いて、**configure Add-ons**を選択します。(上部の**Resources**をクリックしてもOKです。)
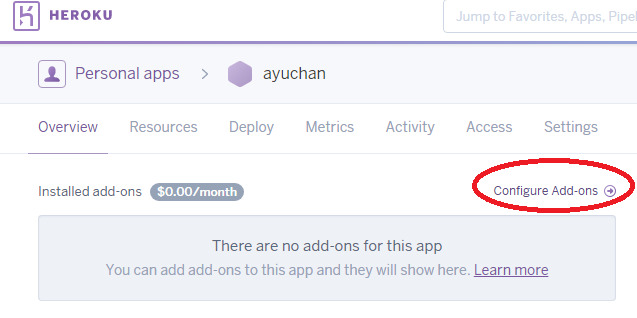
次の画面で、**Add-ons**と表示されたしたの検索キーを入力する部分に「sch」と入力します。(「scheduler」の最初の3文字)
すると**Heroku Scheduler**が表示されるので選択します。
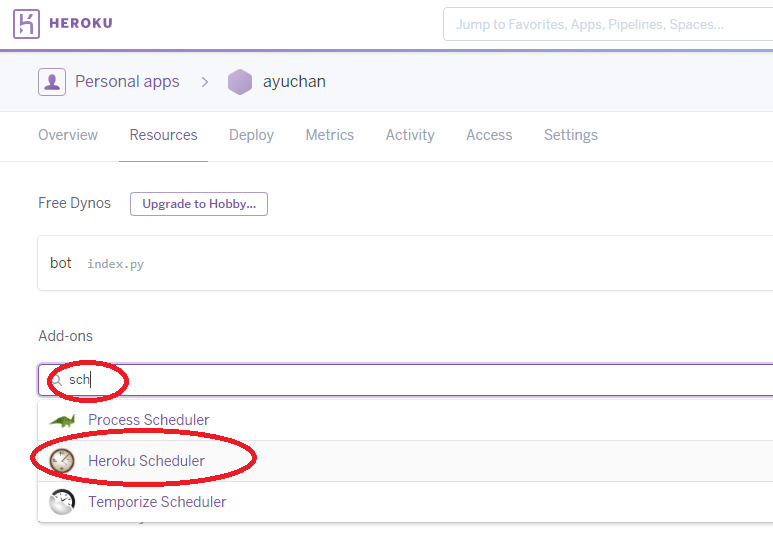
すると、次のように画面に表示されるので、**Provision**をクリックします。
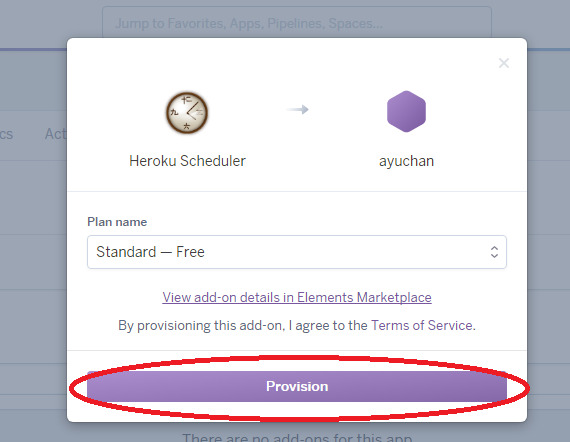
さっきの画面に戻り、「sch」と入力した部分の下に**Heroku Scheduler**が表示される(Heroku Schedulerがアドオンされた)ので、クリックします。
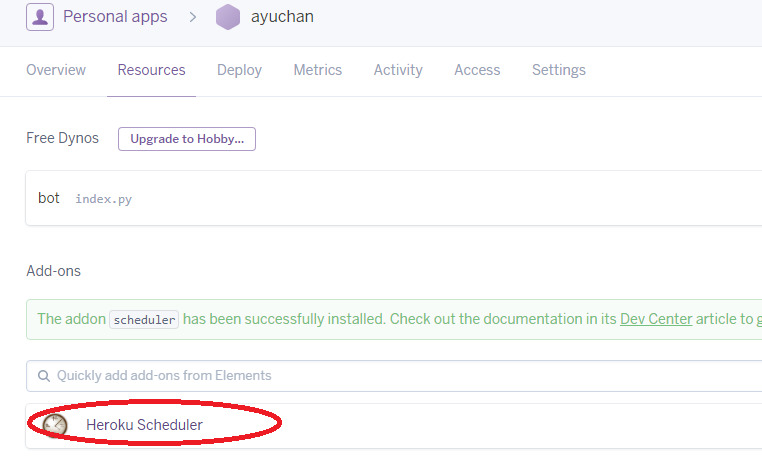
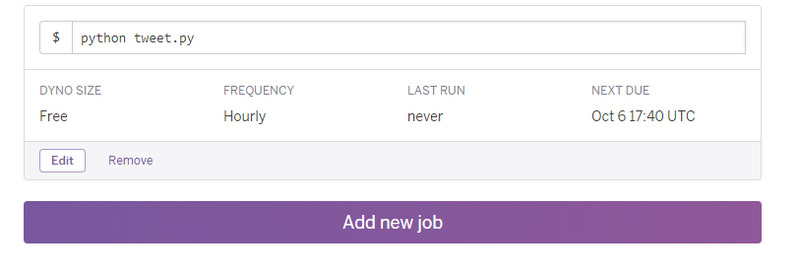
さらに次の画面で**Add new job**をクリックします。
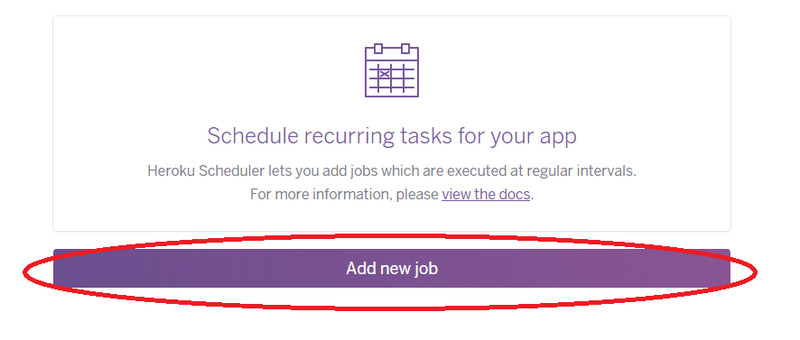
そして、ここでコマンドをセットします。
さきほどPCから作動させた時の**heroku run**の後の部分`python tweet.py`を**$**の部分に記入します。
続いて、**FREQUENCY**の部分で、プログラムを自動実行する頻度を選択します。ここでは、1時間に1回としたいので**Hourly**を選択します。
なお、1日1回なら**Daily**、10分毎なら**Every 10 minutes**を選択します。
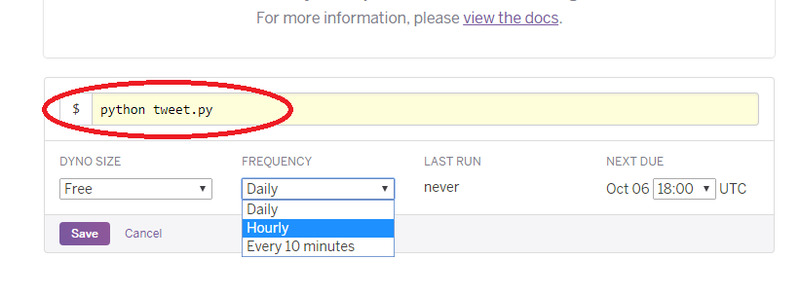
**NEXT DUE**というところで、1時間に1回実行させる場合の分を設定します。なお、Herokuの時間はアメリカの時間を基準にしているようですが、分についてはずれはありません。
「:40」を設定すると日本でも毎時40分に実行されます。
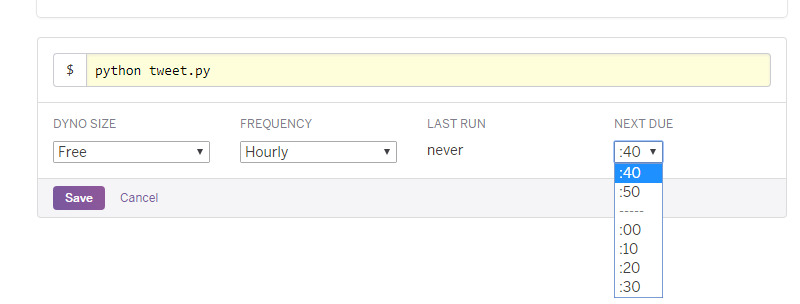
設定ができたら、**Save**をクリックします。
これで10分毎に自動ツイートされます。
なお、ツイートされる時間を変更する場合は**Edit**、自動実行を止める場合は**Remove**をクリックします。
こちらで実際につぶやいてますので、よかったらフォローしてください。
https://twitter.com/masarin11262
### ④ Twitter APIの各キーを環境変数の設定
コードをデプロイするということは、外部サーバーにコードそのものをアップロードすることなので、コード自体を見られる心配があります。
bot本体のコードの
~~~python
# 各種キーをセット'AYUAYUAYUAYUAYUAYAU'のところは自分のキーを入力
CONSUMER_KEY = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
CONSUMER_SECRET = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
ACCESS_TOKEN = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
ACCESS_SECRET = 'AYUAYUAYUAYUAYUAYUAYUAYUAYU'
~~~
'AYUAYUAYUAYUAYUAYUAYUAYUAYU'の部分には、twitterのアカウントからツイートするための暗号のようなもの(トークンキー)が入っており、これを外部から覗かれ使用されると第三者が自分のTwitterのアカウントからツイートされる危険があります。
この危険を回避するために、トークンキーをコードに直接記入せずに、環境変数というものを用いて設定します。
なお、トークンキーの取得はこちらをご参考にしてください。
>
[Python] OAuth認証でTwitter連携/ログインを実装する
https://qiita.com/mikan3rd/items/686e4978f9e1111628e9
>
取得したトークンキーをコマンドプロンプトから次のように入力することで、各環境変数(**CONSUMER_KEY** **CONSUMER_SECRET** **ACCESS_TOKEN_KEY** **ACCESS_TOKEN_SECRET**)が設定されます。
環境変数はHerokuの内部で設定されますが、ブラックボックス化されるので、これをコードが取得してツイートに使用します。
~~~
heroku config:set CONSUMER_KEY=【実際のCONSUMER_KEY】 CONSUMER_SECRET=【実際のCONSUMER_SECRET】 ACCESS_TOKEN_KEY=【実際のACCESS_TOKEN_KEY】ACCESS_TOKEN_SECRET=【実際のACCESS_TOKEN_SECRET】
~~~
これに伴い、bot本体のコードも次のように若干変更しました。
また、併せて、Classを用いて機能を追加しやすくし、さらに自動フォロバする機能を追加しました。
~~~python
# coding: utf-8
from janome.tokenizer import Tokenizer
import re
import random
import tweepy
import os
def kashi_read():
# テキストファイルを指定
filename = "text.txt"
with open(filename, "r", encoding = 'utf_8') as f:
text = f.read()
# 空白をカンマ(、)に変換
text=re.sub(' ','、',text)
text=re.sub(' ','、',text)
text=re.sub('\n','。',text)
print(len(text))
return(text)
class Createsen:
def parse(self,text):
t = Tokenizer()
tokens = t.tokenize(text)
result = []# 形態素を格納するリスト
for token in tokens:
result.append(token.surface)
self.keitaiso=result
def markov_dic(self):
markov = {}
p1 = ''
p2 = ''
p3 = ''
for word in self.keitaiso:
if p1 and p2 and p3:
if (p1, p2, p3) not in markov:
markov[(p1, p2, p3)] = []
markov[(p1, p2, p3)].append(word)
p1, p2, p3 = p2, p3, word
self.markov=markov
def create_sen(self):
sentence=''
p1, p2, p3 = random.choice(list(self.markov.keys()))
count = 0
while count < 50:
if ((p1, p2, p3) in self.markov) == True:
tmp = random.choice(self.markov[(p1, p2, p3)])
sentence += tmp
p1, p2, p3 = p2, p3, tmp
count += 1
sentence = re.sub('^.+?。', '', sentence)
if re.search('.+。', sentence):
sentence = re.search('.+。', sentence).group()
sentence = re.sub('」', '', sentence)
sentence = re.sub('「', '', sentence)
sentence = re.sub(' ', '', sentence)
self.sentence=sentence
def overlap(self):
self.sentence = self.sentence.split('。')
if '' in self.sentence:
self.sentence.remove('')
new = []
for str in self.sentence:
str = str + '。'
if str=='。':
break
new.append(str)
new = set(new)
self.sentence=''.join(new)
return(self.sentence)
class Ayubot:
def __init__(self):
self.unfriends=[803493671458873344, 789845030399725569, 3177443394, 790804770168594432, 2556878987, 4556413110, 188450555, 3401032272, 4557828535, 4726765340, 4736876187]
self.CONSUMER_KEY =os.environ["CONSUMER_KEY"]
self.CONSUMER_SECRET =os.environ["CONSUMER_SECRET"]
auth = tweepy.OAuthHandler(self.CONSUMER_KEY, self.CONSUMER_SECRET)
self.ACCESS_TOKEN =os.environ["ACCESS_TOKEN_KEY"]
self.ACCESS_SECRET =os.environ["ACCESS_TOKEN_SECRET"]
auth.set_access_token(self.ACCESS_TOKEN, self.ACCESS_SECRET)
self.api = tweepy.API(auth)
self.friendsids=self.api.friends_ids()
self.followersids=self.api.followers_ids()
self.text=kashi_read()
def followback(self):
for unfriend in self.unfriends:
if unfriend in self.followersids:
self.followersids.remove(unfriend)
for followerid in self.followersids:
m=(followerid in self.friendsids)
if m:
m=False
else:
try:
self.api.create_friendship(followerid)
except:
dam=1
def run_tweet(self):
createsen=Createsen()
createsen.parse(self.text)
createsen.markov_dic()
print("ayubot始動")
createsen.create_sen()
sentence=createsen.overlap()
while(not sentence):
createsen.create_sen()
sentence=createsen.overlap()
sentence=re.sub('、',' ',sentence)
sentence=re.sub('。','\n',sentence)
sentence=sentence+'\n'+'#浜崎あゆみ'+'\n'+'#形態素解析''\n'+'#ayu'
self.api.update_status(status=sentence)
ayubot=Ayubot()
ayubot.followback()
ayubot.run_tweet()
~~~