※ この記事はLooker Advent Calender 2020の25日目のものです ![]()
こんにちは。まさおです。
フリュー株式会社で1年ほど前から データニンジャ データアーキテクトをしています。
今回はALL GCPでアクションを実装し、LookerをGUIとしたインハウスDMPツールを構築した話をします。
やたら長いです。すいません。
作ったもの
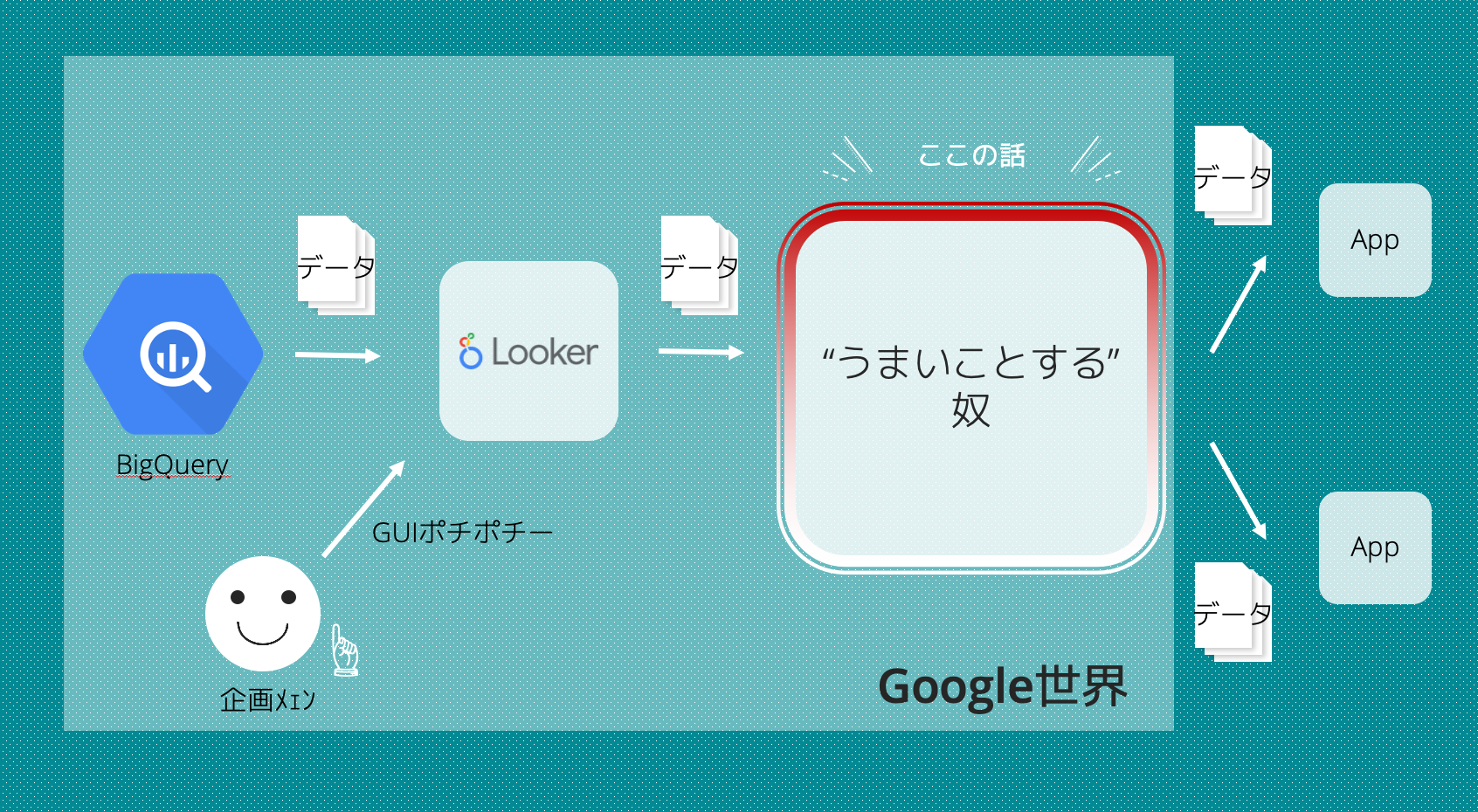
通常、Exploreを使う際はディメンションとメジャーを選んでグラフや表を出力…とするかと思いますが、ここでは各ディメンションでフィルターをかけて、実装の手順1で作成する「ユーザーID一覧メジャー」だけを選んで使います。
それをアクションでポチッと送りつければ、BQ内にあるデータを参照してデータを変換・加工、最終的にGCSに欲しいデータが吐き出されるという算段です。
今回は紹介しないのですが、社内で実用しているものはさらにそこからデータパイプラインをつなげ、ユーザーセグメントを作成する以外の処理を自動化しています。
今回はこの「うまいことする奴」と書いているところの作り方を解説していきます。
うまいことする奴の中身はこんな感じ。
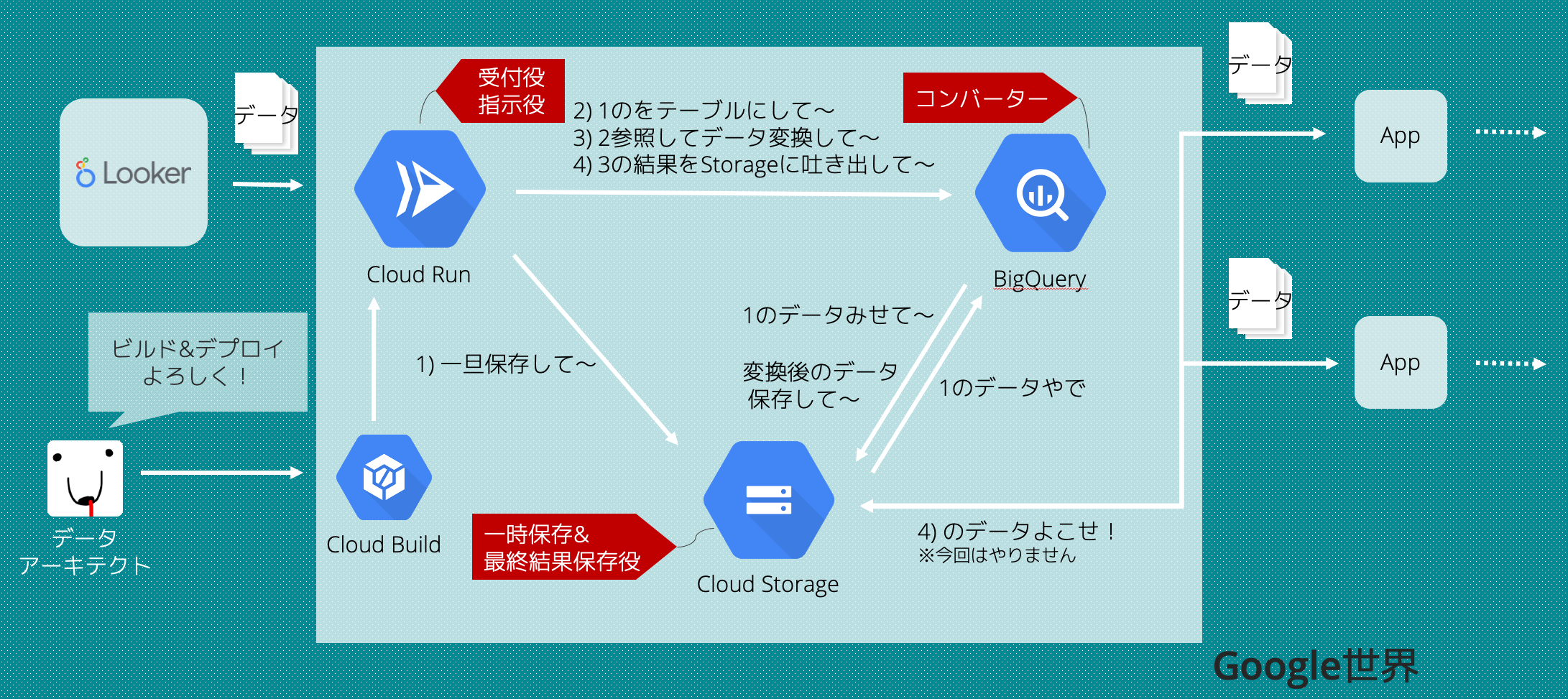
Looker上では、セグメントのユーザーIDの一覧を出力してアクションに送りつけます。
それを受け取ったアクション側でBQにクエリを投げ、データを変換してGCSに吐き出します。
Looker側で変換先それぞれをフィールドで用意してやれば、カスタムアクションとしてわざわざ実装する必要はないのですが、
- 変換先自体は集計したいものではない
- 変換したい種類が増えるたびにフィールドが増えることになるのでExploreの見通しが悪くなる
- Exploreを使う人間からしたら抽出するときはお決まりのフィールドを選んでアクションの実行時に変換先を選ぶほうが使いやすい
- 変換する部分の実装はそもそもLookerの関心外だよね
- BQ上に情報があるならBQの強力な処理能力を活用したら良くない?
ということで、このようなアクションの実装をすることにしました。
もちろんあれこれデータを変換する必要がなければ、こんな実装をする必要は無いです。
実装手順
- LookMLを書いてExploreをつくる(シュッっと終わるよ)
- Listの実装(シュッっと終わるよ)
- Formの実装(シュッっと終わるよ)
- Executeの実装(ながいよ)
- つくったアクションをAction Hubに追加する(シュッっと終わるよ)
- 動かしてみて喜ぶ
LookerのカスタムアクションはList / Form(任意) / Executeの3つのAPIから構成されていて、手順の2〜4で作成しています。
このあたりの話はLookerアドベントカレンダーの20日目の記事で丁寧に解説しておられる方がいらっしゃったので、ぜひそちらもあわせて御覧ください。
ほかにもこのあたりも参考になります。
LookMLを書いてExploreをつくる
LookMLの実装の基本の話はしませんが、データ抽出をするに当たり、大量のデータを適度な長さのArrayで出力させる話だけ紹介します。
というのも、アクションに渡すユーザーID一覧は100万件とかとにかく大量に出力したく、Lookerで扱える行数上限をかいくぐらせるためです。
そして接続先のデータソースがBig Queryの場合は1行の長さ上限があるので、それも程よくかいくぐらせるためです。
ということでLookMLはこんな感じです。
# 抽出するユーザーID これをリストにして吐き出したいのでhidden
dimension: user_id {
label: "ユーザーID"
type: number
primary_key: yes
value_format_name: id
sql: ${TABLE}.user_id ;;
hidden: yes
}
# 適当に10行に分割して出力させるためにラベル付をしているディメンション。Exploreを使う人間としてはどうでもいいのでhidden。
dimension: random_label {
label: "ユーザーIDのランダム分類用ラベル"
type: number
sql: mod(ABS(${user_id}), 10) ;;
hidden: yes
}
# 大本命のuser_idをリスト出だしてくれる奴
measure: user_id_list {
label: "ユーザーID一覧"
type: string
sql: ARRAY_TO_STRING(ARRAY_AGG(CAST(${user_id} as STRING)), ",") ;;
required_fields: [random_label]
}
random_labelなんだコレ
これは user_id を適当に10行に分類するためのラベルです。
ここでは user_id が整数なので、10で割った余剰をラベルとして使っています。
セグメントによっては均等な分割にはなりませんが、目的はLookerとBQの上限をかいくぐるためなので問題なしとしています。
また分割する数を変えたい場合は mod(ABS(${user_id}), 5) とか、mod関数の2つめの引数を変えればOKです。
ここをフィルターオンリーディメンションにすれば、Explore上で任意の数に変更させるなんてことも出来ます。
大本命user_id_list
ディメンションじゃなくてメジャーにすること、そして required_fields: [random_label] を入れることが大事です。
これによって random_label でつけたラベルごとにgroup byしてから配列にできるので、1行を程よい長さにしつつ、行数も程よい長さで出力できます。
Listの実装(シュッと終わるよ)
LookerのAction Hubでこのカスタムアクションを表示するためのパートです。
リクエストを投げたらjsonを返すだけのAPIを用意してやればいいので、Google Cloud Functionで作ります。
Cloud Functionで関数を作成を押したら、関数名を入れて、未認証の呼び出しを許可します。
他の設定はデフォルトのままでOKです。
Cloud Functionはいくつかランタイムが選べますがここではPythonです。
def action_list(request):
r = request.get_json()
response = """
{
"integrations": [{
"name": "cloudstorage",
"label": "IDをデコードして保存するやつ",
"supported_action_types": ["query"],
"url": {executeのエンドポイントURL},
"form_url": {formのエンドポイントURL},
"icon_data_uri": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAYAAABccqhmAAAACXBIWXMAABYlAAAWJQFJUiTwAAAQD0lEQVR42u2dT2xcxR3Hv+/Z+UM3lY2qtI6a1o4aVaISjXOgqlSogyxUNZekoF56qQVHlGDgtip0ExffKoVE7Q2xUZUeCpSgiqCKrmK7EUgckgWhcomKIyphCdHYVlxwEmd7yFuzXtvrfbvz3pt58/lIHAhk/8zO7zvfme+8maBWqwkA/CSkCQAQAABAAAAAAQAABAAAEAAAQAAAAAEAAAQAABAAAEAAAAABAACn6KUJ1jI6udQv6VD0z7CkEVrFaaYlVSVNSZqqFAvzNMlXBDwNuFr4hySNSzpCa+Sas5LKlWJhiqZAAOqFX2Kk99IZlHwXAm8FILL6ZUZ873lD0pivUwMvBSAa9c9L6qP/g6QFSUd9dAOhh8U/JukixQ8N9Em6GPUNBCDnxf8y/R024WXfRCCk+AH8FQEv1gBGJ5eOSnqdvg0x+EWlWDiPALhf/EO6uxGEOT/EYUHScKVYmGUK4DZlih86oC/qO6wBOD7vZ4MPdMpI3tcDcjsFiDb6zDL6g4GpwFBeNwrl2QGMU/xgaCowjgNwa/QfkvQxfRcMsi+PC4J5dQCn6K9An/LQAUT7/C/SXyEBHs7b8wJ5dABl+ingAjwUgNHJpXFJg/RTSIgDUR9jCmBh8RP7QRrkKhbMkwMoUfyQAn1RX8MBWDT6D4nYD9IlF7FgXhxAmf4I9DkPBSB61Jf9/pA2I1HkjABkDJt+ABfgowCMTi6VROwH2THoeizo7CIgsR9YgtOxoMsO4BTFDxbgdCzopAMYnVwalnSFvgcWcbBSLFRxAOmN/gD0Sd8EgNgPLGUk6psIQILF38/oD7gAfx0AT/uBzQxG0bQzOLMIyPn+4AhOxYIuOYASxQ8O0OfSVMAJB8AxX+AgTsSCrjiAEv0JHMMJF2C9AHC7DziKE7Gg1VOAKParipV/cJNrunvBqLULgrY7AGI/cJlBWX6rkLUOgGO+ICdYfc24zQ6AHX+QB6x+WtBKB0DsBznEyluFbHUAjP6QN6x0AdYJQBT7HaC/QM4Yifo2U4AWxc8xX5BnrIsFbXMAJYofcox1saA1DoDYDzzBqljQJgdQpm+AB1j1tKAVDoDYDzzEiljQFgfA6A++YYULyFwAoptV2O8PvnHAhlgw0ykAsR94TubHh2XtAEoUP3hMnzKOBTNzANzuA7DKvqxiwSwdAPv9ATKuhUwEgNt9ANZwJIrCvXEAjP4Aayl7IQDRzSnEfgBrGYwi8VRJdRGQ2A+gJanHgmk7gFMUP8CmpH58WGoOgP3+AG2TWiyYpgMo8bsCtEU5V1MAbvcBiMVIWrFgmELx9zP6A9jpAtJwADztBxCfVGLBRBcBo2O+qmLlH6ATEo8Fk3YAJYofoGMSPz4sMQdA7AdgjIOVYqHqmgNgvz+A5bWUiABwuw+AUUaiJ2jtF4Ao9mP0B3DABSThAMbFwh+AaQajJ2mNYnQRkNt9ABLFeCxo2gFg/QGSw3gsaMwBEPsBpIaxWNCkAyjzuwCkgjEXYEQAuN0HIFVGTN0q1PUUgGO+ADLhmu5eM97VgqAJB1Ci+AFSZ1AGbhXqygEQ+wFkykLkAmazcgBlfgOAzOj6ENGOHQCxH4A1PFwpFqbSdgCM/gB20LEL6EgAuN0HwCo6jgVjTwGI/QCspKNYsBMHwO0+APbRUSwYywGMTi4NS7pCW7fmZz/s1UBfSEMYZG7hjv7+wW0aYmti3SrU28HoDy148pHtevSBbTREAnxz12396R3aoY0abfv0oLaHqehIIm732QKKPzl++eN7tHJziYZozZE4twqFbRY/x3xB5hR2hrqzchMRMOjU23UAPO0H1oAIbMmBdmPBLQUg2u8/TpsCIuCWC4ice9cOoCRiPzDA1blbqs4u6+rcLUQgefraGbhbxoDs949PpVigETYo/DMX5nXl4+XVPxvo71XxsXs1PLQj1mv99Ln/rB/FerarZzvtvgktY8GtHECJ9oNui//4S5+tKX5Jmpu/reMvfabq7DJOIOGpQEdTgGgRgdgPuuLMhXnd+PLOpv998rXrTAeSpWUsGG5S/P2M/tAtc/Mr60b+9f/PbSMuABFoSTmuAyD2AwMC0N7W3a1EAhHomsHo4N6tBSCK/X5Lm0G3DPS3t9P84L4dRt8XEdiQ0kaxYBh30QCgfQHo2bK4B/p7YycBiEBHbHh8WNg0+h+SdIS2AlMcO9yvXTs3D5uOH05uiwkisI6nIoe/qQNg9Aej7B/YptNP7F43HRjo79Xkr76hB++7J9H3RwTWUW78l9WNQFHs9zLt0x1sBNqcq3O3ViPBTm3/RhuB2oHNQmtYPUS0UZZLtAsk7Qay4s7KTemmEIGvav3Q6hQgGv2J/SDXMB1YZaS+Oai+BnCUNgFEwCvGJCmMskFW/sF6llpsKUYEYvPrugNg9DfIa+8t0wgJ8daV/+EEDDI6uXS0t74YAGb449u39Onny3rwvh00hiFufHFHV2aX9co7N4xPBzxfGDzUK2mILmaQINDrl0O98u5/Vaut0B4OrAl4LALDoXjkNxER6N3xdQVBD23hiAh4Oh0Y5vYKRAD8FQGur0EEwGcRQAAQAfBYBBAARAA8FgEEABEAj0UAAUAEwGMRCCVN81MjAuClCFwLJc3yMyMC4KUIVHslTSl6MADM8NiPtukn32+nuO9R7c6KpBqNtgX//OgL41uB44pADncMVnslnRcnARnjyUe269EH4hx8gQtoh+GhHdrT36vTF+YRAXOcDyvFwrykN+hiZohX/BCHnx/8GtMBg/P/SrFQracA5+leYDuFnXaEVjkRgbIUxYCVYqEs6RpdDMAbEfhKACJK/KwAXojA2fqV4asCELmA9/lZISmuzt1SdXbZ2GWgiEBHLDQO9s2Xt41LukhXBdOFXzz3+ZrLQgf6e3X8cF/iF4OkJQIOpQOn6qN/8xRA0WUBJAJgtPiPv/TZupuC5+Zvq/jnz3Xpoy9wAulxTU23f220rDpOtwVTnLkwv3ob0EZM/vU604H0KEWx/+YCENmDE3Rd6Ja5+RVd+bj1fP/Gl3dYE0iH6WidT1s5AEU2YYEuDN0JwO32pgmf3srV97ZUBEob/eGGAhDZBKYC0BXNNwJvxv49+ds9aZkInK1fBtquAyAWBAMC0KOD+3ZsKRKd3hSMCLTFQqvBfKu9lbgA6Ipjh/u1q8UW3uJj9+b6+1sgAqeaF/7aFgBiQeiW/QPbdPqJ3eucwEB/r04/sTu3o78lInCtUiyUWv0P7UzSxsXlodClCLz4+G7Nza9obv62du0MtX/Ar6cmM9ostKWD3/LxKmJBMLkmMDy0w7viz8gJTFeKhfNdC0B9HiFiQQCXRKCt9bu2BIBYEMApEThbKRaqxgQgEoGyOEEYMmSpxZZiRGCVhTiDddwjVkp0w9a89t4yjZAQf3n3Rq6+T0Ii0DL2ayao1eKdSDs6uVQWpwi35JEfrOhbfbSDSeaur+itK/k8nz/s2W4qHbhWKRaG4vyF3g7epCTpqCS6+Ca8/a8erdxcuhv9ALThBAxFhGOxxSfuX4hiwVP8bK3p2V5Q2LOdhoC0pgPTm+33NyoA9XmGOEQUEQCbRGCsk7/UkQBEiwwlfjJEAKwQgRcbj/lKwwEQCyICYIcILHQzGHd70wIuABGAbEWgFCf2ayZ2DNgMsWA8SAcg1gjdOiKMHfuZdgB1F8BzAjgBSN8JjHUtMN2+ALEgIgCZiEBHsV8SDkAiFkQEIG0RGDPxukYEgFgQEYBUReBEp7FfUg6AWBARgHREYNHklNv0heu4AEQAkuXZbmK/ZrqOAZshFuwcIkLYgg9nJvbeb/IFwwQ+ZEnEgjgBME+t9rTplzQuAMSCiACYJ1Dw5szvvvMP6wUgglgQEQCjChAeT+JlExEAYkFEAIyO/i9Mn9zzb2cEIBKBsogFEQHolkUF4e+TevEw4Q+PC0AEoDuenT6553pi7sJ0DNgMsaAZiAi95NLMxN6HknyDMIUvURKxIE4A4lOrJX4lX+ICQCyICEAH1lzBuSRivywcgEQsiAhAHBYVhM+n8UapCACxICIAsUb/M0nFflk5AGJBRADa45MkY7/MBCACF4AIQGtOJhn7rXMbSceAzRALmoeIMDckHvtl7QDqLoBYECcAzaQQ+2UuAMSCiABsYMVTiv1scAASsSAiAI0sKgiPZfHGmQhAFAuO87sjArAa+13P5L3TXgRsZHRyaUrSCF3APCwMOsMnMxN7v5vVm4cZf3lcAE7Ad57J8s0zFYBKsVCVdJY+gAh4yqWZib2veisADS6AWBAR8G/uH/Q8lfVnyFwAogVBYkFEwK/iV3Bu+uSey94LQCQCJRELIgL+kFnsZ6UANEwFABHwYfTPLPZb91myjAGbIRZMByLCTMk09rPZAeACcAL5p1Z73KaPY5UAEAsiAjnnUhb7/V1yAHUXQCyICORv7h/0WPcYvHUCQCyICOSy+BX8Ia1jvlx3AMSCiEDeWFQQPmfjBwstbjQWBBGBvDBhS+y3zpnYFAM2QyyYPkSExrEq9nPJAeACcALuY1ns55QAEAsiAo5jXeznmgOouwBiQUTAOWyM/ZwTAGJBRMDJ4lfwgo2xn4sOgFgQEXCNxTRv98m9ADRMBQARcIFnbY391jkVm2PAZogFs4WIsC0+nJnYe78rHzZ0rHFxATgBu6nVnnbp4zolAMSCiIDVdlrBm7bHfq47gLoLIBZEBCxUgPC4ax/ZOQEgFkQELB39nYj98uAAiAURAdtwJvbLhQA0TAUAEbABZ2K/dc7FpRiwGWJBe/A4Irw0M7H3IVc/fOh44+MCcALZUqudcPnjOy0AxIKIQKb2WcE512K/vDmAugsgFkQE0mZRQfi861/CeQEgFkQEMhr9z7gY++XRARALIgJp84mrsV8uBaBhKgCIQBqcdDX2W+dkXI4BmyEWtJOcRYROx355dgCSNEa54QQSxfHYL9cCUCkWZiW9SMkhAonY5RzEfnl3AJJUErEgImCeRQXhsbz9JrkTgCgWLFFuiIDh0f9MXhb+1nyvPC0CNjI6uTQraZCSsxPHFgatvt0HB7AxY5QZTsAQz+T1d8itA4hcwJSIBXEC3ZGr2M8nB4ALwAl0P0IGPU/luf1zLQBRLHiCMkMEOir+u8d8Xc5z2+d6CtAwFahKOkCpMR2IgVPn++MAWnNI7A3ACbTPYhD0HPGhzb0QgGhvACKACLRb/A/n4VFfBGCtCFQRAUSgzeK/7Etbhz51rAYR4OwARMD74vdOABpEYFjSNGWGCERcCoKeId+KX/IkBdiM0cmlcd19bqCPcrOXJNOBQMEL0xPf/o2vbRv63LEqxcKpyA1wsrBnTiBQcC4Ier7nc/F77wCa3MCQ7h4rNoYjyK0TWAwU/E1B+Lwvq/wIQGdicEjS0cgdDCMITovApUDB+zXVpmYm9r5KCyIAAMAaAAAgAAAIAAAgAACAAAAAAgAACAAAIAAAgAAAAAIAAAgAACAAAOAk/we2wJdT+a6iyQAAAABJRU5ErkJggg==",
"required_fields": [],
"params": [],
"supported_formats": ["json"],
"supported_formattings": ["unformatted"],
"supported_visualization_formattings": ["noapply"]
}]
}
"""
return response
form_url はアクション実行時になにか入力させたりしない場合は不要です。
このへんを参考に各フィールドを埋めます。
Cloud FunctionでエンドポイントをPythonとすると requirements.txt がデフォルトで作られますが、特に何も使わないので要りません。
Formの実装(シュッと終わるよ)
Listと同じ手順で、実装が違うだけです。
import json
def action_form(request):
convert_options = """
[{
"name":"hoge_id",
"label":"hogeプロジェクトのID"
},
{
"name":"label",
"label":"属性ラベル"
}]
"""
form = """
[{
"name":"convert_type",
"label":"変換タイプ",
"description":"IDから変換したい情報を選んでください。",
"type":"select",
"default":"no",
"required":true,
"options":""" + json.dumps(json.loads(convert_options)) + """
}]
"""
return form
この例ではLookerで抽出したユーザーIDを変換する先の選択肢をjsonで返しています。
この関数をデプロイしたら、「トリガー」タブにリクエストを投げるためのエンドポイントURLが出るので、一つ前のListの実装にある form_url に記載し、ListのCloud Functionを再度デプロイします。
ListのCloud Functionを再度デプロイするのは次のExecuteの実装後にも行うので、そちらとまとめて行ってもOKです。
こちらも requirements.txt は特に修正は要りません。
Execute の実装(ながいよ)
今回はCloud Runを使って実装していきます。
レスポンス時間とリクエストサイズがCloud Functionの上限に収まる場合は、ここもCloud Functionで実装してやればDockerfileも要りませんし非常に楽ちんです。
Dockerfileを書く
FROM python:3.8-slim
ENV APP_HOME /app
WORKDIR $APP_HOME
COPY . ./
# ここでGCPのライブラリをいれています。 Flaskやgunicornは次の手順で実装するものをウェブアプリとして動かすためのものです。
RUN pip install --upgrade Flask gunicorn google-cloud-core google-cloud-storage google-cloud-bigquery
CMD exec gunicorn --bind :$PORT --workers 1 --threads 8 --timeout 0 app:app
データの変換、出力処理を書く
特別な理由がない限り、以下で使用するGCSのバケット、BQ、Cloud Runのデプロイ先は同じリージョンになるようにしましょう。
別リージョンにすると料金が高くついたり、この通りの実装では動かないなどの悲しみが待っています。
Lookerから来たjsonを読んで一旦GCSに保存させる
def parse_request(request):
request_json = request.get_json()
# Formで選んだ変換タイプを取り出す
convert_type = request_json['form_params']['convert_type']
# LookerのExploreで出力したデータを取り出す
query_data = json.loads(request_json['attachment']['data'])
return convert_type, query_data
# Lookerのビュー名やフィールド名を排除し、2次元配列になっているidを1次元の配列にする
def remove_namespace(data):
ids = list(x["{LookerのフィールドID}"] for x in data)
return list(itertools.chain.from_iterable([x.split(",") for x in ids]))
# 来たリストを1要素1行になるようにしてストレージに書き出す
def output_ids(object_name, id_list):
# 1要素1行の、csvとして読めるようにする
str = '\n'.join(map(str, id_list))
gcs_client = storage.Client(PROJECT_NAME)
bucket = gcs_client.get_bucket(BUCKET_NAME)
blob = storage.Blob(object_name, bucket)
blob.upload_from_string(str)
GCSにあるファイルをBQに一時テーブルとして書き出す
def create_tmp(tmp_file, table_name, id_list):
# まずストレージに書き出す
output_ids(tmp_file, id_list)
# ストレージからテーブルを作成する
bq_client = bigquery.Client(PROJECT_NAME)
dataset_ref = bq_client.dataset(BQ_DATASET_NAME)
schema = [
bigquery.SchemaField('id', 'INTEGER'),
]
table = bigquery.Table(dataset_ref.table(table_name), schema=schema)
external_config = bigquery.ExternalConfig('CSV')
external_config.source_uris = [
'gs://' + BUCKET_NAME + '/' + tmp_file
]
table.external_data_configuration = external_config
bq_client.create_table(table)
bq_client.close()
一時保存したテーブルを読んでデータを変換、それらをテーブルとして保存GCSに吐き出す
def convert_and_output(full_tmp_table_name, full_table_name, table_name, convert_type):
# データ変換してテーブルとして保存させる
# select文でtmpテーブルとjoinしてデータを変換するクエリを書く
query = 'create table ' + full_table_name + """
as (
select """ + convert_type + """ from fugafuga
inner join """ + full_tmp_table_name + """ as tmp
on ...
)
"""
client = bigquery.Client()
client.query(query).result()
# テーブルに保存したものをcsvファイルとしてGCSに出力する
# GCS内のファイルパスを組み立てる ここはディレクトリ構造によって変わります
destination_uri = "gs://{}/{}/{}".format(BUCKET_NAME, convert_type, table_name + '.csv')
dataset_ref = bigquery.DatasetReference(PROJECT_NAME, BQ_DATASET_NAME)
table_ref = dataset_ref.table(table_name)
config = bigquery.ExtractJobConfig()
config.print_header = False
extract_job = client.extract_table(
source=table_ref,
destination_uris=destination_uri,
location='US',
job_config=config,
)
extract_job.result()
client.close()
不要なファイルやテーブルを削除
def delete_tmp(object_name, tmp_table_name, table_name):
bq_client = bigquery.Client()
query = 'drop table ' + table_name
bq_client.query(query).result()
query = 'drop table ' + tmp_table_name
bq_client.query(query).result()
bq_client.close()
gcs_client = storage.Client(PROJECT_NAME)
bucket = gcs_client.get_bucket(BUCKET_NAME)
blob = storage.Blob(object_name, bucket)
blob.delete()
全体像
ここまでできるとこんな感じの実装が出来上がります。
import google.cloud.bigquery as bigquery
import google.cloud.storage as storage
import os
import json
import itertools
from flask import Flask, request
import string
PROJECT_NAME = <GCPのプロジェクト名>
BUCKET_NAME = <GCSのバケット名>
BQ_DATASET_NAME = <BQのデータセット名>
app = Flask(__name__)
# 100MBまでリクエストを受け付ける via https://flask.palletsprojects.com/en/master/config/#MAX_CONTENT_LENGTH
app.config['MAX_CONTENT_LENGTH'] = 100 * 1024 * 1024
@app.route('/', methods=['POST'])
def main():
convert_type, query_data = parse_request(request)
data_to_stream = remove_namespace(query_data)
table_name = <何かしら一意になるようなテーブル名>
output(data_to_stream, convert_type, table_name)
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
def parse_request(request):
request_json = request.get_json()
# Formで選んだ変換タイプを取り出す
convert_type = request_json['form_params']['convert_type']
# LookerのExploreで出力したデータを取り出す
query_data = json.loads(request_json['attachment']['data'])
return convert_type, query_data
# Lookerのビュー名やフィールド名を排除し、2次元配列になっているidを1次元の配列にする
def remove_namespace(data):
ids = list(x["{LookerのフィールドID}"] for x in data)
return list(itertools.chain.from_iterable([x.split(",") for x in ids]))
# 来たリストを1要素1行になるようにしてストレージに書き出す
def output_ids(object_name, id_list):
# 1要素1行の、csvとして読めるようにする
str = '\n'.join(map(str, id_list))
gcs_client = storage.Client(PROJECT_NAME)
bucket = gcs_client.get_bucket(BUCKET_NAME)
blob = storage.Blob(object_name, bucket)
blob.upload_from_string(str)
# idのリストから変換先のidを引っ張ってきてファイル出力までする
def output(id_list, convert_type, table_name):
# 一連の流れで使うテーブル名、ファイル名を作る
tmp_file = 'tmp/' + table_name + '.csv'
full_table_name = '`' + PROJECT_NAME + '.' + BQ_DATASET_NAME + '.' + table_name + '`'
tmp_table_name = 'tmp_' + table_name
full_tmp_table_name = '`' + PROJECT_NAME + '.' + BQ_DATASET_NAME + '.' + tmp_table_name + '`'
# 一時保存するテーブルを作成する
create_tmp(tmp_file, tmp_table_name, id_list)
# データを変換してGCSに出力
convert_and_output(full_tmp_table_name, full_table_name, table_name, convert_type)
# 一時ファイルとテーブルを削除
delete_tmp(tmp_file, full_tmp_table_name, full_table_name)
# idのリストをテンポラリテーブルに一時的に書き出す
def create_tmp(tmp_file, table_name, id_list):
# まずストレージに書き出す
output_ids(tmp_file, id_list)
# ストレージからテーブルを作成する
bq_client = bigquery.Client(PROJECT_NAME)
dataset_ref = bq_client.dataset(BQ_DATASET_NAME)
schema = [
bigquery.SchemaField('id', 'INTEGER'),
]
table = bigquery.Table(dataset_ref.table(table_name), schema=schema)
external_config = bigquery.ExternalConfig('CSV')
external_config.source_uris = [
'gs://' + BUCKET_NAME + '/' + tmp_file
]
table.external_data_configuration = external_config
bq_client.create_table(table)
bq_client.close()
# tmpテーブルと照らし合わせてデータを変換する
def convert_and_output(full_tmp_table_name, full_table_name, table_name, convert_type):
# データ変換してテーブルとして保存させる
# select文でtmpテーブルとjoinしてデータを変換するクエリを書く
query = 'create table ' + full_table_name + """
as (
select """ + convert_type + """ from fugafuga
inner join """ + full_tmp_table_name + """ as tmp
on ...
)
"""
client = bigquery.Client()
client.query(query).result()
# テーブルに保存したものをcsvファイルとしてGCSに出力する
# GCS内のファイルパスを組み立てる ここはディレクトリ構造によって変わります
destination_uri = "gs://{}/{}/{}".format(BUCKET_NAME, convert_type, table_name + '.csv')
dataset_ref = bigquery.DatasetReference(PROJECT_NAME, BQ_DATASET_NAME)
table_ref = dataset_ref.table(table_name)
config = bigquery.ExtractJobConfig()
config.print_header = False
extract_job = client.extract_table(
source=table_ref,
destination_uris=destination_uri,
location='US',
job_config=config,
)
extract_job.result()
client.close()
# テンポラリテーブルとファイルの削除
def delete_tmp(object_name, tmp_table_name, table_name):
bq_client = bigquery.Client()
query = 'drop table ' + table_name
bq_client.query(query).result()
query = 'drop table ' + tmp_table_name
bq_client.query(query).result()
bq_client.close()
gcs_client = storage.Client(PROJECT_NAME)
bucket = gcs_client.get_bucket(BUCKET_NAME)
blob = storage.Blob(object_name, bucket)
blob.delete()
Cloud Buildを使ってCloud Runにデプロイ&ビルド
Executeの実装ファイルがあるディレクトリで下記コマンドを実行し、コンテナを作成します。
実行時のオプションは他にもあるので、こちらを参照してください。
自分のローカルから実行する場合はgcloudコマンドをインストールしましょう。
gcloud builds submit --tag gcr.io/<GCPプロジェクト名>/<任意のサービス名>
作成したコンテナを使ってCloud Runにデプロイ&ビルドします。
メモリやリージョンの指定は皆様の環境に合わせて変えてください。実行時のオプションは他にもあるので、こちらを参照してください。
gcloud run deploy --image gcr.io/<GCPプロジェクト名>/<任意のサービス名> --platform managed --memory 2.0G --region us-central1
Cloud Runでの起動時のサービス名を聞かれるので、特にこだわりがなければそのままエンターを入力します。
最後に未認証のアクセスを許可するか聞かれる場合があるので、許可する方を選びます。あとからGCPコンソールで変更できます。
デプロイが完了したら下記のような表記がコマンドライン上に表示されるので、最後にかかれているURL部分をListの実装にある url に記載し、Cloud Functionを再度デプロイします。
Deploying container to Cloud Run service [<サービス名>] in project [<GCPプロジェクト名>] region [us-central1]
✓ Deploying new service... Done.
✓ Creating Revision...
✓ Routing traffic...
Done.
Service [<サービス名>] revision [<ビルドバージョン名>] has been deployed and is serving 100 percent of traffic at https://<サービスごとにユニークなやつ>.a.run.app
またGCPコンソールにてこのCloud Runのサービスの詳細を開くと「URL」としてリクエストを投げるエンドポイントのURLが得られるので、コマンドラインに出てきたURLを控えそこねた場合はそちらから拾ってもOKです。
つくったアクションをAction Hubに追加する
手順2で作成したListのCloud Function関数の、「トリガー」タブにあるURLを拾ってきます。
Lookerの「管理」->「Platform」->「Actions」からAction Hubを開きます。
一番下までいくと、「Add Action Hub」って書いたボタンがるのでそこを押して、表示されるフォームに先程拾ってきた「List」のURLを入力します。

登録に失敗したら下記のようにめっちゃ怒られます。

失敗するときは手順2, 3のCloud Functionのレスポンスjsonが狂っているとか、そもそもレスポンスを返せていないとかが原因なので、きれいな眼で自分の実装と設定を見直しましょう。
Executeの中の実装がバグっていてもLookerはチェックしてくれない(というかそこまではできない)ので、この段階では実装を書いた自分を信じて、ListとFormだけを見直しましょう。
成功したら下記のように「Enabled」と出ます。

動かしてみて喜ぶ
ここまでくれば、Exploreでフィルタ指定してID抽出、アクションポチっとすれば、GCSにファイルが保存されているはずです。
Exploreでポチポチして、動いた、わーいって喜びましょう。
動かない場合はExecuteの実行が失敗したよとLookerからメールが届くと思うので、手順4のExecuteの実装を見直しましょう。
またはアクションで投げたリクエストのサイズがCloud Runの上限(32MB)を超えている可能性があるので、少し小さいリクエストで検証するなどしましょう。
まとめ
最後まで読んでいただいてありがとうございます。
1つの記事に書くボリュームじゃないな?と自分で反省しています。本当に全部読んでいただいた方ありがとうございます!
ということで、今回はLookerをDMPツールとして使うべく、GCPを使ってカスタムアクションを実装しました。
今回はGCSに保存しましたが、実装を書き換えれば別の出力先にも対応出来ますし、保存と同じタイミングでCloud Pub/Subに「ファイル吐き出したよ!」みたいなメッセージを登録させて、さらにデータパイプラインを構築したりもできます。
LookerもGCPの仲間なので全部Google世界でできてしまうのですね。巨人すごい。
ということでトテモトテモ長い記事になりましたが、同じような感じで大量のデータを扱いたいとか、Lookerでデータ抽出したあとにデータ変換して色々したいっていう人の参考になれば幸いです。
それでは良いクリスマスを!ハッピーホリデー! ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()