AmiVoice概要
公式ページを適宜抜粋しております。
AmiVoiceの特徴
- 音声認識市場シェアNo.1の音声認識エンジンを開発者に提供
- 特に日本語に対する高い認識精度
- ノイズに強い
- 街中、工場でも認識可能
- 国内での開発&運用
- お客様音声データの海外流出はない
- 専門用語に特化したエンジンを複数用意
- 医療、金融、保険など業界特有用語の認識精度が高いエンジンも用意
提供タイプ
- AmiVoice API (共用サーバ利用型)
- 従量課金制のクラウド音声認識API
- さくっと始めるならまずはこれ(毎月60分程度の無料枠も有)
- 本記事で取り扱うのはこれのみ
- AmiVoice API Private (専用サーバー構築型)
- オンプレ環境で利用する音声認識API
- AmiVoice SDK (端末組み込み型)
- オフラインで使える音声認識エンジン
提供タイプ間の詳細な違いについては公式ページ参照ください
認識精度を試してみる
公式ページの下部の認識精度を試すでマイクからの入力に対する音声認識を実際に確認することができます。

APIの種類
同期、非同期、WebSocketが用意されています。
マイページに使用するエンジンとの対応表が用意されており、非常にわかりやすい印象を持ちました。
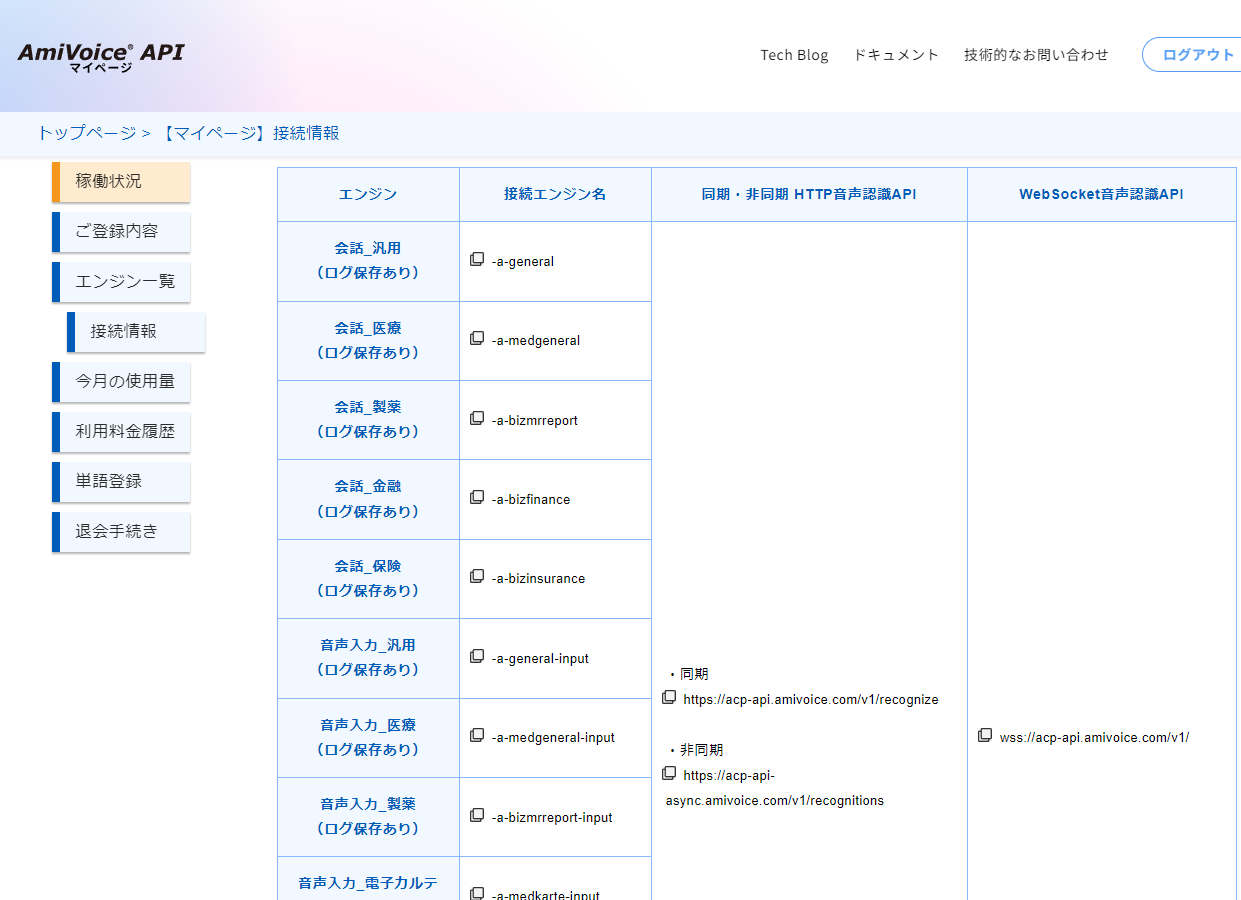
AmiVoice API試してみた
音声ファイルは公式ページを参考に、test.wavを使用します。
以下パラメータで試します。
- エンジン:
会話_汎用 - API:
同期API
example.py
import requests
# AmiVoiceのAPIキーを設定(マイページで確認できます)
APP_KEY = "XXXXXXXXXXXXXXXXX"
# 認識対象の音声ファイルパス
AUDIO_FILE = "test.wav"
# エンドポイントのURL
URL = "https://acp-api.amivoice.com/v1/recognize"
# 音声ファイルを開く
with open(AUDIO_FILE, "rb") as f:
audio_data = f.read()
# リクエストのパラメータを設定
params = {
"d": "-a-general"
}
files = {
"u": (None, APP_KEY),
"a": ("test.wav", audio_data)
}
# POSTリクエストを送信
response = requests.post(URL, params=params, files=files)
# レスポンスを処理
if response.status_code == 200:
result = response.json()
print("認識結果:", result["text"])
else:
print("エラー:", response.status_code, response.text)
$ python3 example.py
認識結果: アドバンスト・メディアは、人と機械との自然なコミュニケーションを実現し、豊かな未来を創造していくことを目指します。
非常に短いコードかつ正確な文字起こしができました。
今回はpythonでAPIを直接たたきましたが、python含めいくつかの言語ではクライアントライブラリが用意されているそうです。
https://docs.amivoice.com/amivoice-api/manual/client-library/sample-programs
こちらも今後試していきたいと思います。