Pythonデータ分析認定試験の合格を目指し
公式テキストを元に学習しているが表題の部分で詰まった
この記事でやってること
・データフレームをOneHotEncodingしたよ
・上記のエンコード済のデータをデータフレーム型に戻してカラム名を表記したよ
環境
python : 3.9.4
scikit-learn : 0.24.2
numpy : 1.20.2
エラーの経緯
教本p219を参考に以下のデータフレームを作成
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': np.arange(1,6),'B': ['a','b','c','b','c']})
df
sklearnを使って、B列のa,b,c,d,eでOneHotEncodeする
(文字列変数を数値データに変換したい)
# データフレームのカテゴリ変数を数値化したい
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
# defaultでdeep=trueなので、深い複製
df_ohe = df.copy()
# ラベルエンコーダーをインスタンス化
le = LabelEncoder()
# B列の値を数値化
df_ohe['B']=le.fit_transform(df_ohe['B'])
ohe = OneHotEncoder(categorical_features=[1])
ohe.fit_transform(df_ohe.toarray())
以下のエラーが発生
TypeError: __init__() got an unexpected keyword argument 'ColumnTransformer'
先生、LabelEncodingとOneHotEncodingの違いからわからないです。。。
ということでまとめました。
エンコーダーの公式ドキュメントも確認してね
Labelエンコーダー###
文字列の項目を数値に変換
イメージ
# LabelEncoding
# ①このようなモデルを作って
ラベル : [りんご,ごりら,らっぱ]
ラベルID : [1,2,3]
# ②この配列を作る
[ごりら,ごりら,らっぱ]
# ①ラベルを適用してLabelEncoding
[2,2,3]
OneHotエンコーダー###
文字列の項目の有無を0,1で新しい列を作成
# OneHotEncoding
# ①このようなモデルを作る
A:[0,1,2,3,4]
B:[a,b,c,d,e]
# ②このモデルをOneHotencoding
A:[0,1,2,3,4]
B_a:[1,0,0,0,0]
B_b:[0,1,0,0,0]
B_c:[0,0,1,0,0]
B_d:[0,0,0,1,0]
B_e:[0,0,0,0,1]
# 列の項目のカテゴリ別に0,1の配列が作成される
# このように0が多い行列を疎行列という(<>密行列)
本題
このエラーはなんだったのか#####
# エラー
TypeError: __init__() got an unexpected keyword argument 'ColumnTransformer'
原因
教本の環境が今のバージョンと異なっており、OneHotEncoderの仕様が変わり
categorical_featuresはバージョン0.22で排除済だった
# 教本
scikit-learn===0.19.1
# 使用する環境
scikit-learn===0.24.2
よって公式例を参考にして以下でOneHotEncodingを実践しました
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
# データフレーム作成
import numpy as np
df = pd.DataFrame({
'A': np.arange(1,6),
'B': ['a','b','c','b','c']
})
df_ohe = df.copy()
# 特に引数はいらないみたい
ohe = OneHotEncoder()
ohe.fit_transform(df_ohe).toarray()
結果はscipy.sparse型の行列なので人間の私にはわかりにくい
ちなみにOneHotEncodingのインスタンス時に'sparse = False'にするとNumpy.ndarrayの一次元配列になる
array([[1., 0., 0., 0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0., 0., 0., 1.],
[0., 0., 0., 1., 0., 0., 1., 0.],
[0., 0., 0., 0., 1., 0., 0., 1.]])
カラム名のつけたデータフレーム型に変換して表示してみた###
OnehotEncode型のデータを複数のカテゴリ名を持つデータフレームに変換する仕方がわからなかったので、ここではカテゴリが一つの配列をOneHotEncodingした疎行列データをデータフレームに変換します。
# データの準備
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': np.arange(1,6),
'B': ['a','b','c','b','c']
})
# OneHotEncoderのインスタンス化
ohe = OneHotEncoder()
# yにデータフレームのB列のndarray型の配列を代入
y = df.B.values
# yを5行1列にしたものをOneHotEncoding
# OneHotEncodingは二次元以上の配列しかできないので元々1次元のyを変換する必要があった
ohe.fit(y.reshape(-1,1))
# OneHotEncodingしたoheインスタンスをtransformでコミットしたcsr.csr_matrix型のデータをy_dataに代入
y_data = ohe.transform(y.reshape(-1,1))
# DataFrame型で再定義
# 引数のデータにはy_dataをndarray型に変換したもの
# 引数のカラム名はOneHotEncoder型のデータoheがCategories_として保持しているもの
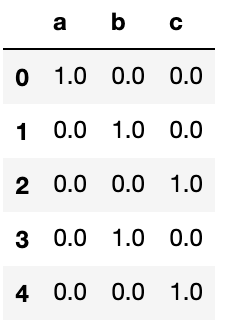
y_df = pd.DataFrame(y_data.toarray(),columns=ohe.categories_)
y_df
結果
なんとかOneHotEncodeしたデータをカラム名をつけて表現できた。
今後調べること####
①
疎行列で(5,1)の構造であるcsr.csr_matrix型のデータをtoarray()関数でndarray型にしたら、(5,3)の構造になったのは何故か
②
エンコード方法は調べただけでも沢山存在しているらしく、他にはどんなエンコードがどんな状況で使われるのか