Glue connectionについて
Glueにはconnection(接続)という機能があります。JDBCで接続するデータベースやDynamoDBなどの接続を管理する機能になります。
ここではJDBCでAurora PostgreSQLへのconnectionを作成してGlueジョブから接続をしてデータを取得する場合に、どのようなクエリをデータベースに対して発行しているかなどの内部動作を確認していきます。
Glueジョブからconnectionを利用する
Glueクローラなどからconnectionを利用してGlueデータカタログにテーブルを作成できます。
以下の画面はクローラから作成されたテーブルになります。
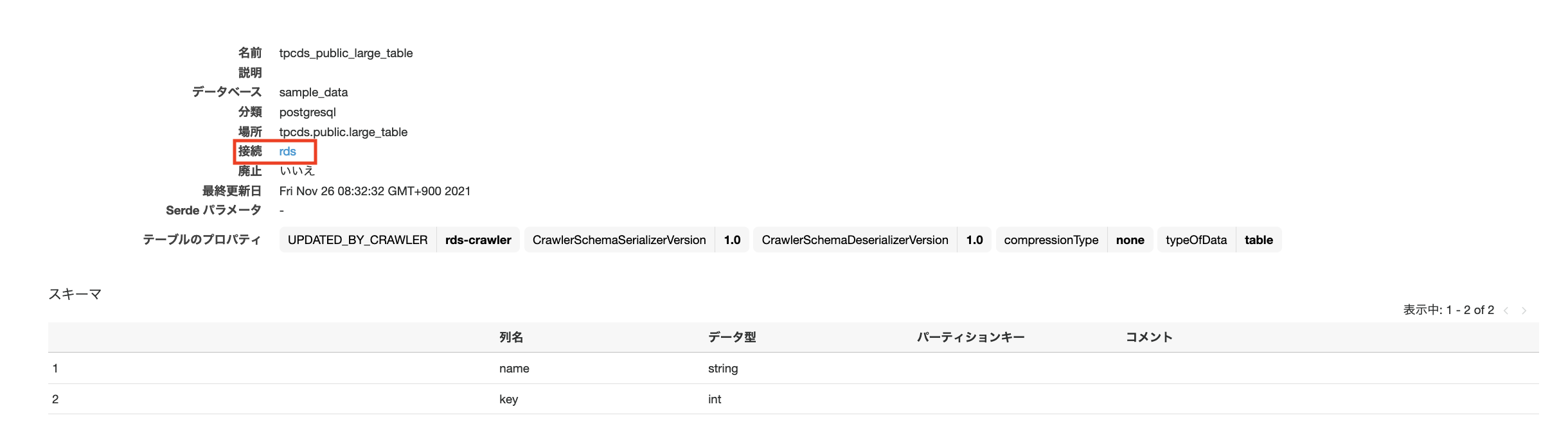
Glueジョブからは作成されたテーブルを指定することで、connectionを利用してデータを読み込みDynamicFrameを作成できます。
df = glueContext.create_dynamic_frame.from_catalog(
database = "sample_data",
table_name = "tpcds_public_large_table",
transformation_ctx = "my_transformation_context",
additional_options = { 'hashfield': 'key', 'hashpartitions': '10' } )
additional_options に指定されているオプションは並列読み取りを行うオプションになります。
並列読み取りについて
additional_options でオプションを指定しない場合はGlueは単発のクエリをデータベースに対して実行することでデータを取得します。
並列読み取りは特定のカラムの値をハッシュして、その値をmodして分割することで並列に読み取りを行います。
どのカラムをハッシュするかが、additional_optionsに指定されているhashfield、並列数がadditional_optionsに指定されているhashpartitionsになります。
上記の例ではkeyというカラムでハッシュを行い、並列数10で読み取りを行うことになります。
並列読み取りを行う場合のデータの偏りをなくすために、hashfieldにはプライマリキーなどユニーク値の数が多いカラムを指定するのがポイントです。
connectionの動作を確認する
GlueContext.create_dynamic_frame.from_catalog を実行したときにどのようなクエリがデータベースに対して発行されるか確認します。
- まずは
hashfieldに設定されたカラムの最大値を確認するために以下のクエリを実行します。最大値は実際のデータ取得を行うクエリを実行する際のフィルタ条件として指定されます。SELECT * FROM (select key from "public".large_table order by key DESC LIMIT 1) as large_table - 次に実際のデータ取得クエリに
WHERE 1=0を付加したクエリを実行します。WHERE 1=0が付加されているので何も実行結果は返されません。おそらくデータベース側の障害など予期せぬエラーを早期に検知するために実行しているものと思われます。SELECT * FROM (select * from "public".large_table WHERE ABS(('x'||SUBSTR(MD5("key"::TEXT), 25, 8))::BIT(32)::INT) % 10 = 0 AND ((key <= '20971520'))) as large_table WHERE 1=0 - 実際のデータ取得クエリを実行します。
hashfieldに指定したカラム(この例だとkeyカラム)をMD5でハッシュするなどして%でMODを計算します。この例だと10でMODを行なっていますが、hashpartitionsで指定した値に応じて変わります。MODの値と0,1...9を比較する条件と最大値でフィルタする条件(この例だとkey <= '20971520')でクエリを実行していきます。SELECT * FROM (select * from "public".large_table WHERE ABS(('x'||SUBSTR(MD5("key"::TEXT), 25, 8))::BIT(32)::INT) % 10 = 0 AND ((key <= '20971520'))) as large_table SELECT * FROM (select * from "public".large_table WHERE ABS(('x'||SUBSTR(MD5("key"::TEXT), 25, 8))::BIT(32)::INT) % 10 = 1 AND ((key <= '20971520'))) as large_table ... SELECT * FROM (select * from "public".large_table WHERE ABS(('x'||SUBSTR(MD5("key"::TEXT), 25, 8))::BIT(32)::INT) % 10 = 9 AND ((key <= '20971520'))) as large_table
実際のデータ取得クエリのAurora PostgreSQLでの実行計画は以下となります。インデックスを使えるクエリではないのでインデックススキャンではなく、シーケンススキャンになります。そのため、hashpartitionsで設定した数だけテーブルの全件スキャンが発生するため、データベース側の負荷には注意が必要です。
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..475645.71 rows=104856 width=8)
Workers Planned: 2
-> Parallel Seq Scan on large_table (cost=0.00..464160.11 rows=43690 width=8)
Filter: ((key <= 20971520) AND ((abs(((('x'::text || substr(md5((key)::text), 25, 8)))::bit(32))::integer) % 10) = 0))
(4 rows)
以上がGlueジョブがconnectionを利用してデータベースからデータを取得する方法になります。