はじめに
皆さん、競馬、楽しんでますか?(笑)
昨年7月に「大井競馬で帝王賞を機械学習で当てた話」という記事を見て「面白そうだな〜」と思っていたものの、本業(?)の競馬の方で忙しくて(?)なかなか手を付けられずにいたのですが、11月後半以降の北海道での平地競馬のオフシーズンに合わせて、ホッカイドウ競馬の予想モデルを私もKerasで作ってみることにしました。
問題の設定
前述の帝王賞の記事と同様、シンプルに1着のみを予想することにしています。
データの収集
JBISサーチからスクレイピングしてデータ収集させていただきました。
特に具体的なコードはここでは示しませんが、requests.getを使って取得したHTMLからBeatifulSoupを使って必要な情報を抜き出す…という地道な作業になります。
取得対象はホッカイドウ競馬の開催場である門別競馬場の2015年〜2017年のレースを訓練データ、2018年のレースを検証データとしました。
2015年からを対象としたのは、2015年から内回りコースが新設されたため、この前後でレースの傾向が変わってきている可能性があるためです。
また、過去の戦績から予想を行うということから、フレッシュチャレンジ(新馬戦)は対象から外しました。
入力
基本的に帝王賞の記事と同様としていますが、1項目追加しています。
- 頭数
- 獲得賞金金額
- 順位
- 当日のレースの長さとの差
- 人気
- 体重
- タイム(秒)
- 門別競馬場かどうか
- 馬場状態が当日と同じか
- ダートコースかどうか <- 追加項目
ダートコースかどうかを追加したのは、いつぞやのフェブラリーSのように、芝馬が1番人気になって大敗…みたいなのを避けやすくなるのではないか…という意図です。
これを1頭ごとに過去10レース分、門別競馬場のフルゲートが16頭なので、
10項目 * 10レース * 16頭 = 1,600項目
を入力とするようにしました。
なお、過去10レースのうち、出走取消、競走除外、競走中止のレースがあった場合は、それをなかったこととして最大10レースとしています。
過去10レースに満たないところは0埋め。また、フルゲートに満たない場合はその箇所も0埋めとしています。
モデルの作成
ほぼ前述の帝王賞の記事と同様…
"""モデルの作成."""
from argparse import ArgumentParser
import matplotlib.pyplot as plt
from keras.layers import Dense, Dropout
from keras.layers.normalization import BatchNormalization
from keras.models import Sequential
from keras.optimizers import Adam
from utility import read_data
def main():
"""メイン関数."""
parser = ArgumentParser()
parser.add_argument('traincsv')
parser.add_argument('testcsv')
parser.add_argument('outfile')
parser.add_argument('-e', '--epochs', type=int, default=100)
args = parser.parse_args()
x_train, y_train, _ = read_data(args.traincsv)
x_test, y_test, _ = read_data(args.testcsv)
model = Sequential()
model.add(Dense(1600, activation='relu', input_dim=1600))
model.add(Dropout(0.8))
model.add(BatchNormalization())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Dense(16, activation='softmax'))
model.summary()
adam = Adam()
model.compile(loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=args.epochs,
batch_size=50, validation_data=(x_test, y_test)
)
_plot_history(history)
loss, accuracy = model.evaluate(x_test, y_test, verbose=1)
print("Accuracy = {:.2f}".format(accuracy))
print("Loss = {:.2f}".format(loss))
model.save(args.outfile)
def _plot_history(history):
# 精度の履歴をプロット
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.show()
# 損失の履歴をプロット
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'], loc='lower right'):frowning2:
plt.show()
if __name__ == "__main__":
main()
epochを100としたときの学習状況です。
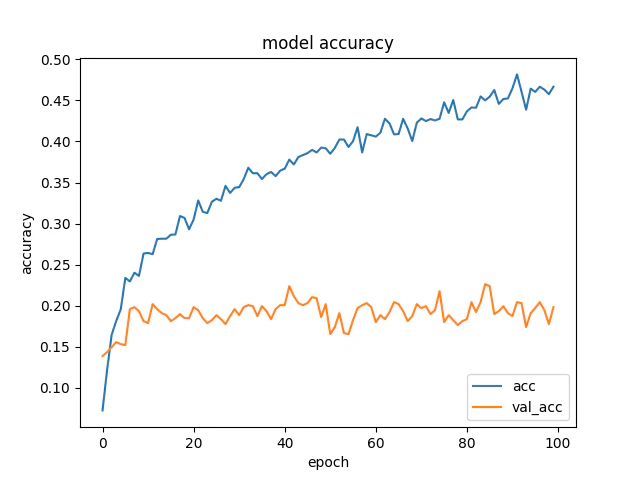
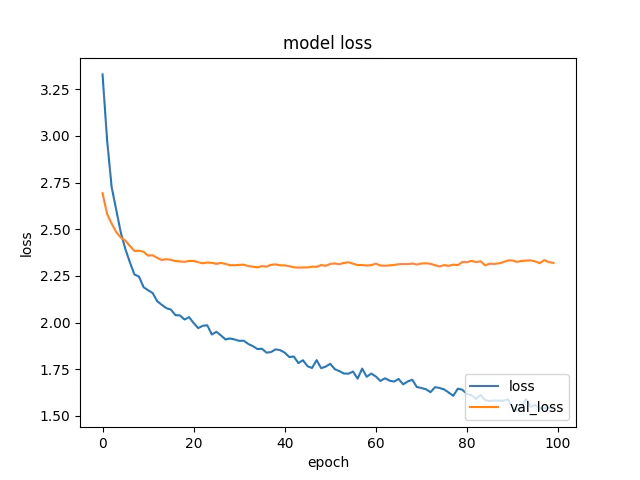
だいたい30あたりがval_lossの底に見えるので、モデルはepochを30としたときのものを使うことにします。
検証
2015〜2017年のデータを使って学習したものを2018年のレースを使って実際に予想してみました。
| 項目 | |
|---|---|
| 予想対象レース | 822 |
| 単勝的中レース | 159レース (19%) |
| 単勝回収率 | 67% |
サイコロを振って単勝を買ったとしても80%回収に収束するはずなので、それ考えるとちょっと残念な結果になっています。
的中率に関しては19%、サイコロ振るよりは的中率は高そうです。
実は9月の北海道胆振東部地震による中断までは84%程度の回収率になっていたのですが、9月下旬に再開した後、一気に回収率が下がってしまっています。
地震の前後で1着にくる馬の傾向が変わったのか、それとも単勝馬券のオッズ傾向が変わったのか、単純に秋以降の番組の影響か…まではわかりませんが、とにかく時期的に9月を境に何か傾向に違いが出たようです。
振り返り
初めて機械学習というものに触れましたが、ロジックを考えるでもなく、過去のデータから予想を組み立てられる、というのはすごい世界だな…と実感しました。
機械学習に触れる機会を作ってくれた「大井競馬で帝王賞を機械学習で当てた話」の記事には感謝です。
今後ですが、以下を対応していきたいと考えています。
- 馬体重に関して、現状は例えば500kgだったら500という絶対値で扱っていますが、当日との比べての増減にするほうがいいかも…
- 斤量に関しては考慮していないので、それも入力に加えたい(これも当日との比較かな)
- フレッシュも予想できるようにしたい。そのためには能検の結果を遡って入手しないと…それと騎手、血統とかも入力にする必要がありそうだけど、変数の量が膨大になりそう…
- 9月前後での傾向の差異を分析したい。もし例年秋競馬で傾向が変わっているのであれば、番組の影響や、秋になると中央や南関東へ2歳馬が移籍していく影響とか…あるかもしれないので、そこを境目に予測に使用するモデルを変える必要があるのかも…
最後に
競馬もコンピュータを使って快適に楽しみましょう!(笑)
追記 (2019/04/22)
明日、今年のホッカイドウ競馬では最初の重賞、コスモバルク記念が行われます。天気予報的におそらく良馬場での実施と想定して、今回のモデルで予想してみました。
| 馬番 | スコア |
|---|---|
| 1 | 0.4173926 |
| 2 | 0.0566063 |
| 3 | 0.0633162 |
| 4 | 0.1345231 |
| 5 | 0.0428528 |
| 6 | 0.0234721 |
| 7 | 0.1991264 |
中央から移籍初戦のスズカリバー、一昨年の道営記念勝ち馬ステージインパクト、昨年のホッカイドウ競馬の主役スーパーステションあたりが上位評価ですが、どうなることやら(笑)