今日のテーマは、「過去の気象データを使った気温予測」です。
題材
過去10年分の気象データを使って、ある日の気温を予測したいと思います。
気象データは、気象庁のサイトに公開されているので、このデータ(csvファイル)をダウンロードして使いましょう。
気象庁のサイト
↑をクリックし、まずは、「拠点を選ぶ」で[埼玉]→[越谷]を選択してください。
続いて「項目を選ぶ」でデータの種類:日別値、項目として日平均気温を選択してください。

続いて「期間を選ぶ」で 2009年1月1日~2018年12月31日 を指定してください。
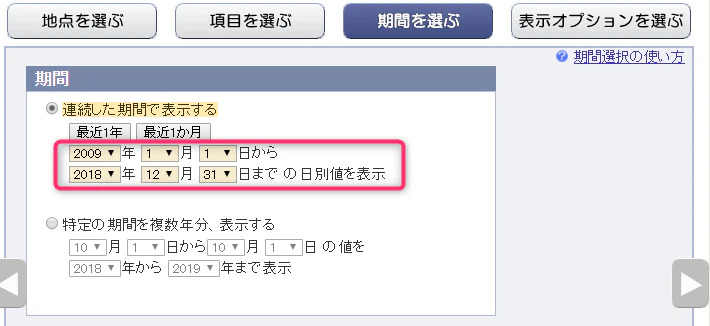
指定した内容が正しいことを確認したうえで[CSVファイルをダウンロード]ボタンを押下してください。

ファイル名は、「data.csv」として、C:\ml-introの直下に保存してください。
データを見てみよう
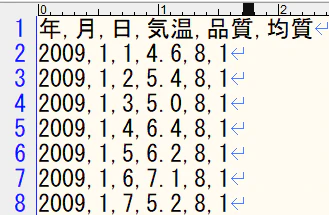
「data.csv」をテキストエディタで開くと↓のようになっていますね。
邪魔なヘッダ行もあったりして、このままでは使えそうにないので、加工して使いましょう。

「data.csv」を学習に使えるデータへ加工し、「koshigaya_kion.csv」という別のファイル名で保存する。
#
# ダウンロードした「data.csv」を学習に使えるデータへ加工し、「koshigaya_kion.csv」という別のファイル名で保存
#
in_file = "data.csv"
out_file = "koshigaya_kion.csv"
# CSVファイルを読み込む
with open(in_file, "rt", encoding="Shift_JIS") as fr:
lines = fr.readlines()
# 先頭から5レコード分を削除し、新たな行ヘッダをつける
lines = ["年,月,日,気温,品質,均質\n"] + lines[5:]
# / を , に置換している(年、月、日をカンマで分離するため)
lines = map(lambda v: v.replace('/', ','), lines)
# joinで改行付きの全レコードを結合したあと、stripメソッドで最終レコードの改行だけを取り除く
result = "".join(lines).strip()
# 加工された結果を out_file で指定したファイル名で出力する
with open(out_file, "wt", encoding="utf-8") as fw:
fw.write(result)
print("saved.")
加工後のファイル(ファイル名:koshigaya_kion.csv)
ゴールまでのステップ
- 「koshigaya_kion.csv」を読み込む。
- 訓練用データ(2009~2017年)とテスト用データ(2018年)を作成する。
- 訓練用データを使って学習させる。
- テスト用データを与え、2018年(1年分)の気温を予測する。
- 「予測した結果」と「2018年の正解」をグラフにプロットし、結果の精度を見てみる。
学習に使うアルゴリズムは、線形回帰を使います。
[参考情報]https://engineers.weddingpark.co.jp/?p=872
ここからが本題! 機械学習プログラムを書いてみよう
######## 必要なライブラリをインポート
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
######## 1. 「koshigaya_kion.csv」を読み込む。
# 平均気温データ(越谷市 2009年1月~2018年12月までの10年分)の読み込み
temper_data = pd.read_csv('koshigaya_kion.csv', encoding="utf-8")
######## 2. 訓練用データ(2009~2017年)とテスト用データ(2018年)を作成する。
# 元データを訓練用(9年)とテスト用(1年)に一旦分離
train_year = (temper_data["年"] <= 2017) # 2017年までを訓練用
test_year = (temper_data["年"] >= 2018) # 2018年以降をテスト用
interval = 6
# 過去6日分(説明変数) と その翌日(目的変数) をセットとした訓練用データを9年分作る
def make_data(data):
x = [] # 説明変数
y = [] # 目的変数
temps = list(data["気温"])
for i in range(len(temps)):
if i < interval: continue
y.append(temps[i])
xa = []
for p in range(interval):
d = i + p - interval
xa.append(temps[d])
x.append(xa)
return (x, y)
train_x, train_y = make_data(temper_data[train_year]) # 訓練用データ
test_x, test_y = make_data(temper_data[test_year]) # テスト用データ
######## 3. 訓練用データを使って学習させる。
lr = LinearRegression(normalize=True)
lr.fit(train_x, train_y)
######## 4. テスト用データを与え、2018年(1年分)の気温を予測する。
pre_y = lr.predict(test_x)
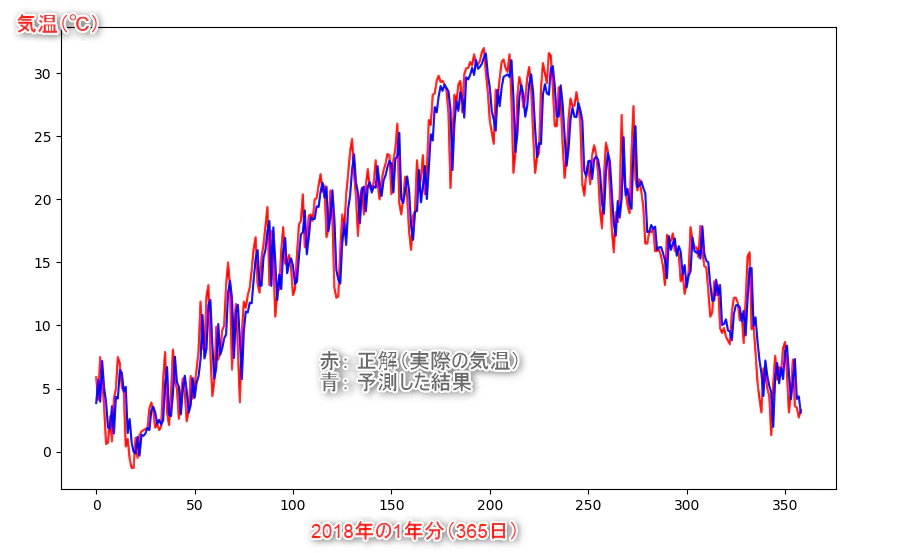
######## 5. 「予測した結果(青)」と「2018年の正解(赤)」をグラフにプロットし、結果の精度を見てみる。
plt.figure(figsize=(10, 6), dpi=100)
plt.plot(test_y, c='r')
plt.plot(pre_y, c='b')
plt.savefig('tenki-kion-lr.png')
plt.show()
青と赤のラインがそんなに大きくは離れていないですね!
まとめ
今回は、実際の気象データをもとに「回帰分析」による未来の気温予測をしてみました。
次回は、もうちょと業務のデータを扱ってみたい、、、 検討中!