今日のテーマは、「手書きの数字を判定する機械学習プログラム」です。
このプログラムを通じて、機械学習の雰囲気を感じましょう。
題材
手書きの数字画像を認識するプログラムです。
学習に使うデータは、scikit-learn(サイキット・ラーン)に付属しています。
scikit-learnは、機械学習に必要な分類、クラスタリングなどのアルゴリズムを備えている有名な機械学習ライブラリです。
コードを書く前に「特徴量」について理解しよう
まず、機械学習を行うためには、分析データの特徴を定量的に表現した 特徴量 と呼ばれる数値を抽出する必要があります。
この特徴量の選び方が精度(判断、識別、予測)に大きく影響します。
例えば、「金貨が本物か? 偽物か? を判定する」で特徴量を説明してみます。
この場合、「重さ」「体積」が判定に使う”特徴”であり、数値で表すことができるものです。
これを「特徴量」と呼び、2つの特徴量を抽出したことになります。
そして、この 特徴量を順番に格納したベクトル (重さ, 体積) を 特徴ベクトル と呼びます。
特徴がn個あれば、特徴ベクトルは、n次元ベクトルになります。
また、正解データは、「正解ラベル」と呼ばれる判定結果(本物/偽物のいずれか)と 特徴ベクトル をペアにしたものです。
scikit-learnに付属している「digits」という手書き数字データ
digitsには、「実際の画像データ」「正解データ」「まだ判定されていない特徴量データ」など、必要なものが用意されているので、これを使いましょう。
Python仮想環境を有効化し、「jupyter notebook」をdigitsの中身を覗いてみましょう。
$ cd C:\ml-intro
$ env\Scripts\activate.bat
$ jupyter notebook
notebookを開いて、ライブラリをインストールしましょう。
!pip install sklearn
まずは、digitsをロードし、何が含まれているか?確認してみます。
from sklearn import datasets
# digitsというデータセットをロード
digits = datasets.load_digits()
# digitsの中身(要素)を一覧表示
dir(digits)
実行結果は、こんな感じです。

<digitsに含まれているもの>
| digitsの要素 | 要素の内容 |
|---|---|
| DESCR | digitsの説明 |
| data | 特徴量データ |
| images | 画像(8×8=64ドットの画像) |
| target | 正解ラベル |
| target_names | ラベル(正解の文字)(0,1,2,3,4,5,6,7,8,9) |
次のコードを実行すると、要素の内容を具体的に確認できますのでやってみてください。
print('--- DESCR(digitsの説明) ---')
print(digits.DESCR)
print('--- data(特徴量データ)---')
print(digits.data)
print('--- images(画像)---')
print(digits.images)
print('--- target(dataと同じ並びの正解ラベル)---')
print(digits.target)
print('--- target_names(ラベル(正解の文字))---')
print(digits.target_names)
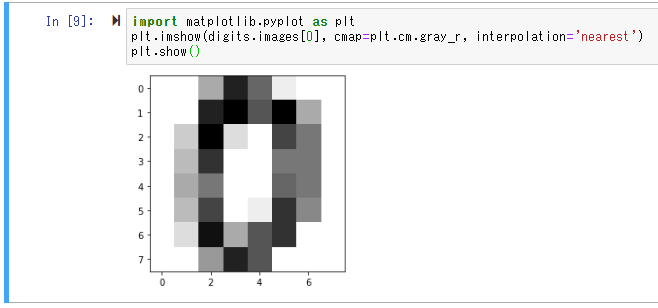
では、実際の手書き画像を見てみましょう。
import matplotlib.pyplot as plt
plt.imshow(digits.images[0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
実行結果は、こんな感じです。(1つ目は、ゼロっぽいですね。)
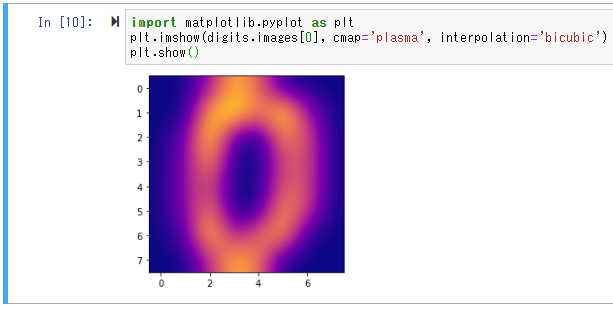
imshowメソッドの呼び方を少し変えてみます。
import matplotlib.pyplot as plt
plt.imshow(digits.images[0], cmap='plasma', interpolation='bicubic')
plt.show()
雰囲気変わりましたね。
ここからが本題! 機械学習プログラムを書いてみよう
はじめに、これから書くコードの全体像です。
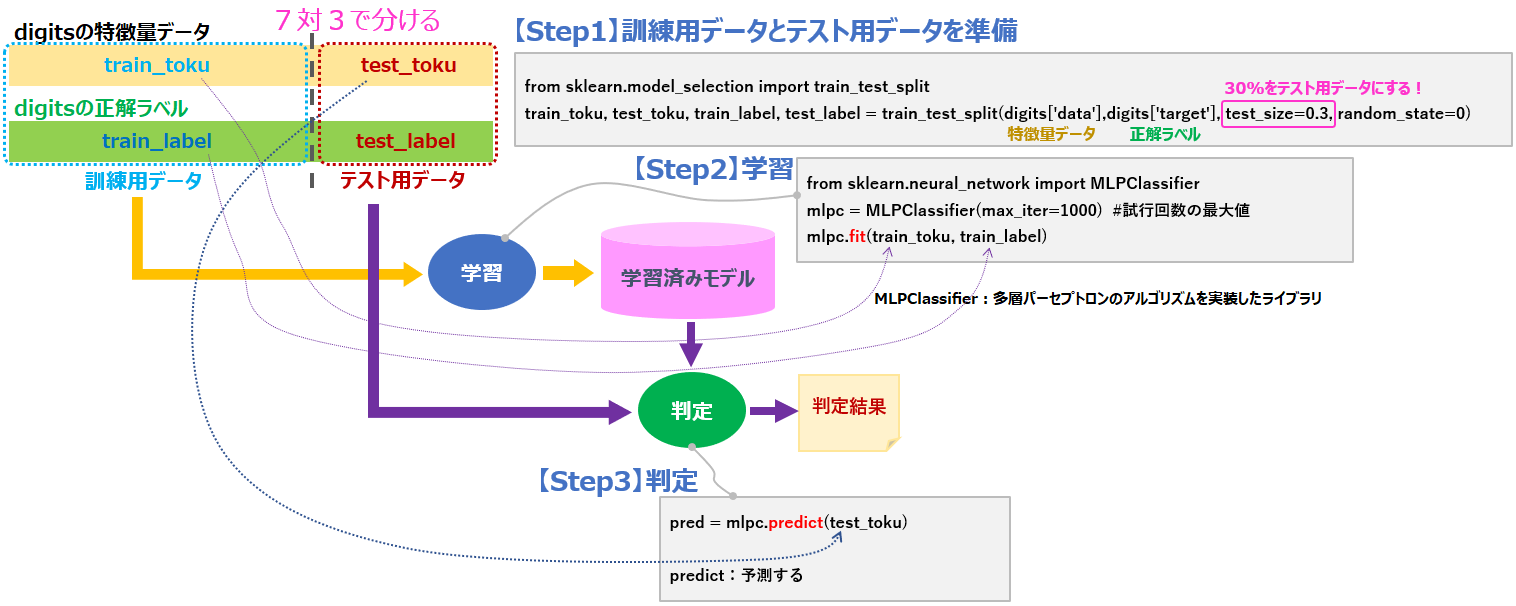
【Step1】訓練用データとテスト用データを準備
digitsに含まれている特徴量データと正解ラベルを使って、学習に必要な訓練用データを作成するコードです。
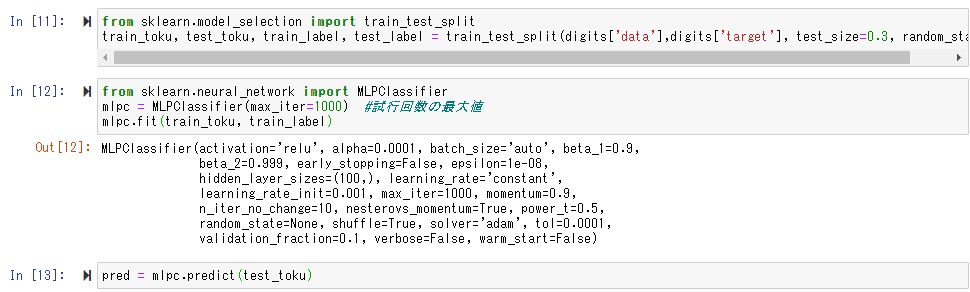
from sklearn.model_selection import train_test_split
train_toku, test_toku, train_label, test_label = train_test_split(digits['data'],digits['target'], test_size=0.3, random_state=0)
【Step2】学習
MLPClassifierという多層パーセプトロンのアルゴリズムを実装したライブラリを使って学習をするコードです。
[参考情報]機械学習のアルゴリズム
from sklearn.neural_network import MLPClassifier
mlpc = MLPClassifier(max_iter=1000) #試行回数の最大値
mlpc.fit(train_toku, train_label)
【Step3】判定
”学習済みモデル”をもとに”未知のデータ(テスト用データ)”に対して判定(数字を識別)するコードです。
pred = mlpc.predict(test_toku)
実行結果は、こんな感じです。(Step1~3までの結果です。)
判定結果を確認してみよう
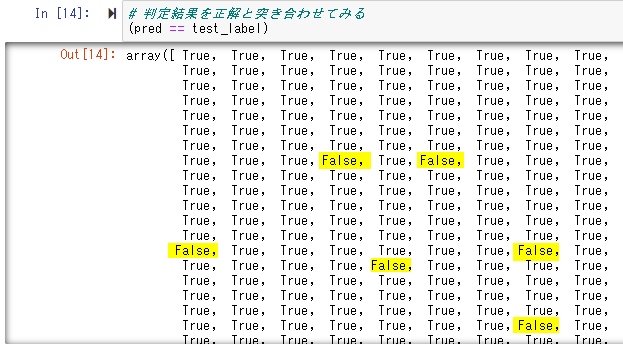
# 判定結果を正解と突き合わせてみる
(pred == test_label)
ところどころ、判定ミスがありますね。(Falseが判定ミスの箇所です。)
正解率はどの程度なのでしょうか?
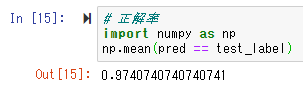
import numpy as np
np.mean(pred == test_label)
正解率は、約97%! まあまあですね。
判定ミスした画像を実際に確認してみましょう。
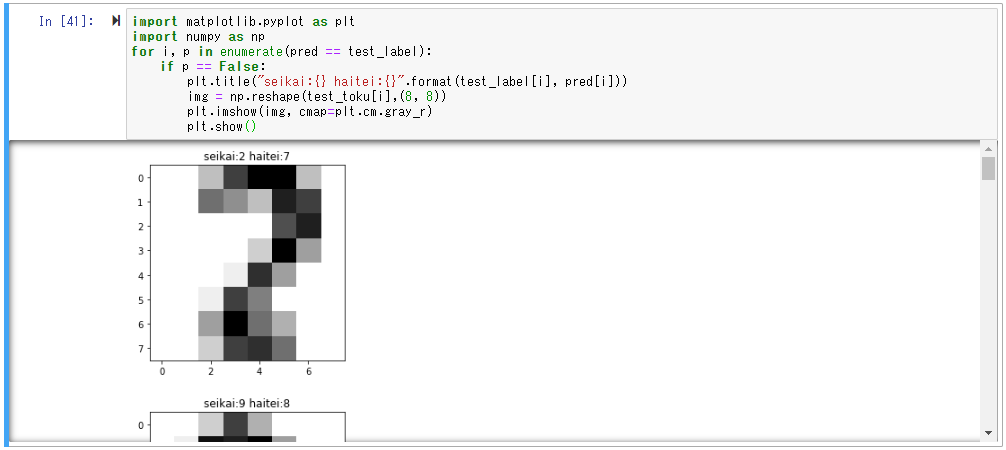
# 実際に「判定ミス」した画像を確認してみる
import matplotlib.pyplot as plt
import numpy as np
for i, p in enumerate(pred == test_label):
if p == False:
plt.title("seikai:{} haitei:{}".format(test_label[i], pred[i]))
img = np.reshape(test_toku[i],(8, 8))
plt.imshow(img, cmap=plt.cm.gray_r)
plt.show()
確かに1つ目の判定ミスは、2にも7にも見えますね。(正解は2だが、7と判定ミスしてますね。)
まとめ
今日は、細かい説明は抜きに「機械学習の雰囲気」を感じてもらいました。
「多層パーセプトロン」とか、急に難しい用語が出てきましたが、アルゴリズムの話はまだ自分も理解できていないので、追々触れていこうと思います。
まずは、「特徴量データ、正解データを準備し、それをもとに学習させ、未知のデータを判定する」という基本を押さえましょう。
次回は、「7.アヤメを分類してみよう」です。
社内勉強会 機械学習入門(7.アヤメを分類してみよう)