やること

一世を風靡したお笑い芸人、コウメ太夫氏のネタは、白塗りメイクと派手な着物に身を包み、甲高い裏声で「Xかと思ったら、Yでした〜!」と歌い上げてから、絹を裂くような金切り声で「チクショー!」と叫ぶというものです。その面白さを言葉によって説明するのは極めて難しいですが、「Xかと思った」という前振りの文Aと、「Yでした」というオチの文Bの接続の突拍子のなさが可笑しみを生み出しているというのは間違いないでしょう。しかし、ただ脈略のない二文を繋げればよいというわけではなく、理解不能ではあるけれどまるで無関連というわけではない、その飛躍具合の妙でネタの出来が決まると考えられます。
そこで、今回はコウメ太夫氏のネタを構成する二つの文の飛躍の程度を定量化し、ネタの面白さにどのような関係があるかを分析します。
文の意味を捉えるために、自然言語処理モデルであるBERTを使います。また、ネタの面白さの指標としては、ツイッター上の反響(コメント数、リツイート数、いいね数)を採用します。
データ収集
コウメ太夫氏がTwitterで公開する #まいにちチクショー から手作業でデータを集めます。文A、文Bを多少の修正を加えながら写し、同時にいいね数等も記録します。データは、フォロワー数の変化などの影響を避けるため2021年6月から2021年12月までのもの計207個に限りました。また、マニアックな固有名詞や時事ネタを含んだもの、あまりに支離滅裂で文章として成立していないものは省きます。

卒論提出直前にやるべき作業ではなかったのは確かです。
変量の抽出
面白さの指標
まず「面白さ」の定量的な指標としてコメント数、いいね数、リツイート数のどれを使うかを検討します。これらの間には明らかな正の相関があったので(余談ですが、いいね数とリツイート数には比例関係があるのに対し、コメント数はいいね数に対して対数関数的な増え方をしているのが興味深いです)、振れ幅の広いいいね数を面白さの指標とします。
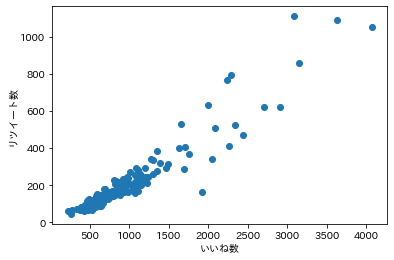
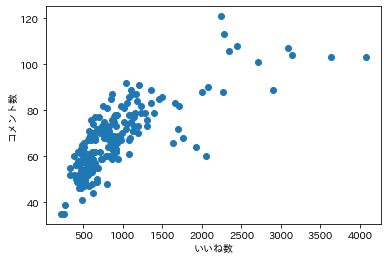
ただし、いいね数には次のように、かなりの偏りがあります。
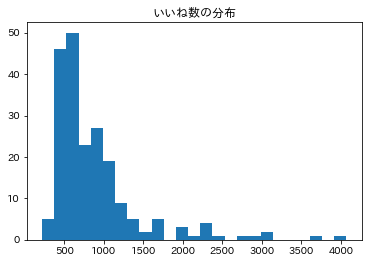
そこで、いいね数の対数をとった値を面白さの指標に採用します。これにより、分布は多少正規分布っぽくなりました。SNS上でツイートが指数的に拡散されることを踏まえても、この前処理は妥当であるように思われます。
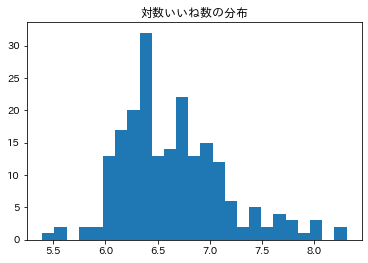
突拍子のなさの指標
連続する二つの文がどれだけ乖離しているかを測るために、今回は自然言語処理タスクであるNext Sentence Prediction (NSP)に目をつけました。これは、文Aと文Bが与えられ、文Bが文Aの後に続く文章として正しいかどうかを判定するものです。なお、BERTはこのNSPをタスクの一つとして事前学習を行ったものです。
BERTはpytorchで次のように使うことができます。
まず、必要なライブラリのインストールします。
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install .
次のように日本語版BERTをダウンロードします。tokenizerは文章を分かち書きをして単語idを割り振るものです。
from transformers import BertForNextSentencePrediction,BertJapaneseTokenizer
import torch
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
model_bert = BertForNextSentencePrediction.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
model_bert.eval()
次のように、得られた出力をソフトマックス関数に通すことで、「文Aと文Bが全く関係ない(ランダムに選ばれた)二文である確率」を予測することができます。実際に試してみましょう。
#ソフトマックス関数
import numpy as np
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
・連続する二文の場合
text_a = "私はその人を常に先生と呼んでいた。"
text_b = "だからここでもただ先生と書くだけで本名は打ち明けない。"
encoding = tokenizer(text_a, text_b, return_tensors='pt')
outputs = model_bert(**encoding, labels=torch.LongTensor([1]))
randomness_p = softmax(outputs.logits[0].detach().numpy())[1]
print(randomness_p)
1.6147911e-05
予測確率がほとんど0(=二つの文は連続していると予測)なので当たっています。
・連続しない二文の場合
text_a = "私はその人を常に先生と呼んでいた。"
text_b = "親譲の無鉄砲で子供の時から損ばかりしている。"
encoding = tokenizer(text_a, text_b, return_tensors='pt')
outputs = model_bert(**encoding, labels=torch.LongTensor([1]))
randomness_p = softmax(outputs.logits[0].detach().numpy())[1]
print(randomness_p)
0.60773915
こちらはランダムな二文である確率が1/2を超えています。なかなかうまくいっていそうです。
ただし、予測確率を直接指標とすると0と1の二極に値が集中して都合が悪いので、予測確率の対数をとった値を、突拍子のなさの指標とします。この値が小さいほど二文が連続している確率が高く(ちゃんと意味が通っている)、大きいほどランダムな二文に近い(支離滅裂でぶっ飛んでいる)と解釈できます。
実行結果
まず、用意したエクセルファイルを読み込みます。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('コウメ太夫.xlsx')
コウメ太夫氏特有の「〜」や「~」を「ー」に直しながら、「突拍子のなさ」を計算していきます。
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
model_bert = BertForNextSentencePrediction.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
model_bert.eval()
scores = []
for i in range(df.shape[0]):
text_a = df.loc[i]["A"].replace("~","ー").replace("~","ー") + "。"
text_b = df.loc[i]["B"].replace("~","ー").replace("~","ー") + "。"
encoding = tokenizer(text_a, text_b, return_tensors='pt')
outputs = model_bert(**encoding, labels=torch.LongTensor([1]))
randomness_score = np.log(softmax(outputs.logits[0].detach().numpy())[1])
scores.append(randomness_score)
print(text_a,text_b,randomness_score)
scores = np.array(scores)
plt.scatter(scores,np.vectorize(lambda x:math.log(x))(df["いいね数"].values))
plt.xlabel("NSPの確率の対数")
plt.ylabel("いいね数の対数")
「突拍子のなさ」(横軸)と「面白さ」(縦軸)の関係は次のようになりました。
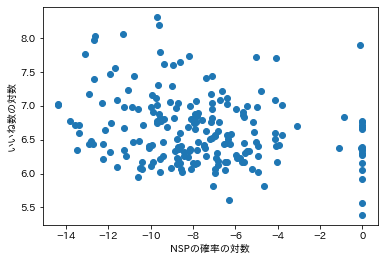
なんとなく負の相関があるような気がします。単回帰分析を行ってみましょう。
from pylab import *
from scipy import stats
x = scores
y = np.vectorize(lambda x:math.log(x))(df["いいね数"].values)
slope, intercept, r_value, p_value, std_err = \
stats.linregress(x, y)
print("傾き:{0}\n切片:{1}\n相関係数:{2}\nP値:{3}\n\
標準誤差:{4}".format(slope,intercept, r_value, p_value,std_err))
fitline = slope * x + intercept
plt.xlabel("NSPの確率の対数")
plt.ylabel("いいね数の対数")
plt.scatter(x, y)
plt.plot(x, fitline, c='r')
plt.show()
傾き:-0.03674115291080559
切片:6.3659330702356725
相関係数:-0.24488668285968893
P値:0.00038880584121434757
標準誤差:0.010184588893716734
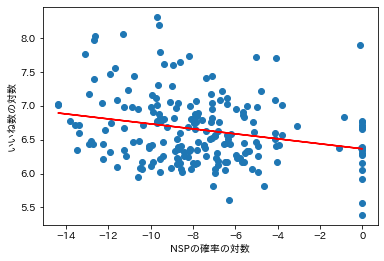
やはり相関係数は約-0.24と負になっていました。P値は0.0004となり、有意水準を5%としても大幅に下回っています。これは期待通り、「NSPの予測確率」が「面白さ」の説明変数になりうることを示唆しています。
考察
散布図上の特徴的な点と、実際のネタを照らし合わせてみましょう。
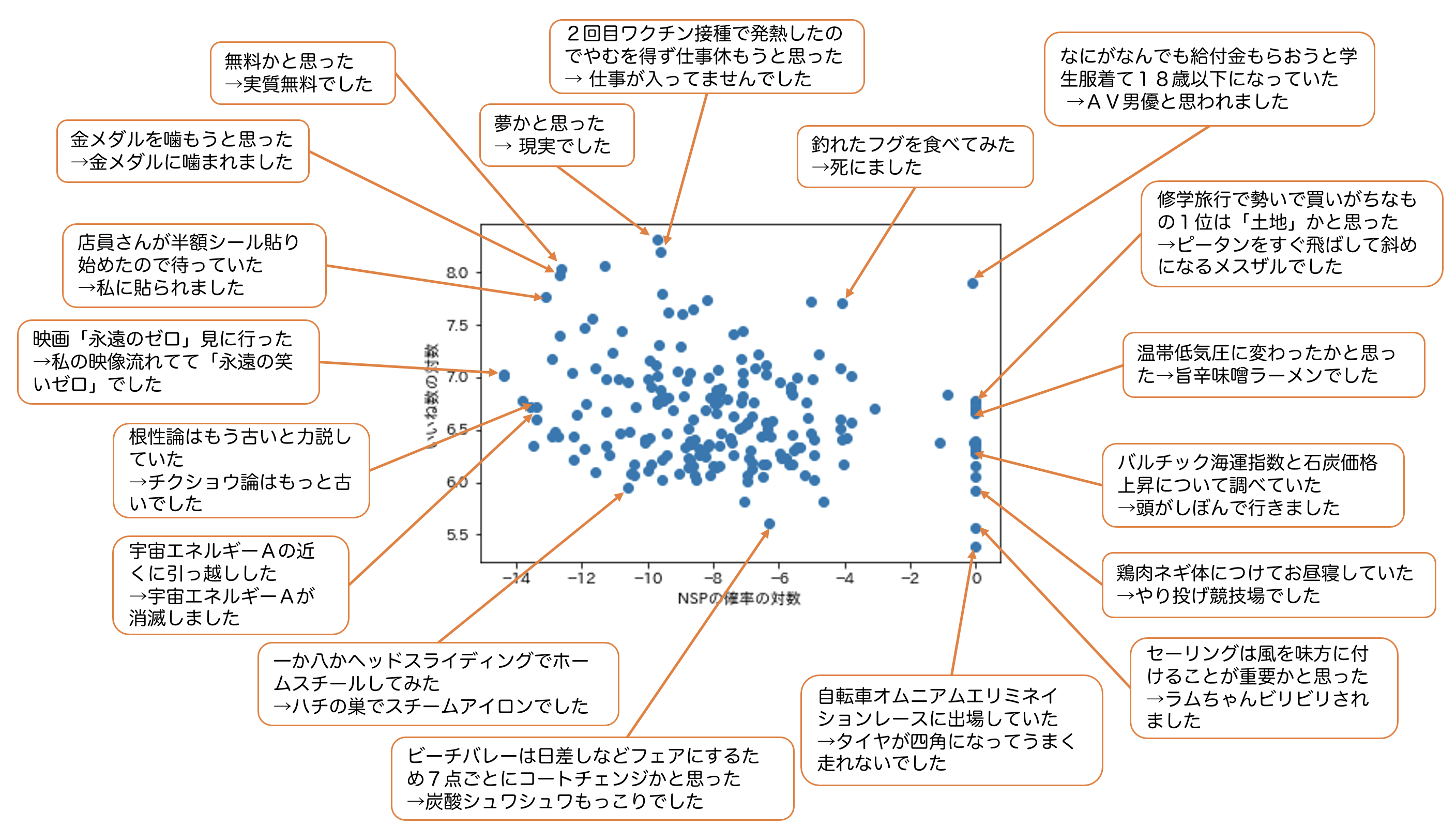
これを見ても、ある程度はBERTが文の間の飛躍具合を捉えることに成功していることがわかります。特に、NSPの確率の対数が0付近のネタは、本当にランダムな二文を選んだとしか思えないくらいに意味不明です。
ただ、いくつかの点ではBERTの精度が十分でないように見受けられます。例えば、外れ値となっている「なにがなんでも給付金もらおうと学生服着て18歳以下になっていた→AV男優と思われました」はそれなりに意味が通っていそうなものですが、「給付金」や「AV男優」という新語に対応できなかったのかもしれません。また、「一か八かヘッドスライディングでホームスチールしてみた→ハチの巣でスチームアイロンでした」なんかはもっと突拍子のなさが高く出ていてもいいような気がします。さらに、「宇宙エネルギーAの近くに引っ越しした→宇宙エネルギーAが消滅しました」は確かに連続している文で論理構造自体は理解できますが、ネタの内容自体は素っ頓狂です。NSPを指標とする限界が出ている箇所の一つです。
とはいえ、やはり「突拍子のなさ」と「面白さ」が負の相関にあるということは言えそうです(例の「AV男優」の外れ値を除くと、相関係数は-0.27、P値は0.0000495まで下がります)。実際、図の右端に並ぶのは総じて支離滅裂な語彙と因果関係とからなる我々の理解の及ばないネタであり、そういったものは一部のコアなフォロワーからを除いて支持を得ることができていません。
しかしながら、一概に、論理関係が明確であればあるほど面白いのだとはいえないようです。図の左端にあるネタ「映画「永遠のゼロ」見に行った→私の映像流れてて『永遠の笑いゼロ』でした」や「根性論はもう古いと力説していた→チクショウ論はもっと古いでした」などはオチがはっきりしていて完成度が高いようにも感じられますが、世間の反応は殊の外芳しくありません。これはネタが出来過ぎていて、コウメ太夫氏の特長である奇天烈さが失われているからだと考えることができます。つまり当初の仮説通り、ネタの面白さには、意味を成していることに加えてある程度の意外性、突飛さが必要不可欠であり、それらを兼ね備えているのが好評を博した「金メダルを噛もうと思った→金メダルに噛まれました」や「店員さんが半額シール貼り始めたので待っていた→私に貼られました」、「夢かと思った→現実でした」といったネタたちだったのだと言えます。
これらを踏まえて、コウメ太夫氏のネタの「突拍子のなさ」と「面白さ」の関係は次のようにまとめられます。
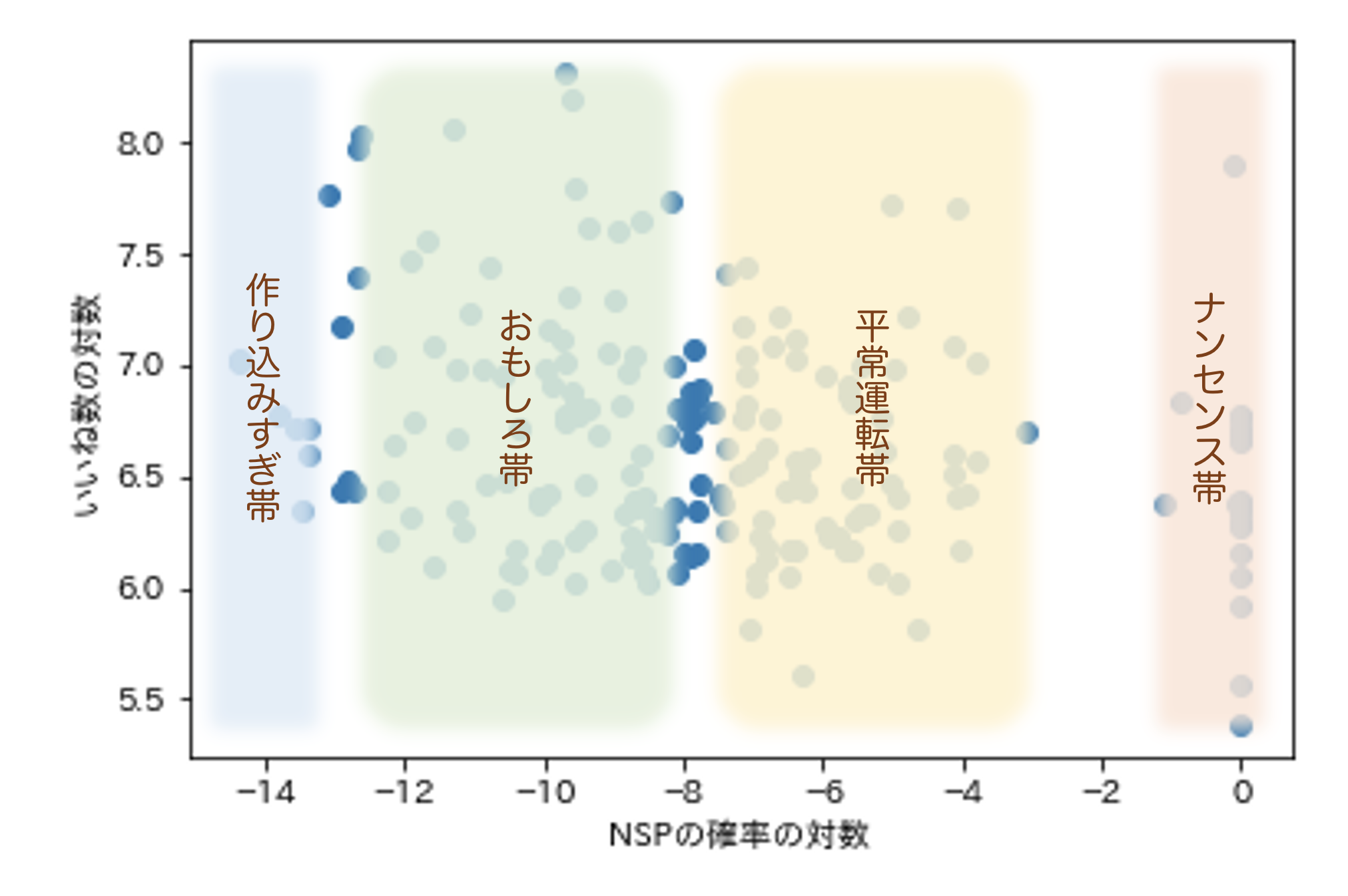
異論は認めます。
さてそれでは、常に、「突拍子のなさ」を抑えた「おもしろ帯」に入るようなネタをすればウケ続けるのかと言うと、そう単純な話ではないようにも思います。普段は理解不能なネタをしているコウメ太夫氏が、ふと我に返ったかのように「夢かと思ったら~、現実でした~。」「無料かと思ったら~、実質無料でした~。」という、意味の通ったありふれているフレーズを口にするからこそ、我々はそこに意外性とシュールさを感じ取り、思わず頬を緩めてしまうのではないでしょうか。
つまり、コウメ太夫氏の面白さは「おもしろ帯」と「ナンセンス帯」のギャップによって生み出されていると言えるのです。
おわりに〜自然言語処理とお笑いの分析について〜
お笑いを理屈で語る上で、「裏切りの匙加減」が外せないのはよく言われることですが、自然言語処理技術の発展により、従来は叶わなかった文章同士の意味的な関連性の、主観によらない定量化が可能になりつつあります。今回考案したNSPの用法以外にも、文章の特徴ベクトルの類似度を測るなど、意外性を計算する方法はたくさん考えられます。自然言語生成の技術が向上し、面白さの生じる仕組みの解明も進めば、ギャグセンの高いAIが誕生する日もそう遠くはないかもしれません。AIのお笑い能力が人間を超えたときにどんなネタを見ることができるのか、あるいはやはり人間味や即興性の醸し出す可笑しみには敵わないのか、とても興味深いです。
参考サイト
おすすめ記事