この記事は、Supershipグループ Advent Calendar 2022 の4日目の記事になります。
はじめに
Supership株式会社の @masahito-suzuki です。
最近ではAWSやDatabricksに関する管理を中心にコストレポート・見える化などをAWS Lambdaを中心に作成しています。
今回Lambdaを久しぶりに利用していると見慣れない機能「関数URL」と言うものがあり、これについて調べてみると、なるほど「今までより簡単にWebアプリが作れる」ようで、更に深掘りして調べた結果を記載しまとめてみました。
serverless関連に興味のある方は是非見ていただければと思います。
関数URLとは
2022/04/05 より AWS Lambdaアップデートで新機能 関数URL が登場しました。
これまでAPI Gatewayを使って、Lamdaを実行する形でserverless 環境でのWebアプリが作れるものとして利用されてきたわけですが、これがLambda単体での利用が可能なりました。
やり方はとても簡単
AWS Lambdaを作成して「設定」「関数URL」を指定します。
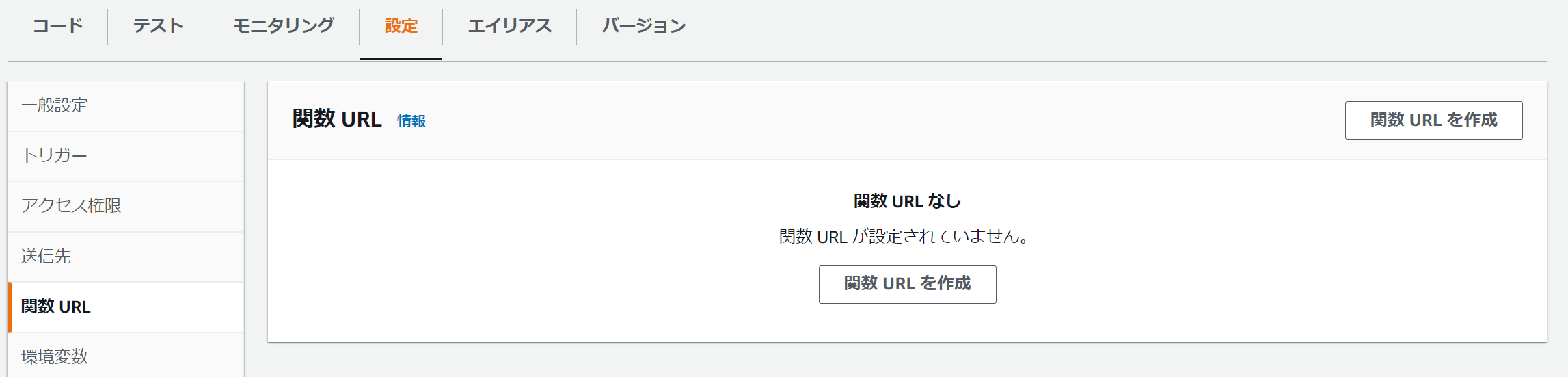
ここで 関数URL を作成ボタンを押下します。
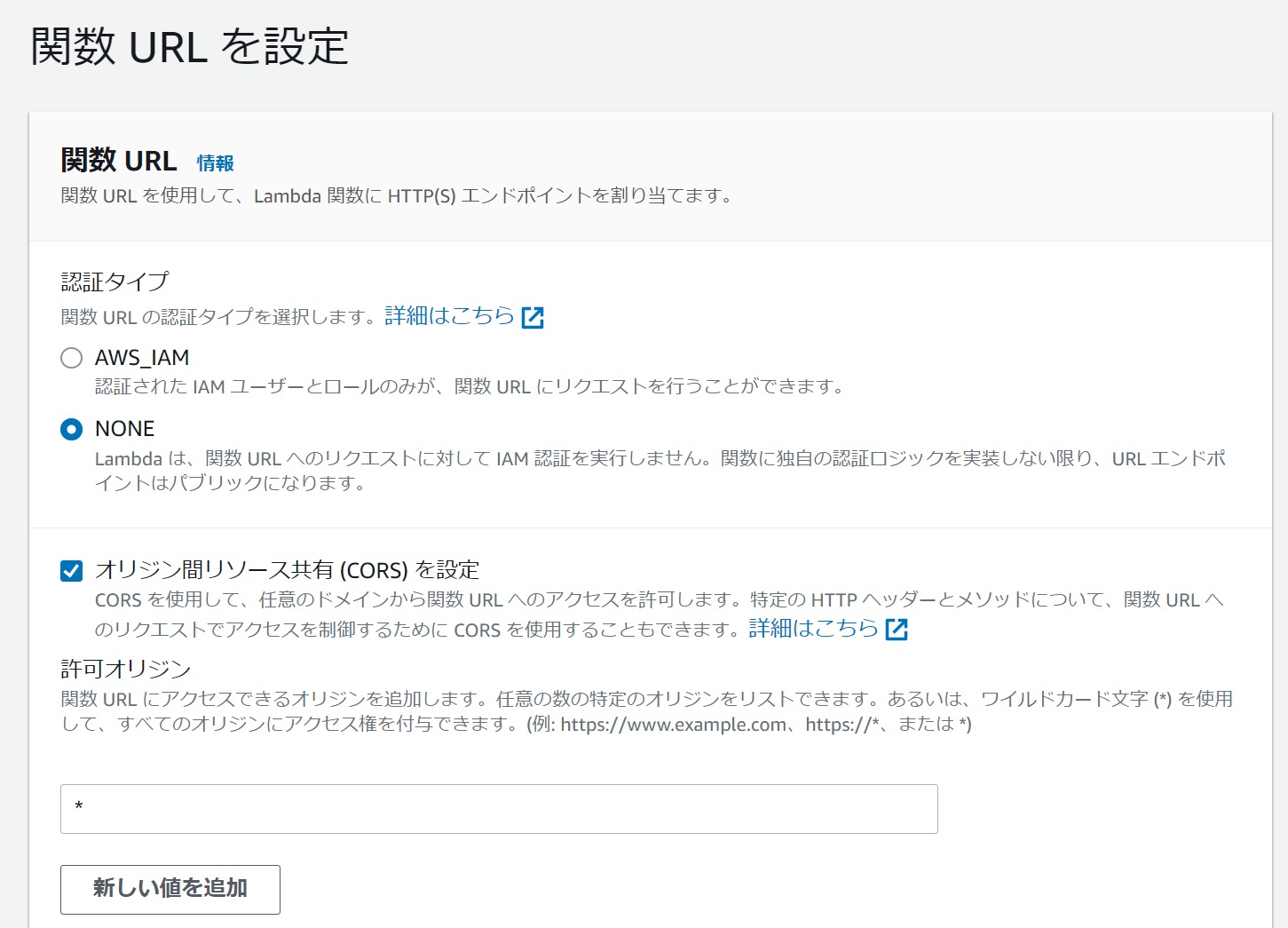
認証タイプは
- AWS_IAM
- NONE
の2種類が存在するのですが、今回はパブリック公開を前提とするので NONEを指定します。
状況の応じて オリジン間リソース共有(CROS)を設定 をONにすれば、クロスドメインアクセスが可能となります。
それ以外にも 許可メソッド を設定したり 許可認証情報(cookieの利用云々) のON/OFFを設定したりします。
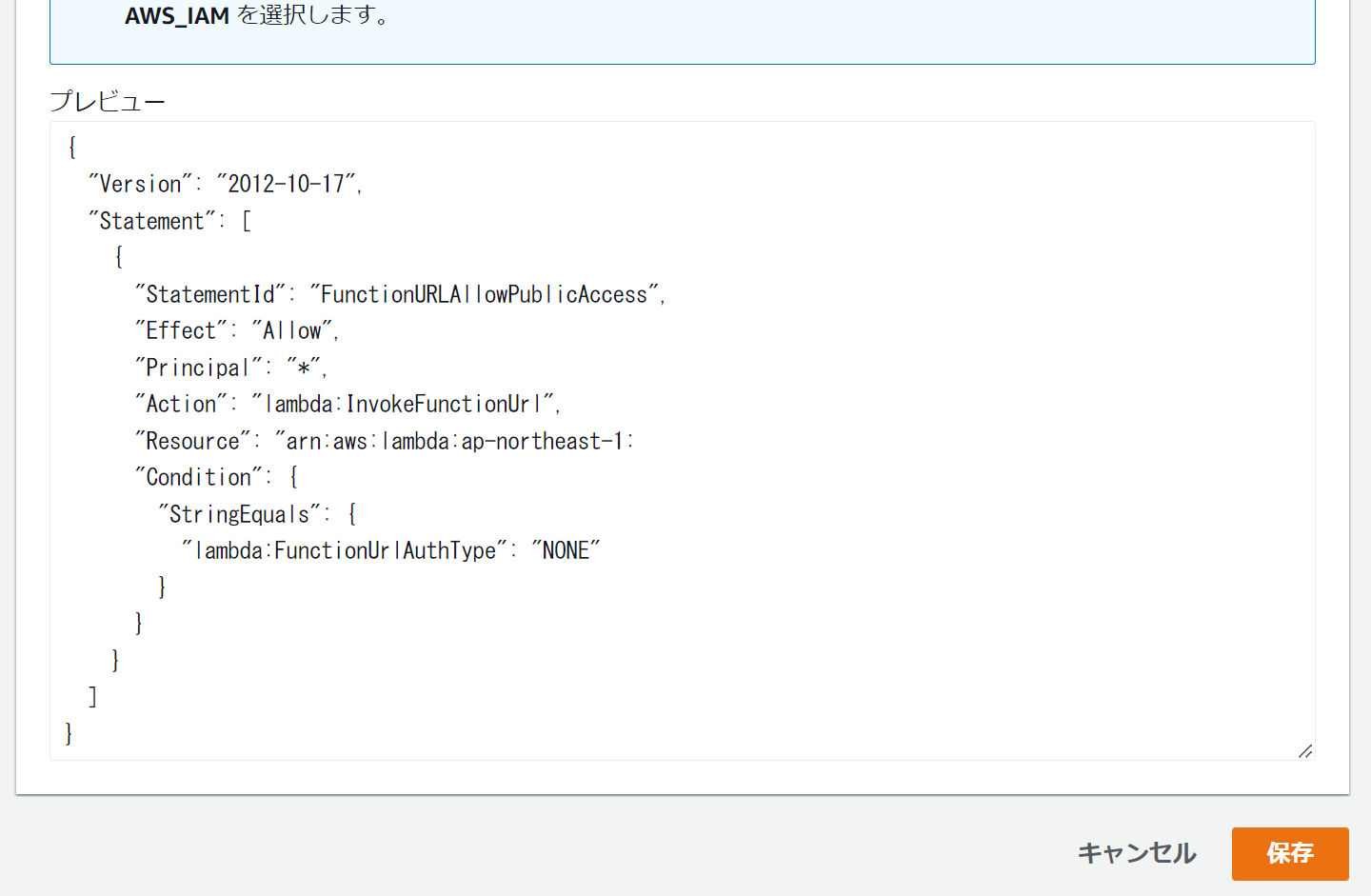
設定が完了したら「保存」ボタンを押下で、関数URLの登録が完了です。
これによって、以下のようなパブリックアクセスが可能なURLが作成されます.
https://{関数URLのID}.lambda-url.{region}.on.aws
とりあえずLambdaが実行される index.js を以下のように編集して deploy してブラウザから、割り当てられた関数URLのURLを開くと {hello: "world"} のJSON結果が表示されます。
exports.handler = async function(event) {
return {
'statusCode': 200,
'body': {hello: "world"}
}
}
このようにLambdaの 関数URL は非常に簡単に作成できて公開することが出来ます。
Lambda関数URLと Api Gateway のHttpRequest, responseの仕様は同じ
当たり前ですが、後発の 関数URL の利用方法は、それまで提供されている Api Gateway + Lambdaでの仕様は同じです。
具体的には、httpRequest, httpResponse方法など。
なので、この説明は割愛し関数URLの説明を続けていきます。
最低限の関数URLを実行してみた結果
上記によって、関数URLが開通し、最低限のLambdaからのHttpレスポンスがブラウザから実行できました。
ここで気になるのはAWSのLambdaはコールドスタートは遅いと言われていたので、この辺を注目してみたいと思います。
上記を実行してみるとブラウザ側の計測で速い時は大体 300ミリ秒 ぐらい、一方で遅いコールドスタートでは 600m~800mミリ秒ぐらいで返却されます。
また cloudWatchでは 3~30ミリ秒で実行されていると表示されており、思ったよりも速いと思うと同時に「コールドスタートの時間に幅がある」と感じました。
一方でこのような「hello world的」な単純な処理返却で、最大800ミリ秒ってのは普通にWebアプリとして利用しようとした場合、その分処理が積み重なりもっと遅くなるのではないか?って思うわけです。
なので、Lambdaの歴史も大分経つ中、まずは コールドスタート回避方法は無いのか?思うわけで、次の項よりまず「コールドスタートの回避」の手段を模索して行こうと思います。
コールドスタート回避策その①:コールドスタートさせないように都度キックする
1つは、昔からあるLambdaのコールドスタート回避方法です。
内容としては単純にコールドスタートしないタイミング(1分ぐらいの単位)で、Lambdaをキックして「コールド化させない」方法があります。
この場合、Lambdaをキックするための処理を用意する必要があるのと、定期実行でコールドスタート回避ができるのは1つのLambdaプロセスなので、同時実行された場合新しいLambdaはコールドスタート実行される問題があることなどの欠点があります。
また、Lambdaの無料枠が1 か月あたり 100 万件の無料リクエストと、1 か月あたり 40 万 GB-s のコンピューティングタイム があるので、それほどアクセスが少ない社内向けのWebアプリ程度なら無料枠の範囲内でこのコールドスタート回避方法が利用できる可能性が高いので、ケースバイケースかと思います。
※あと「これらのLambda関数URL or Api Gateway + Lambdaが1つのAWSアカウントで複数あると無料枠を超えてしまう」と言う欠点もあります。
コールドスタート回避策その②:プロビジョニング済み同時実行数の設定を行う
ここに公式の説明があるのですが、これは要するに「Lambdaを起動しっぱなしにしておく」仕組みを提供するものです。
なので当然コールドスタートは発生しないので「速度は劇的に早くなる」のは間違いないです。
また「コールドスタート対策その①」と違い 同時実行数分をプロビジョニング済みとするので「その①」の欠点も「克服」することができる代物であると言えます。
しかし、この「プロビジョニング済みの同時実行数の設定」の最大の問題は「serverless」では無くなること、つまり「プロビジョニング済み=実行することを想定して準備=実行待ちで待機」と、まさに「その間コストがジリジリ発生」するものであり、それ相応の「メモリーサイズ」のLambdaだと「小さめのEC2」立ち上げてるのと「あんまり変わらないコスト」が発生することになります。
あとこの「プロビジョニング済みの同時実行数の設定」は「Lambdaの無料枠外」なので、この辺も「IT業界に銀の弾丸は存在しない」なあと「実感」しますね。
コールドスタート回避策その③:snapStartを利用する
Lambda snapStartと言うものが2022/11/30に発表され、現在利用可能(現状はjava11限定)となっています。
この機能は上記の回避策①や②とは違って、LambdaのInit処理部分(以下画像の青の部分)をスナップショット化して再利用できるようにする仕組みで、これにより従来のコールドスタートの遅さをカバーできるようです。
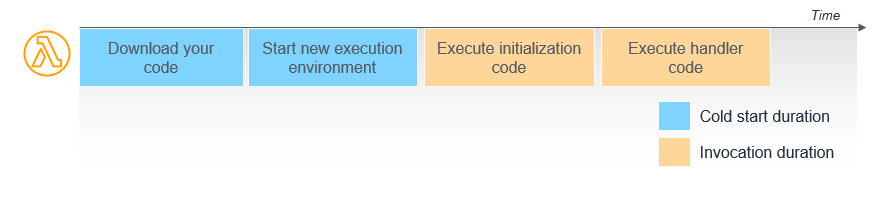
https://aws.amazon.com/jp/blogs/news/operating-lambda-performance-optimization-part-1/
※ 上記から画像を引用
ただ現状サポートされているのがJavaであり、このJavaがLambdaでは「遅い」その理由がこのサイトの説明にあるように「起動時に巨大なJVMのライブラリやJavaのclassファイルを読み込む」のですが、これが snapStart では、この内容もスナップショット化されるので、結果的に90%も劇的にコールドスタートが速くなるようです。
今後どのような形で他の言語に対して snapStart が利用できるか?たとえばLayersで共有されたライブラリを利用する場面において、これらの利用ライブラリも先読みしてスナップショット化されて実行できる形になるかも知れないので、この場合は重いライブラリを利用しても、コールドスタートで高速起動できるかもしれないですね。
そうでない場合でも、コールドスタートのinit部分(実行ノード作成+プログラムロード)での、重い場合600ミリ秒~800ミリ秒ぐらいかかるものを snapStart で回避できれば、それだけでも相当恩恵があると言えます。
筆者の主戦場であるJavascript(Nodejs)での利用に対して早くサポートして欲しいですね。
それの体験結果によれば、今回記載してる内容が殆ど役に立たない可能性があるので、非常に楽しみですね。
次に現状のコールドスタートに対する「改善策」を模索しようと思います。
コールドスタート改善策: Lambda実行のメモリーサイズを増やす
次に回避ではなく「改善策」を考えてみます。
内容としては「コールドスタートを前提とする」けど、その中で「許容」できる範囲のものを模索すると言うものです。
実は結構有名な話ですが Lamdaは実行メモリサイズ の設定によって「実行速度が変わる」と言うものがあるので、なのでメモリサイズを見直すことで「Lambdaの速度も上がる」事になり、また同様に「Lambda自体のコストも上がる」ので、具体的に「コスパが良くて速度が速い」のかを、以降より検証してみようと思います。
今回の検証結果は、私がこの関数URLを「コールドスタートを前提とした」軽量なフレームワークが作れないか?と思って、現在開発中のフレームワーク LFU での実験結果から説明します。
ここでは spec の5条件を基本としています。
- 128MByte
- 256MByte
- 512MByte
- 1024MByte(1GByte)
- 10240MByte(10GByte)
この軸を元に以下の内容を計測しています。
-
min
index.js → exports.handler → returnだけの単純構成 -
min2
LFUのping実行(LFU初期呼び出しで即返却) -
html
LFU経由でHTML返却処理 -
run js
LFU経由でjsファイル実行返却 -
run template
LFU提供の軽量テンプレートで動的HTML返却
と言う処理を元に計測したもので、結果は以下のようになります。
| no | spec | min | min2 | html | run js | run template |
|---|---|---|---|---|---|---|
| 1 | 128M | 12msec | 120msec | 850msec | 1083msec | 1074msec |
| 2 | 256M | 3msec | 59msec | 600msec | 637msec | 637msec |
| 3 | 512M | 4msec | 15msec | 395msec | 417msec | 411msec |
| 4 | 1024M | 3msec | 11msec | 314msec | 354msec | 352msec |
| 5 | 10240M | 3msec | 10msec | 303msec | 312msec | 275msec |
この結果は cloud watchでの結果なので、実際のコールドスタートでは、この値に対してブラウザの応答時間は、プラスInit処理で以下の時間がかかる感じです。
300msec から 600~800msecぐらい
この部分については、メモリ設定とは関係ない感じでコールドスタート時に上乗せされます。
最適なLambdaの関数URLメモリサイズを考える
これを実際にグラフ化すると、どこが「一番コスパが良いのか?」と言うがわかります。
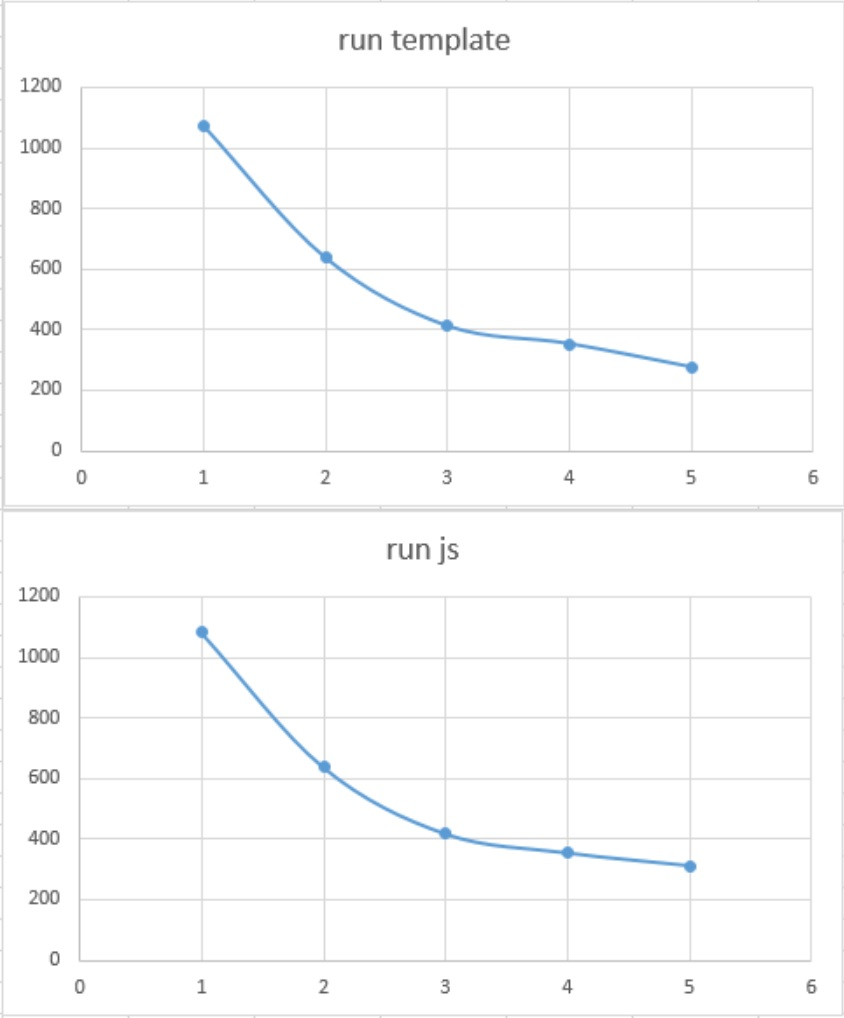
これを見れば一目瞭然だと思いますが、少なくとも 関数URL における「コールドスタートを前提」とした場合の、最適なLambdaメモリサイズは 512MByte が最もコスパが良い(または1024MByte・・・ただ、倍スペックでそれほど大きなパフォーマンスの伸びは無い)ものであると言えます。
あと体感的に感じたのは「ある程度の反復処理」を行う場合はLambdaは高速に動くので、なので単なるHTML返却とくらべて run js や run template がそれほど変わらないので、この辺を踏まえた実装の範囲なら、それなりに高速に実行できるようです。
注意点:Lambdaと関数URLとコールドスタートの致命的問題
Lambdaで有名なのは RDSと相性が悪い と言うもので、その理由が「コネクション用のライブラリがデカい」とか「コネクションプーリングが使えない」ことで パフォーマンスが出ない 問題が挙げられます。
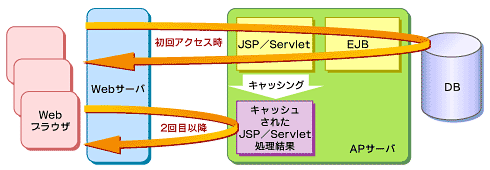
たとえば上記画像のようにこの内容(上記画像引用元)にあるような典型的な古いWebサービス(2003年)のようなものが、おそらくWebサービスでのキャッシュやプーリングを説明するに非常にシンプルでわかりやすいので参考とします。
このようなserverlessでないWebアプリでは、たとえば require で取得したライブラリは1度読み込めば キャッシュ化 されるし、当然 コネクションもプーリングされたものは一定期間再利用可能な状態となります。
しかし一方で Lambdaの場合はコールドスタートする毎に requireは再取得し実行可能な状況に解析 され、そしてコネクションはコールドスタートの度に再取得 されます。
言い換えるとLambdaのコールドスタートは、正に「上記画像」で言う所の 初回アクセス時 を行う事になり、またこれにプラスして「JavaならJVMを再起動する」ようなもので、利用する「巨大ライブラリ」も同様に「コールドスタートの度」に「再読み込み」となるわけです。
なのでコールドスタート毎に毎回 真っ更 な状態で起動する結果、初期読み込みで巨大ライブラリを読み込みに時間がかかるが、2回目以降はキャッシュやプーリングでパフォーマンスが担保できるものは、Lambdaの関数URLでは天敵となり得るわけです。
なので利用するライブラリが「巨大な」場合、そのライブラリを「コールドスタート毎に毎回読み込み」が発生し、それらを実行形体に変換となり、そして「コネクションを毎度取得する」これらの時間「相当ボトルネック」になってしまい、結果的にコールドスタートが大きく遅延することになってしまいます。
ただこれは先程記載した snapStart によって、ライブラリの毎度の読み込みは回避できる可能性は高いので、コネクションプーリングのコスト以外のボトルネックは気にしなくて良くなる可能性があります。
Lambdaの関数URLでは aws sdk は使うべからず
※snapStart対応の場合はこの限りでは無い可能性があります(今後に期待です)。
奇しくもそれを正に私が作ってLFUのフレームワーク作成時に対して 何も考えずに aws sdk v2(node.js) を普通に利用して呼び出していましたことで「実感」したことにあります。
びっくりしたのは aws-sdk v2 ってのは、npm install した場合 73.8MByte と結構巨大なライブラリだったりします。
最初はその辺を何も考えずに aws-sdk v2 を使いLambdaの標準設定メモリ128MByteで実行したらコールドスタート時に5秒ぐらいかかったわけですが、当初は「Lambdaはコールドスタートが遅い」と言われてたので、コールドスタートはこんなに遅いのか!!って思った次第でした。
だけど改めて index.js → exports.handler → returnだけの単純構成 で実行した場合、コールドスタートでも最大で1秒もかからないのに気づいて、何処がボトルネックなのか?と調べると、正に aws-sdk(v2)のrequireだけで5秒もかかっていた事に気づきました。
つまり「関数URLをコールドスタートを許容」した形で利用する場合は標準の aws sdkも使うべからず 使うとコールドスタートでは使い物にならないと言うことになります。
幸い awsでやり取りできるのは シグニチャーV4(自前で実装する必要がある) を用いた restAPIでアクセスできるので、AWSのサービスを利用する場合は安易に aws sdk を使わない方法のほうが「高速実行」で「安価」なWebアプリを構築することが出来ます。
-
aws-sdk(v2)を利用したコールドスタート
Duration: 6378.64 ms Billed Duration: 6379 ms Memory Size: 128 MB Max Memory Used: 81 MB Init Duration: 136.09 ms
-
s3 rest api呼び出しでのコールドスタート
Duration: 1169.33 ms Billed Duration: 1170 ms Memory Size: 128 MB Max Memory Used: 61 MB Init Duration: 140.79 ms
このように同じ結果に対して、実行時間が5.45倍も高速化 そして20MByteのメモリ削減もできるので 関数URLでは aws sdk のような大きなライブラリは使うべからずであると、改めて実感しました。
おまけ: Lambda単体は改めて見ると安いうまく使えるとコスパが良さそう
コストはAWSのサイトにあるように
AWS Lambda の無料利用枠には、1 か月あたり 100 万件の無料リクエストと、1 か月あたり 40 万 GB-s のコンピューティングタイムが含まれている
とあるので
- 40万 GByte
- 128MByte = 3125000秒 / 868時間(約36日) 1ヶ月.
- 256MByte = 1562500秒 / 434時間(約18日) 1ヶ月.
- 512MByte = 781250秒 / 217時間(約9日) 1ヶ月.
- 1024MByte = 390625秒 / 108時間(約4.5日) 1ヶ月.
- 10240MByte = 39062秒 / 10.8時間(約0.45日) 1ヶ月.
が無料枠で利用することができます。
無料枠が終わったとしても
-
コンピューティングタイム
- 0.00001667 USD/GB 秒
なので、たとえば1つのLambdaを1日ずっと動かすとした場合- 128MByte = 0.18436USD
- 256MByte = 0.36871USD
- 512MByte = 0.73742USD
- 1024MByte = 1.47485USD
- 10240MByte = 14.7485USD
- 0.00001667 USD/GB 秒
-
リクエスト毎
- 0.0000002 USD/リクエスト
なので、100万回リクエスト- 0.20 USD
- 0.0000002 USD/リクエスト
となるので、基本的に動かすLambdaのメモリが多ければ多いほど、単価が高くなる一方で、関数URLの場合、それほどアクセスが無い社内向けのシステム程度なら、Maxの10240MByteでも、1ヶ月無料枠でいけそうな感じがします。
これらをうまく使えば、社内で少人数で使うものなら「安価」でできる感じがするし、S3はそもそもKeyValueなのでうまく使えば「簡易的なKeyValueストレージ」として利用できるので、これらを活用して安価なシステムを作ることができると思いました。
- S3= 1TByteあたり月25USD(アメリカドル)
- S3オブジェクト=1byteでも128kbyte扱い(0.000000131072USD)=100万データ=(0.131072USD)
100万データでも0.13ドル(月)=(1ドル140円=18.35008円[月])
とても安価ですよね。
あと、Lambdaを利用する場合IntelCPUよりARM64の方が 最大 34% 優れた料金パフォーマンスを実現 できるそうなので、こちらを選択したほうが良い感じです。
また筆者が実験で作っているLFUを使ってログイン画面を作ってコールドスタートの実際の体感実験をしてみたのですが、少し遅いですが利用できないほどではない感じでした。
あと、RDBMSの代わりにS3バケットでユーザやトークン管理をしてみましたが、それなりの速さで動いてるので、snapStart が未サポートの現状でもそれなりに利用ができるのかと思いました。
3年前には プロビジョニング済み同時実行数の設定 2022/04/05には 関数URL そして2022/11/30には snapStart と、益々serverless界隈がアツい感じがします。
これを読んだ方、是非コールドスタートを許容したLambdaの関数URLを利用してみては如何でしょうか。
最後に宣伝
Supershipではプロダクト開発やサービス開発に関わる方を絶賛募集しております。
ご興味がある方はSupership株式会社 採用サイトよりご確認ください。
是非ともよろしくお願いいたします。