はじめに
今回はWEBスクレイピングをBeautifulSoup4を用いて行う。
何かと日々の業務の中で、WEBから情報を取ってくることは多く、またその情報をマニュアルに取得することは困難なことが多い。
また、機械学習のデータセットとして画像データなんかを用いる場合、スクレイピングを用いないとかなり厳しい気持ちになる。
そこで、サクッと欲しいデータを集めるために、WEBスクレイピングのHowToを学び、ここに備忘録としてまとめる。
環境
- MacOS
- Python3系
- BeautifulSoup4
BeautifulSoup4のインストール
BeautifulSoup4はHTMLおよびXMLドキュメントを解析するためのPythonパッケージである。
HTMLタグなどを指定することで、その要素を取得してくれる。
インストールはpipにて行う。
bash$ pip3 install bs4
スクレイピング
今回は世界で大人気のサッカーゲーム「FIFA20」の全選手のデータをスクレイピングする。
取得先はこちら。
スクレイピングの際に用いるタグを特定するため、このページでHTMLの記述を確認する。
あーなんかこの辺なんだろうと思いながら、theadとtbodyを取ってくれば良さそうだなとあたりをつける。
そんでもって、ソースコードはこんな感じ。
import requests
from bs4 import BeautifulSoup
import csv
# Getting header
def columns2csv(url, csv_write):
res = requests.get(url)
res.encoding = res.apparent_encoding
soup = BeautifulSoup(res.text, "html.parser")
# Getting tag
theads = soup.find_all("thead")
# Writing
for thead in theads:
head_data = []
for head in thead.find_all("td"):
head_data.append(head.get_text())
csv_write.writerow(head_data)
# Getting body
def table2csv(url, csv_write):
res = requests.get(url)
res.encoding = res.apparent_encoding
soup = BeautifulSoup(res.text, "html.parser")
# Getting tag
tbodys = soup.find_all("tr", class_="clickable")
# Writing
for tbody in tbodys:
body_data = []
for body in tbody.find_all("td"):
body_data.append(body.get_text())
csv_write.writerow(body_data)
# url, file_path
default_url = "https://www.fifplay.com/fifa-20/players/?page="
file_path = "tbl_fifa20.csv"
csv_file = open(file_path, 'wt', newline='', encoding='UTF-8')
csv_write = csv.writer(csv_file)
column_url = default_url+str(1)
columns2csv(column_url, csv_write)
# 414pages
for i in range(414):
url = default_url + str(i+1)
table2csv(url, csv_write)
csv_file.close()
簡単に説明すると、
- requestsモジュールで対象urlにGETを飛ばす。
- headerを取得する関数であるcolumns2csvでは、theadを指定する。
- bodyを取得する関数であるtable2csvでは、tbodyを指定する。
- bodyに関しては、全ページ(414ページ)分取得するために、forループ回してurlのページネーション記述部分を変更する。
という感じ。
このままではデータがちょっと汚いので、よしなにフォーマッティングする。
import codecs
pos_list = ["GK", "CB", "RB", "LB", "RWB", "LWB", "CM", "CAM", "CDM", "RM", "LM", "ST", "CF", "RF", "LF", "RW", "LW"]
with codecs.open("tbl_fifa20.csv", "r", "UTF-8", "ignore") as f:
s = f.read()
s = s.replace("\n","")
s = s.replace("Player,PAC", "Player,POS,PAC")
for pos in pos_list:
s = s.replace(pos, "\",\""+pos)
with codecs.open("tbl_fifa20.csv", "w", "UTF-8", "ignore") as f:
f.write(s)
最後に、出来上がったテーブルをpandasで読み込んで表示すると、
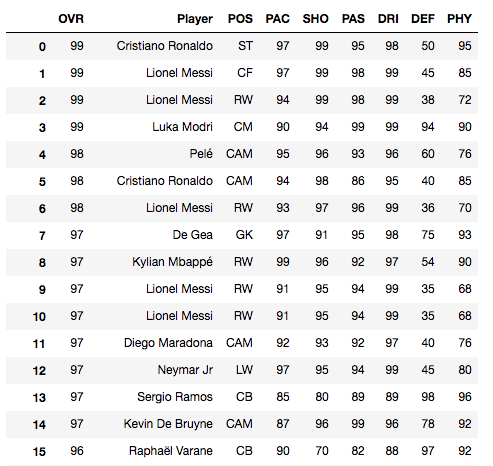
20663rows x 9columns
こんな感じでレジェンド選手を含めた、FIFA20の全選手のデータテーブルが出来上がっていることがわかる。
終わりに
今回はスクレイピングのHowToをまとめることが目的であったため、記事としてはここで終わりである。
このように、WEBスクレイピングは、WEBにあるデータを高速かつもれなく取得する際に非常に有用である。
スクレイピングで得られたデータどう料理するか、ここから先が非常に重要で、サイエンスが必要である。
以上、スクレイピングのHowToでした。
みんなもスクレイピングで日々の業務の効率化だったり、機械学習のデータセット作成などエンジョイしてみよう!