記事を作成した背景
Python初心者かつ、今後データ分析に携わる職種に就くにあたって、
Pythonでデータ分析の練習をしたいなと考えました。
そこで以下のHPを発見し、真似して可視化に挑戦してみました。
データ分析初心者向け・毎日暑いのでPython使って気象データを可視化・分析してみた
初投稿なので見にくい部分もあるかとはおもいますが、お付き合いしていただけると幸いです。
概要
上記のHPと同じことをするのは芸がないので、こちらは平均気温と平均湿度から不快指数を求め、比較を行います。
つまり体感の熱さを指標にします。
不快指数の求め方は以下のHPを参考にしました。
[不快指数-高精度計算サイト]
(https://keisan.casio.jp/exec/system/1202883065)
<不快指数の求め方>
T(気温)
H(湿度)
DI=0.81T+0.01H×(0.99T−14.3)+46.3
集計対象
<時期>
1989年~2018年
<観測場所>
東京
<対象データ>
不快指数75以上
(※「やや暑い」「暑くて汗が出る」「暑くてたまらない」と記載されているものを対象としています。)
対象データ取得
気象庁よりCSVでデータを取得する。
[気象庁 過去の気象データ・ダウンロード]
(http://www.data.jma.go.jp/gmd/risk/obsdl/index.php#)
※取得したデータは実際にはそのまま使ったわけではなく、
文字コードの変更などの加工を行いましたが今回は割愛します。
気が向いたら別途記事として書くかもしれません。
コーディング
以下の作業を行いました。
①インポート
使うライブラリをインポートします。
import matplotlib.pyplot as plt
import pandas
import datetime
②CSVファイル取り込み、年単位のループの作成
上述のHPに倣って、CSVデータの取り込みと年ごとのループを作成しました。
# 気象庁から取得したファイルでは年月日と記載されていますが、dateに書き換えました。
data = pandas.read_csv('ファイルのパス',index_col='date', parse_dates=['date'])
# 30年分なので、30回ループします。
for i in range(30):
start = data.index.searchsorted(datetime.datetime(2018-i, 1, 1))
end = data.index.searchsorted(datetime.datetime(2019-i, 1, 1))
t = data[start:end].values
#リストyearに処理する「年」を格納していく。
year.append(2018-i)
②-2 変数の初期化
warm_count = 0
hot_count = 0
too_hot_count = 0
leap = 0
③うるう年の判定処理
以下のif分岐で処理年数がうるう年を判定し変数leapに処理する年の日数を格納します。
if (2018-i)%400 == 0:
leap = 366
elif (2018-i)%100 == 0:
leap = 365
elif (2018-i)%4 == 0:
leap = 366
else:
leap = 365
④日単位の不快指数の取得
上述のループの中にもう一つ日数分ループするfor文を作成します。
不快指数を計算し、暑さのレベルに応じて異なる変数にカウントアップします。
for d in range(leap):
#変数の初期化
tmp = 0
hum = 0
disc = 0
#温度(tmp)と湿度(hum)をそれぞれ変数に格納します。
tmp = t[d][0]
hum = t[d][3]
#不快指数の計算
disc = round((0.81*tmp)+(0.01*hum)*((0.99*tmp)-14.3)+46.3,2)
#レベルに応じてカウントアップする変数を変更します。
if disc >= 75 and disc < 80: #「やや暑い」と感じるレベル
warm_count += 1
elif disc >= 80 and disc < 85: #「暑くて汗が出る」と感じるレベル
hot_count += 1
elif disc >= 85: #「暑くてたまらない」と感じるレベル
too_hot_count += 1
⑤リスト型に格納
日単位のループが終了後、出来上がった値をそれぞれリスト型に格納します。
l_warm.append(warm_count) #年単位の「やや暑い」と感じる日の集計
l_hot.append(hot_count) #年単位の「暑くて汗が出る」と感じる日の集計
l_too_hot.append(too_hot_count) #年単位の「暑くてたまらない」と感じる日の集計
l_warm_high.append(warm_count) #l_warmの値を表示するy軸の値
l_hot_high.append(warm_count + hot_count)#l_hotの値を表示するy軸の値
l_too_hot_high.append(warm_count + hot_count + too_hot_count)#l_too_hotの値を表示するy軸の値
⑥グラフで出力
年単位のループが終了後、
値が目視できるようにグラフを成型しつつ、棒グラフを出力します。
# 値のが目視できるようにグラフ上に記載します。
# 3つの変数がそれぞれに表示されるように加工してます。
# もし、変数内の値が0の場合は表示されません。
for x, y, z in zip(year, l_warm_high,l_too_hot_high):
plt.text(x, round(y/2,0), str(y), ha='center', va='bottom')
plt.text(x,90,str(x)+"\ntotal\n"+str(z))
for x, y, z in zip(year,l_hot_high,l_hot ):
if z != 0:
plt.text(x, y-round(z/2,0), z , ha='center', va='bottom')
if too_hot_count == 0:
for x, y ,z in zip(year, l_too_hot_high,l_too_hot):
if z != 0:
plt.text(x, y-round(z/2,0), z, ha='center', va='bottom')
# タイトルの作成をします。
plt.title("hotday 1990 - 2018")
# それぞれに色と高さとどこから積み上げるのかを設定します。
p1 = plt.bar(year,l_warm,color="orange")
p2 = plt.bar(year,l_hot,color="#FF5B70",bottom=l_warm)
p3 = plt.bar(year,l_too_hot,color="red",bottom=l_hot_high,align="center")
# グラフ全体のサイズを設定します。
plt.plot(1990, 100)
グラフの表示
plt.show()
実行結果
※オレンジ⇒不快指数:75-80
※赤とオレンジの中間色⇒不快指数:80-85
※赤⇒不快指数:85-
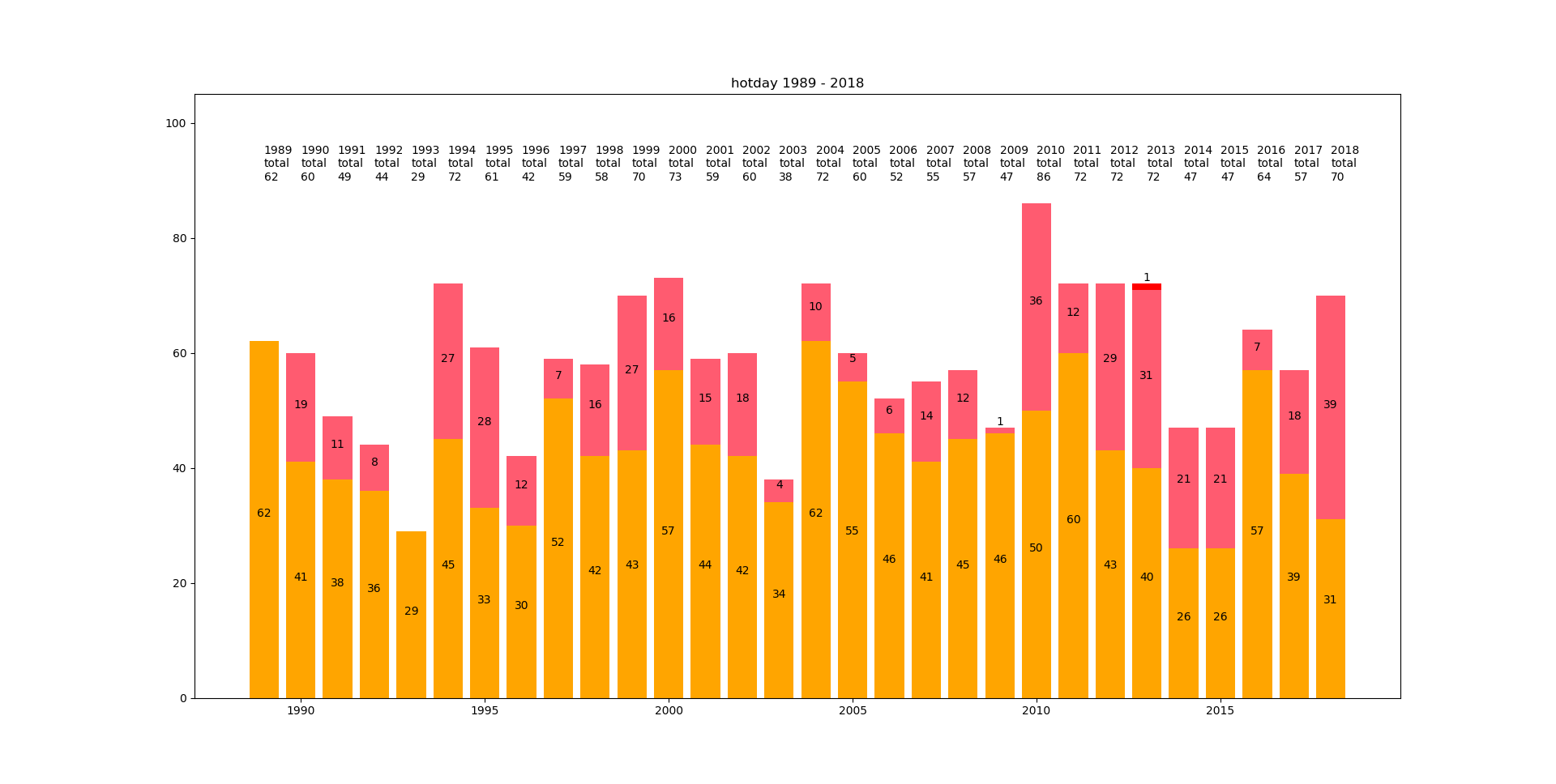
以上のグラフより、不快指数75以上の日の合計値の平均と標準偏差を出しました。
| 平均 | 標準偏差 |
|---|---|
| 58.87 | 12.48 |
10年ごとにグループにして平均値と平均+標準偏差以上のがいくつあるのかを
調査しました。
| 2018-2009 | 2008-1999 | 1998-1990 | |
|---|---|---|---|
| 平均値 | 63.4 | 59.6 | 53.6 |
| 平均+標準偏差(71.35)以上の年 | 4 | 2 | 1 |
年を追うごとに平均が増加し、平均+標準偏差を超える年も増えていることが分かります。
このことより、単純に「暑い」と感じられる日数が増えていることが分かります。
ところで「暑い」と感じられる日の中でも不快指数の高さはどうでしょうか?
グラフをパッと見た感じでは、不快指数80以上の値が増えている気がします。
そこで以下の方法で検証してみました。
不快指数80以上の日数をグラフ化
コメントの内容に従って、以下のコードを追記しました。
l_h_t_h = [] #ループ前の初期化に追記
l_h_t_h.append(hot_count + too_hot_count)#年次ループを抜ける直前に追記
# 以下処理終了直前に追記
for x, y in zip(year,l_h_t_h):
plt.text(x,39,str(x)+"\n"+str(y),ha='center', va='bottom')
p4 = plt.bar(year,l_h_t_h)
plt.show()
実行結果
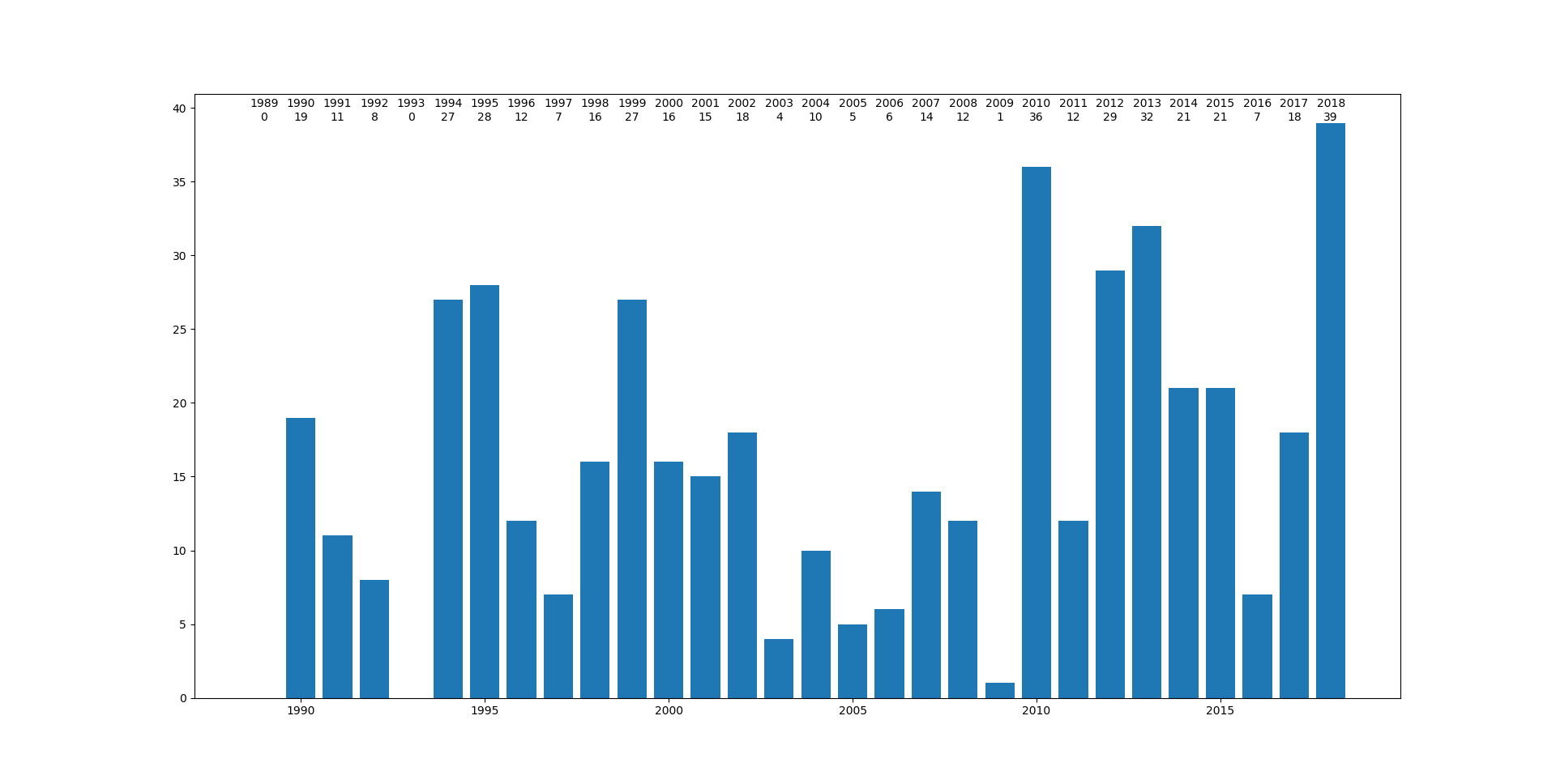
イレギュラーな年もありますが、
2010年以降は、不快指数80以上の日が増えているように思えます。
結論
以上の表やグラフから過去20年に比べて、
この10年で今まで以上に「暑い」と感じられる日数が増えているということがわかりました。
その中でも不快指数80以上の日が増えてきているので、暑さが苦手な私は非常に憂鬱です。