Synapse SQLプールは60のディストリビューションが存在する
Azure Synapse Analytics SQLプールには60のディストリビューションという物理的なディスクが存在します。
Synapse SQLプールに投入されるデータはこの60のディストリビューションに様々な方法で分散されて配置されることになります。
実際のデータをどのように分散配置するのかは指定することが可能で、テーブルの定義をするときに分散方法(ディストリビューション)を指定します。
3つの分散方法
Synapse SQLプールでは3つの分散方法が存在しています。
- ラウンドロビン分散
- ハッシュ分散
- レプリケート分散
ここではそれぞれの特長について簡単に記載します。
ラウンドロビン分散
全てのディストリビューションに均一にデータが配置されます。デフォルトがこの分散方式であり、テーブル作成時に何も指定しない場合は、この分散方式が指定されます。
指定方法は以下の通りです。
CREATE TABLE (…)
WITH (DISTRIBUTION = ROUND_ROBIN)
作成例
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL
)
WITH
(
DISTRIBUTION = ROUND_ROBIN
);
ハッシュ分散
ハッシュ分散は、ハッシュ分散アルゴリズムを使用してテーブルに投入されるデータを60のディストリビューションへ分散し格納する方式です。テーブルにはいくつもカラムが存在するかと思いますが、そのうちのどれか1つのカラムをHASH KEYとして指定する事で、そのカラムの値からハッシュ値を計算し、データをどこのストレージへ配置するのか決定します。
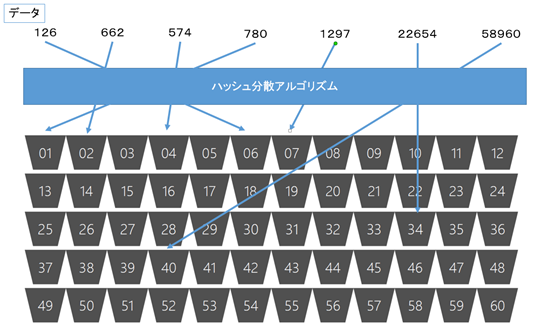
なので、この分散方式を指定することで、同じ値のデータは同じストレージに配置されることになります。
指定方法は以下の通りです。
CREATE TABLE (…)
WITH (DISTRIBUTION = HASH)
作成例
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL
)
WITH(
DISTRIBUTION = HASH ( O_ORDERKEY )
);
レプリケート分散
もともと、ラウンドロビン分散とハッシュ分散しか存在していませんでしたが、後に追加された分散方式です。
各コンピュートノードのディストリビューションデータベースに格納されるデータの完全なコピーを配置します。要するにすべてのコンピュートノード上に同じデータが保管されることになります。
Synapse SQLプールはテーブル同士の結合の際に、各ディストリビューション間でデータ移動(BROADCAST_MOVE等)が発生し、これがパフォーマンスへの影響につながりますが、このテーブル結合時のデータ移動(BROADCAST_MOVE等)の抑制を期待できます。
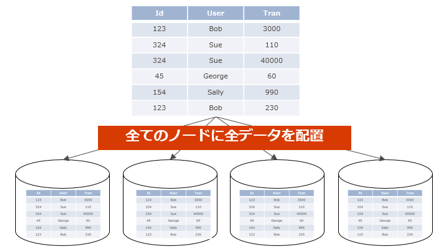
ただし、すべてのコンピュートノードに同一のデータを配置するという事は、せっかくのSynapse SQLプールの特長であるMPPによる分散処理のメリットを損ねる可能性もあります。なので、レプリケート分散を使用す際には以下のポイントに注意が必要となります。
- 圧縮後の容量が2GB未満のテーブルに使用する。
- 頻繁な、更新、追加、削除などDMLが行われないテーブルで使用する。
- 基本的にはディメンジョンテーブルで使用する。(ファクトテーブルとの結合が前提)
作成方法は以下の通りです。
CREATE TABLE (…)
WITH (DISTRIBUTION = REPLICATE)
CREATE TABLE NATION (
N_NATIONKEY INTEGER NOT NULL,
N_NAME CHAR(25) NOT NULL,
N_REGIONKEY INTEGER NOT NULL,
N_COMMENT VARCHAR(152)
)
WITH(
DISTRIBUTION = REPLICATE
);
まとめ
各分散方式の特長と、使いどころを簡単にまとめると以下のような感じになります。
| ラウンドロビン分散(デフォルト) | ハッシュ分散 | レプリケート | |
|---|---|---|---|
| 特徴 | ・全てのストレージにできるだけ均等に分散 ・ランダムに分散 |
・指定した列のハッシュ値に基づいて分散 ・同じ値は同じストレージに配置 |
・全てのノードに全てのデータを分散 ・テーブルのサイズは2GB未満が推奨 |
| 使い所 | ・大きなファクト表には適さない ・ローディングは最も高速 ・ステージングテーブルに使用 ・まずハッシュ分散を検討 |
・大規模ファクト表向き | ・小さなディメンション表向き |
終わりに
次の機会にデータ移動(BROADCAST_MOVE等)の観点を踏まえて、データの分散方式の選定を考えたいと思います。