順序指定クラスター化列ストアインデックス
Azure Synapse Analytics SQLプールではクラスター化列ストアインデックスに対してクエリーを実行すると、オプティマイザによって各セグメントの最小値と最大値がチェックされます。クエリ内のwhere句などを指定している場合、該当のセグメントにそもそも値が入っていないとオプティマイザが判断すると、当該セグメントは読み込まれずスキップされる仕組みとなります。順序指定クラスター化列ストアインデックスを利用することでテーブルにデータを格納する際に、指定した列でデータをソートして格納する事が可能となります。この為、クエリ実行時に読み込まれるセグメントの数が少なくすることができ、結果クエリのパフォーマンスが向上可能であるという機能となります。
順序指定クラスター化列ストアインデックスで高速化されるクエリのパターン
以下のようなパターンのクエリが実行される場合、順序指定クラスター化列ストアインデックスを用いることで早くなる可能性があります。
①対象のクエリ内のwhere句に等値(=等)、非等値(!=等)、範囲指定(BETWEEEN、>、<等)が存在している。
②①にて指定している列で順序指定クラスター化列ストアインデックスが構成されている。
順序指定クラスター化列ストアインデックスを作成する
順序指定クラスター化列ストアインデックスはCREATE TABLE文内に指定することで作成する事が可能です。
以下はLINEITEMのテーブルを例にL_SHIPDATE列を順序指定した順序指定クラスター化列ストアインデックスを作成するSQLです。
CREATE TABLE LINEITEM
(
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
) WITH (
DISTRIBUTION = HASH(L_ORDERKEY),
CLUSTERED COLUMNSTORE INDEX ORDER(L_SHIPDATE)
);
また、以下のSQLで順序指定クラスター化インデックスの情報を確認する事が出来ます。
SELECT
object_name(c.object_id) table_name
, c.name column_name
, i.column_store_order_ordinal
FROM
sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE
column_store_order_ordinal <>0;
順序指定クラスター化列ストアインデックス作成の際の注意点
本項では順序指定クラスター化列ストアインデックスを作成する際の注意点を記載します。
列におけるセグメントの範囲を確認する
順序指定クラスター化列ストアインデックスでは各セグメントの最小値と最大値が重複なく格納されている状態が最も望ましい状態となります。
以下のSQLで指定したカラムに対するセグメントの範囲(最小値、最大値)を確認する事が可能です。
SELECT
o.name
, pnp.index_id
, cls.row_count
, pnp.data_compression_desc
, pnp.pdw_node_id
, pnp.distribution_id
, cls.segment_id
, cls.column_id
, cls.min_data_id
, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE
o.name = '<テーブル名>'
and cols.name = '<カラム名>'
and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
以下は上記のSQLを順序指定クラスター化列ストアインデックスではない、通常のクラスター化列ストアインデックスにて実行した例です。
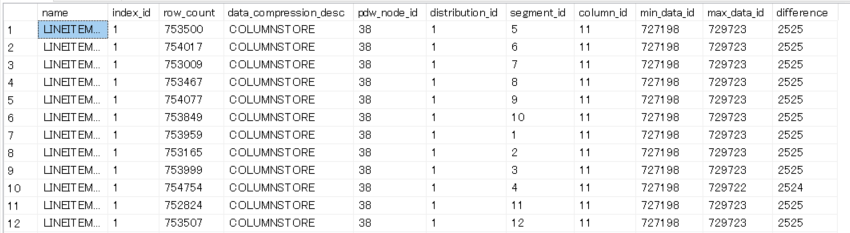
一方で以下が順序指定クラスター化列ストアインデックスにて実行した例です。
各セグメントの最小値、最大値にて重複が全く発生していない事が確認出来ます。(min_data_id、max_data_idを参照)

作成時、データロード時にはある程度大きなDWUcを指定する必要がある
「各セグメントの最小値、最大値が重複しない事が望ましい」と先ほど記載しましたが、これを実現するためには並び替えるデータのサイズによってAzure Synapse Analytics SQLプールの使用可能なメモリを調節する必要があります。
使用可能なメモリを調節する方法は、リソースクラスなどを使用してAzure Synapse Analytics SQLプール内のメモリを多く割り当てることと、Azure Synapse Analytics SQLプールのメモリそのものをDWUcを調整して多く割り当てるという事になります。
ちなみに、以下がDW100cで順序指定クラスター化列ストアインデックスを作成した例です。min_data_id、max_data_idに注目してください。
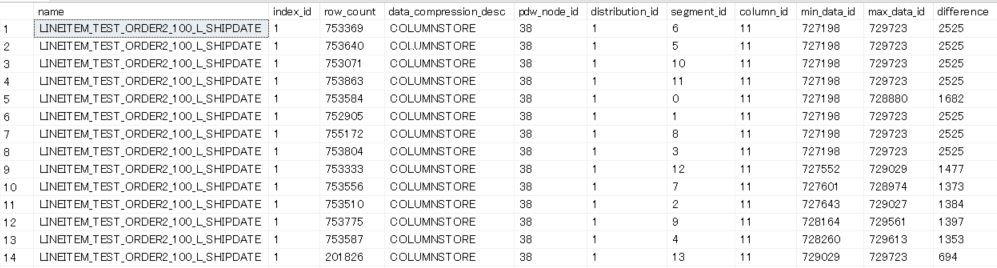
ほとんどのセグメントが重複してしまっている状態になります。
一方で、以下がDW1000cで順序指定クラスター化列ストアインデックスを作成した例です。こちらもmin_data_id、max_data_idに注目してください。

こちらはセグメントの重複が全くありません。
同じSQLでもメモリの割り当ての違いによってこれだけ差が生まれます。
MAXDOP=1を指定
順序指定クラスター化列ストアインデックスを作成する際に基本的には並列スレッドで作成が行われます。各スレッドがデータセットを独自にローカルで並び替えを行う仕組みとなり、各スレッドで並び替えられたデータがマージされてデータ全体で並び替えが行われるわけではありません。なので、並列スレッドで動いている特性上、どうしてもスレッドの数だけセグメントの重複が発生します。これを回避するために、MAXDOP(MAX Degree Of Prallelism)オプションをMAXDOP=1のように指定してやることで、単一スレッドで動くようになり「スレッドの数だけセグメントの重複が発生する」と言う事象を回避する事が出来ます。
※ただし、MAXDOP=1を指定すると単一スレッドでの処理になるので、並列スレッドに比べて作成する時間が延びる傾向があります。
また、MAXDOPオプションを指定可能なのは現時点はCTAS(Create Table As Select文)のみとなりますので注意が必要です。
以下はMAXDOP=1を指定したCTAS文の例です。
CREATE TABLE LINEITEM2
WITH (
DISTRIBUTION = HASH(L_ORDERKEY),
CLUSTERED COLUMNSTORE INDEX ORDER(L_SHIPDATE)
)
AS SELECT * FROM LINEITEM_TEST
OPTION (MAXDOP 1);
並び替えの範囲は単一のDMLやロード単位で実施される。
順序指定クラスター化列ストアインデックスでは指定した列においてデータは並び替えられて各セグメントへ格納されますが、この並び替えの範囲はDMLやデータロードが実行されるたびに毎回テーブル内のすべてのデータを並び替えするわけではありません。DMLやデータロード処理で新しく発生したデータの範囲(実行されたDMLやデータロードの範囲)で並び替えが行われます。
テーブル内のすべてのデータを並び替えする必要がある場合には再構築が必要です。
※ただし、Azure Synapse Analytics SQLプールでは再構築中は当該テーブルへのアクセスが全くできなくなるので、パーティション等利用して再構築を検討する必要があるかもしれません。
クエリの性能差
クラスター化列ストアインデックス(CCI)と順序指定クラスター化列ストアインデックス(順序指定CCI)でどれくらいの性能差があるのか確認してみました。
LINETEMテーブルがCCIの場合と順序指定CCI(L_SHIPDATE列で並び替え)の場合で、以下のクエリの速度の違いを確認しました。
DECLARE @startTime datetime2(1) = (SELECT GETDATE())
select count(*),YEAR(L_SHIPDATE) from LINEITEM
where L_SHIPDATE >= '1993/1/1' and L_SHIPDATE < '1993/2/1' group by YEAR(L_SHIPDATE) order by 1
SELECT DATEDIFF(ms, @startTime, GETDATE()) AS ElapsedTime_ms
結果

結果は順序指定CCIの方が若干早くなるという結果でした。
ロード性能
クラスター化列ストアインデックス(CCI)と順序指定クラスター化列ストアインデックス(順序指定CCI)ではデータロード時間にどれくらいの差が生まれるのか確認しました。
結果
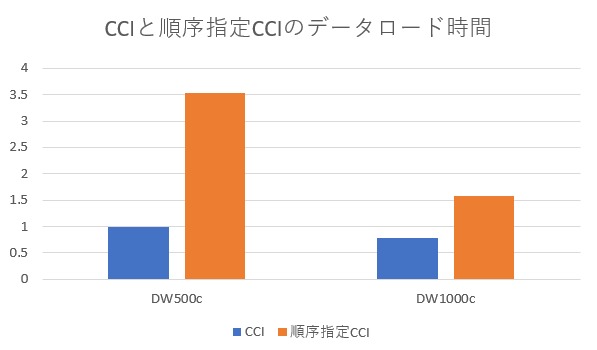
やはり順序指定CCIの方がロード性能は遅くなるようです。
最後に
上手く利用すればクエリのパフォーマンス向上に有効かもしれませんが、「ロードの性能が遅くなる」、「DWUcが小さいとそもそもセグメントがソートされない」など注意点をよく押さえてから利用を検討した方が良さそうです。