コンピューティングデータウェアハウスユニット(cDWU)
Azure Synapse Analytics SQLプールではデータベース全体の処理能力を**「コンピューティングデータウェアハウスユニット(cDWU)」**と言うもので指定します。DW100cが最小値で最大がDW30000cとなります。大きなcDWUを指定すると、全体のメモリの量も増え、さらにはコンピュートノードと呼ばれる、実際に処理を行うノードの数が増えます。すなわち、cDWUを大きくすれば、Azure Synapse Analytics SQLプールが高速になったり、大量の処理を行えるようになるという事になります。
このあたりの情報は以下の記事にまとめております。
Synapse SQLプールのスペックと3層構造の検証
ちなみに、cDWUが大きくなればなるほど、Azure Synapse Analytics SQLプールの金額は高くなります。
cDWUをどうやって見積もればいいのか
実際にAzureの利用金額に直結するcDWUの値ですが、実際にどのくらいの値を設定すればいいのかはとても悩みます。
システムを稼働させてみて、必要に応じて変更していくことができれば一番いいのですが、やはりAzure Synapse Analytics SQLプールを導入すると年間どれくらいのコストがかかるのかと言う観点では、cDWUをいくつで見積もりればいいのかが重要になってきます。
今回はこのcDWUの見積方法について考察してみました。
見積方法1:クエリの同時実行数からcDWUを見積り
Azure Synapse Analytics SQLプールはcDWUの値によって、同時に実行できるクエリの本数が決まっています。
1つ目はクエリの同時実行数からcDWUの値を見積もる方法です。
どのシステムでも大体どれくらいの同時実行数が必要かは検討すると思いますが、この同時実行数からcDWUがどれくらい必要なのかを見積もろうという事です。
cDWUとクエリの最大同時実行数は以下の通りです。

例えば、クエリの同時実行が40以上必要な場合には、上記のグラフの通りDW2000c以上を選択するとよいという事になります。
見積方法2:ロード処理能力でcDWUを見積り
Azure Synapse Analytics SQLプールはデータウェアハウス等の利用用途で使用されることが多いと思います。
なので、様々なシステムからデータをロードしてくる必要があると思いますが、データロードの処理能力によってcDWUを決定する方法です。
データロード処理能力も大きなcDWUにすればするほど高くなっていきますが、例えば10GBのデータを10分以内にロードを完了しなければならないという要件があった場合に、どのくらいのcDWUを設定すればこの要件が満たせるのかという観点で見積もりを行います。
つまり2つ目は必要なデータロード処理能力からcDWUを見積もろうという事です。
一方、これはマニュアルやドキュメントには記載が無かったので、実際に検証を行ってみました。
検証内容
・ロード処理:Polybaseによるロード
Polybaseについては「Azure Synapse Analytics SQLプールのPolyBaseについて」を参考にしてください。
・対象ファイル①:Azure DataLake Storage Gen2上に格納された60分割されたファイル
60ファイルの合計容量:74.11GB(1ファイルあたり約1.24GB)
ロード件数:600,037,902件
・対象ファイル②:Azure Blobストレージ上に格納された対象ファイル①をgzip圧縮したファイル
60ファイルの合計容量:22.05GB(1ファイルあたり約375.45MB)
ロード件数:600,037,902件
・実行リソースクラス:xlargerc
・ロード対象テーブル:HEAPテーブル/ラウンドロビン分散
上記の条件でDW100c~DW3000cでロードを実行し、ロード時間を測定しました。
ロード時間より、1GBの取り込みにかかった時間と、1時間あたりの推定取込可能量を推察しました。
※DW3000c以上は大人の事情で検証が出来ず。。。
検証結果
| 圧縮なし | gzip圧縮 | |
|---|---|---|
| DW100c | 36分59秒 | 39分11秒 |
| DW200c | 13分17秒 | 14分04秒 |
| DW300c | 12分13秒 | 11分33秒 |
| DW400c | 9分52秒 | 8分39秒 |
| DW500c | 6分30秒 | 5分39秒 |
| DW1000c | 3分44秒 | 3分43秒 |
| DW1500c | 3分0秒 | 2分45秒 |
| DW2000c | 2分7秒 | 1分42秒 |
| DW3000c | 1分40秒 | 72秒 |
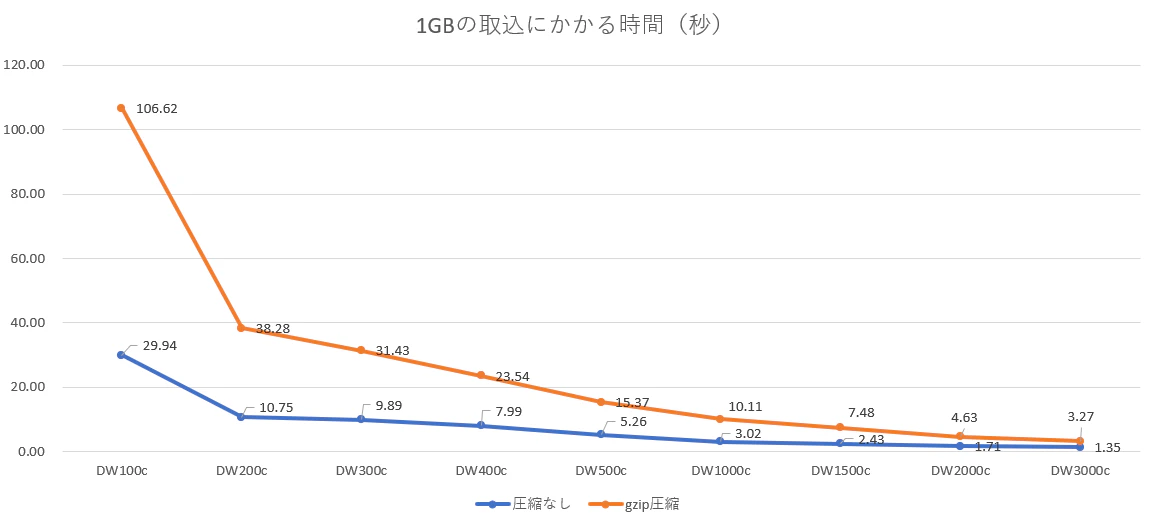
グラフにしてみました。(その1)
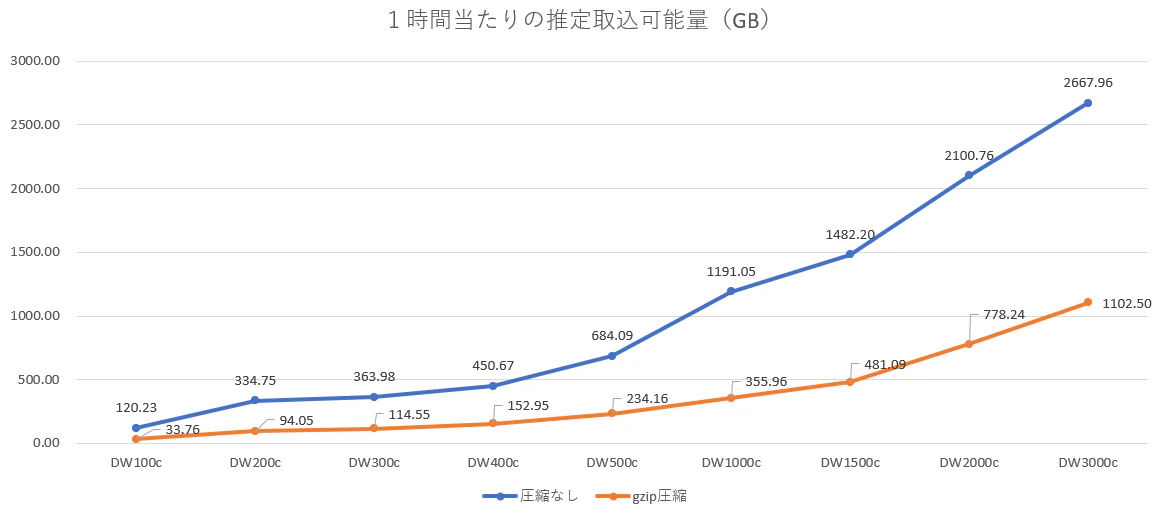
グラフにしてみました(その2)
今回の結果では、例えば、60秒以内に未圧縮の10GB程度のデータをAzure Synapse Analytics SQLプールへ取り込まなければならない場合、最低でもDW500c以上のcDWUの設定が必要であるとわかりました。
これが圧縮された状態で10GB程度のデータを60秒以内に取り込まなければならない場合は、最低でもDW2000c以上のcDWUのリソースが必要です。
また、2つ目のグラフから1時間以内に1TBのデータの取り込みが必要な場合には、未圧縮状態でDW1000cが必要であり、圧縮状態で1TBのデータであった場合はDW3000c以上が必要であるという事が分かりました。
ファイルを圧縮することにより取り込むデータ量そのものが減りますが、未圧縮のファイルを取り込むよりも、ロードに時間がかかりそうであることを念頭に置いておいた方が良さそうです。
最後に
Azure Synapse Analytics SQLプールをどのcDWUで稼働させるのか、一番最初はすごく悩むところであると思います。
この考え方や、検証の結果が少しでも役立ってくれればうれしいです。
おまけ:検証で使ったコマンド群
データの作成
データの作成はTPCHのデータを使用。
スケールファクターを100で設定し出力された「lineitem」のデータを使用。
手順は以下の記事を参照
TPC-Hを使ってテスト環境を作成する(Synapse SQLプール)
Polybaseの設定
--認証情報の作成
CREATE MASTER KEY;
CREATE DATABASE SCOPED CREDENTIAL AzureStorageCredential
WITH
IDENTITY = 'LoadSynapseDW',
SECRET = '<Blobストレージのキー情報>'
;
--外部データソースの作成
CREATE EXTERNAL DATA SOURCE AzureStorage
WITH (
TYPE = HADOOP,
--blobの情報を入力
LOCATION = 'wasbs://<コンテナ名>@<ストレージアカウント名>.blob.core.windows.net',
--上で登録した認証情報
CREDENTIAL = AzureStorageCredential
)
;
--フォーマットの作成(未圧縮ファイル用)
CREATE EXTERNAL FILE FORMAT TpchData
WITH (
--ファイルタイプ指定
FORMAT_TYPE = DelimitedText,
--区切り文字の指定
FORMAT_OPTIONS (FIELD_TERMINATOR = '|')
);
--フォーマットの作成(gzip圧縮ファイル用)
CREATE EXTERNAL FILE FORMAT TpchDataGz
WITH (
--ファイルタイプ指定
FORMAT_TYPE = DelimitedText,
--区切り文字の指定
FORMAT_OPTIONS (FIELD_TERMINATOR = '|'),
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.GzipCodec'
);
--外部表の作成(/data-s100-60/lineitem/の配下に未圧縮のファイル60ファイルを格納)
CREATE EXTERNAL TABLE dbo.EXT_LINEITEM
(
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
) WITH (
LOCATION='/data-s100-60/lineitem/',
DATA_SOURCE=AzureStorage,
FILE_FORMAT=TpchData
);
--外部表の作成(/data-s100-60-gz/lineitem/の配下にgzip圧縮したファイル60ファイルを格納)
CREATE EXTERNAL TABLE dbo.EXT_LINEITEM_Gz
(
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
) WITH (
LOCATION='/data-s100-60-gz/lineitem/',
DATA_SOURCE=AzureStorage,
FILE_FORMAT=TpchDataGz
);
ロード用のテーブルを作成
CREATE TABLE LINEITEM (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH(
DISTRIBUTION = ROUND_ROBIN,
HEAP
);
xlagercで動作するワークロード分類子の作成
masterデータベースでELTLoginユーザを作成
--masterデータベースでDBユーザー(ELTLogin)を作成
CREATE LOGIN ELTLogin WITH PASSWORD = '<パスワード>';
--masterデータベースにDBユーザー(ELTLogin)を追加
CREATE USER ELTLogin for LOGIN ELTLogin;
対象のデータベースでELTLoginユーザを作成し権限を付与。その後ワークロード分類子の作成
--ユーザデータベースにDBユーザー(ELTLogin)を追加
CREATE USER ELTLogin for LOGIN ELTLogin;
--DBユーザー(ELTLogin)にCONTROL権限を付与
GRANT CONTROL ON DATABASE::"<ユーザーデータベース名>" to ELTLogin;
--ワークロード分類子の作成
CREATE WORKLOAD CLASSIFIER wcELT WITH
( WORKLOAD_GROUP = 'xlargerc'
,MEMBERNAME = 'ELTLogin'
,IMPORTANCE = HIGH
);
Polybaseでのロード処理(ELTLoginユーザで実行)
--未圧縮の60のファイルからのロード
insert into LINEITEM select * from EXT_LINEITEM;
--gzip圧縮した60のファイルからのロード
insert into LINEITEM select * from EXT_LINEITEM_Gz;
cDWUの変更
以下は全てmasterデータベースで実行
--cDWUの変更
ALTER DATABASE "<対象のデータベース名>"
MODIFY (SERVICE_OBJECTIVE = 'DW<100~30000までで指定>c');
--cDWUの変更状態の確認
SELECT
*
FROM sys.dm_operation_status
WHERE resource_type_desc = 'Database'
AND major_resource_id = '<対象のデータベース名>';
--cDWUの確認
SELECT
db.name [Database]
,ds.edition [Edition]
,ds.service_objective [Service Objective]
FROM
sys.database_service_objectives AS ds
JOIN
sys.databases AS db ON ds.database_id = db.database_id
WHERE
ds.edition='DataWarehouse';