先月、ひょんなことがきっかけで、TVM のバックエンド開発に関わっていました。
そのときの成果をブログとしてまとめて、TVM のウェブサイト上に載せました。ぜひご覧ください。
開発の成果の例として、PyTorchで学習したモデルをAMDGPU 向けにコンパイルし、推論を実行、ということができるようになりました。
ここでは、上のブログの内容や、開発に参加するにいたった経緯、開発中のこぼれ話などを紹介したいと思います。
TVM AMDGPUバックエンドの紹介
TVMは、様々なハードウェア向けに Deep Learning 推論用の最適化コードを出力するための、ドメイン特化言語 + バックエンドコンパイラからなります。
僕が今回関わったのは、そのうちのAMDGPU向けバックエンドの開発です。このバックエンドは、TVMのLLVMコードジェネレータと、LLVMのAMDGPUバックエンドを組み合わせて、Pythonで書かれた計算表現を最適化されたAMDGPUのネイティブコードにコンパイルします。また、コンパイルしたコードを実行するためのランタイムも、バックエンド開発に含まれます。
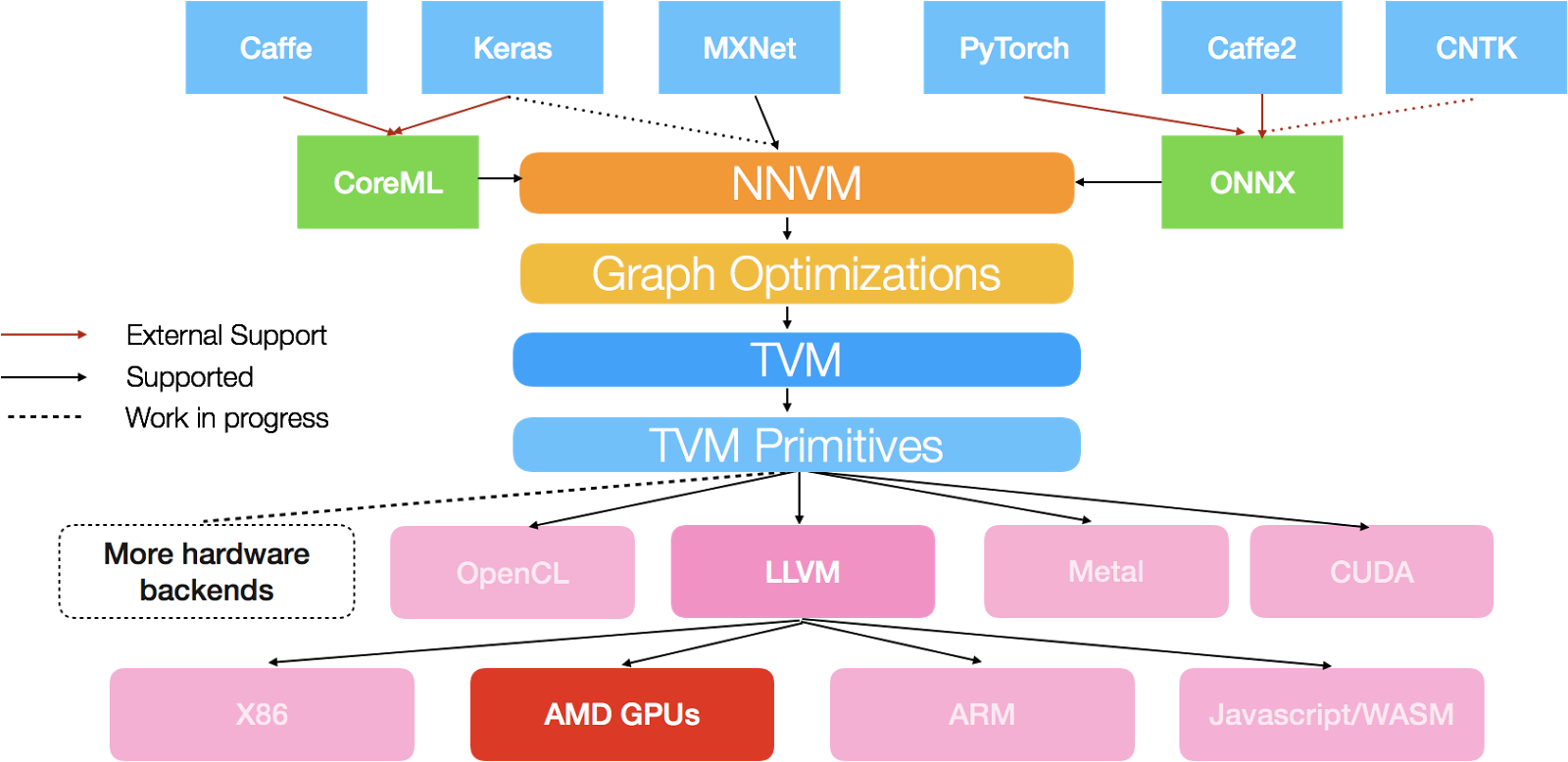
TVMには、NVIDIA向けにLLVMのNVPTXバックエンドを使ってコード生成するバックエンドもありますが、このバックエンドはlogやexpなどの数学関数がまだ使えません。そのため、AMDGPUバックエンドが、最初のLLVMベースGPUコードジェネレータということになります。
CUDAやOpenCLのバックエンドは、カーネルを文字列として出力して、コンパイルはNVCCやOpenCLのドライバに任せます。AMDGPUバックエンドは、ネイティブコードまでのコンパイルを、LLVMを用いてすべて自分たちで行います。
PyTorchで学習したモデルをAMDGPU上で動かす
今回開発したTVMのAMDGPUバックエンドとNNVMを組み合わせると、AMDGPUでPyTorchで学習されたモデルの推論ができるようになります。
PyTorchモデルをAMDGPUで実行するまでのステップは、以下のようになります。
- PyTorchモデルをONNXフォーマットでエクスポートする
- NNVMのONNXフロントエンドで、ONNXモデルをロードする
- 得られたNNVMグラフをAMDGPUバックエンドでコンパイル、実行
現状、PyTorch側の問題で、NNVMにロードできるONNXモデルは限られていますが、すでにかなり複雑なモデルもロードすることができます。例えば、この論文のモデルは37の畳み込み層とResidual connection からなる画像超解像ネットワークですが、NNVMでロード、AMDGPUバックエンドでコンパイル・実行することができます。実行すると、以下のような結果が得られます。

PyTorch側から必要なのはONNXファイルだけです。そのため、原理上ONNXサポートさえあればどのフレームワークのモデルでもNNVMでインポートし、AMDGPUで動かすことができます。ChainerのONNXサポートもPRには上がっているので、AMDGPUでChainerモデルが走る日もそう遠くないと思います。
開発に参加したきっかけ・開発中の出来事など
元々、Voltaが出るまでの時間つぶしと、AMDの新しいGPGPU環境であるROCmを試すためだけにAMDのGPUを買ったので、TVMの開発に参加するなど夢にも思っていませんでした。TVMとNNVMがリリースされてから、OpenCLバックエンドでPyTorchのモデルをAMDGPUで実行することに成功し、これは面白いと思ったのが、TVMとNNVMにはまったきっかけです。その後、どうやらAMDGPU専用のバックエンドもあるらしいということがわかったのですが、試してみても全く動きませんでした。そこで、Github上でAMDGPUのバックエンドを書いたAMDのエンジニアに質問したところ、まだランタイムにバグがあって、一か月間動かないまま放置されている、ということがわかりました。そのため、AMDGPUバックエンドは諦めようとしたのですが、なぜかそこから僕がランタイムのデバッグをすることになり、これが僕がTVMの開発に参加するきっかけとなりました。
幸い、ランタイムのバグはすぐにとれたので、次はバックエンド用のユニットテストに取り掛かりました。パスしないテストが5つありましたが、
- 数学関数を使えるようにした
- thread block のサイズが512より大きいとランダムな挙動をする場合があったので、thread blockのサイズを256までに制限した
- TVMのLLVMコードジェネレータ自体にバグがあった
以上を経て、AMDGPUバックエンドですべてのユニットテストをパスすることができるようになりました。
数学関数のサポートには手こずりました。最初はどうすれば実現できるかわかりませんでしたが、AMDのエンジニアやTVMの開発者のChenさんとディスカッションを重ねていくうちに、どうやらこのLLVMビットコードライブラリとTVMが生成するLLVM IRをリンクすればよい、ということがわかりました。TVMのLLVMコードジェネレータがよくできていたため、AMDGPU用の外部関数をリンクして使えるようにするためのコードは最小限に済みました。数学関数を使えるようになったので、Softmaxレイヤーなどが必要なImagenetのモデルが動くようになりました。
ユニットテストが全て通ったため、ひとまずこれでよしとし、ブログ記事の作成に移りました。
また、ランタイムのバグがとれてから初めて試した行列積(GEMM)のパフォーマンステストで、いきなり理論値の60%から65%のパフォーマンスが出ました。これはかなり見込みがあるのではないかと興奮しましたが、今回はカバレッジに精一杯で、パフォーマンスの向上などはまさにこれから、というところです。
感想・今後
ひょんなことがきっかけで始まったことから、大きな結果に繋げることができてとても嬉しいです。また、これが自分にとって初めてのオープンソースプロジェクトへの貢献でもあります。顔も見たこともなければ、名前をどう発音すればいいかわからないような海外の人たちと、Slack上でワイワイ盛り上がりながら開発を進めていくのは楽しいものでした。これからは、AMDGPU向けの最適化がメインのタスクとなります。GPUコードの高速化については初心者で、ましてやAMDGPU向けの最適化は初めてですが、これからも開発に関わっていけるように、くらいついていきたいと思います。
おまけ: TVM/NNVM のソースコードが面白い
TVM/NNVMの作者のTianqi Chenさん(超人)は、PackedFuncという独自の方法でC++とPythonの連携を可能にしています。コードベースを読むと、この仕組みを使って、C++からPythonのコールバックを呼ぶ、などの技が多用されていることがわかります。Boost.Pythonのような大きなライブラリを使わずにこのようなことができることだけでも面白いと思いますが、さらに面白い使い方があります。
NNVMによるネットワークのコンパイルは、以下のPythonの関数から始まります。
graph, lib, params = nnvm.compiler.build(
net, args.target, shape={"data": data_shape}, params=params)
この nnvm.compiler.build(...) は、この行でC++の関数を呼びます。
with target:
graph = graph.apply("GraphFusePartition").apply("GraphFuseCompile")
面白いのは、このPythonから呼ばれたC++の関数GraphFuseCompileが、さらに内部でPythonのコールバックを呼ぶ、という点です。
static const PackedFunc& fbuild = GetPackedFunc("nnvm.compiler.build_target");
tvm::runtime::Module module = fbuild(func_list, target);
このコールバックの定義は以下になります。
@tvm.register_func("nnvm.compiler.build_target")
def _build(funcs, target):
return tvm.build(funcs, target=target)
ここで呼ばれている関数tvm.build(...)は、TVM のコードジェネレータのエントリーポイントです。当然、コードジェネレータはC++で書かれています。以上からわかるように、TVM/NNVM のコードは、
Python calling C++ calling Python calling C++ ...
のように、PythonとC++を行ったり来たりするコールスタックをつくります。
そして、戻り値は逆をたどってやがてPythonに返ってきます。
よくこんなコードが書けるなと感心します。TVM/NNVMに限らず、MXNetなどのChenさんの他のコードも読んでみると面白い部分がたくさんあります。ぜひ読んでみてください。