内部で子プロセスが作られるコンテナ向けの話
環境
kubernetes: eks 1.21
node: amazonlinux2 kernel 5.4
前提など
kuberetes環境での Out of memory (以下OOM)は大きく2種類に分かれています
- cgroupOOM
- podのresourcesに設定したlimitにより引き起こされたOOM
- コンテナのmemoryがlimitに達すると再起動されるが、その際にOOMが発生している
- systemOOM
- cgroupOOMでない、kernelがまずいと判断して引き起こすOOM
今回の環境において
systemOOMはkubernetesのイベントに記録されます
cgroupOOMはイベントに記録されませんが、該当コンテナのstatusに再起動がカウントされ、reasonにOOMKilledと入ります
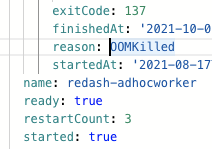
(kube-state-metricsを使えばprometheusのメトリクスとして扱えます)
不便なこと
cgroupOOMにおいて、コンテナが再起動されるのはメインプロセス(コンテナ内のpid:1)がkillされた時のみです
基本的にはこれで事足りるのですが、php-fpmやpythonのceleryなど、メインプロセスから子プロセスが発生して動作するようなものでは足りない場合があります
子プロセスがメモリを使ってOOMkilledされると、メインプロセスが新しく子プロセスを作って終了、となる場合です
実際にphp-fpmやceleryのコンテナを扱っているのですが、メインプロセスがkillされてコンテナが再起動する時もあれば、上記のように子プロセスだけがkillされてコンテナは作り直されないこともあります
そして、この子プロセスだけがkillされる状態は、何もしないと発生を知ることができません
メトリクスを見てメモリの動きが不自然だとか、nodeのsyslogを見るなどで知ることができます
ので、これらを検出して知らせてもらう仕組みを考えます
案1. node-probrem-detector
syslogやstatsなどを監視して異常を検出することができます
検出したら、イベントとして通知したり、prometheusのメトリクスで出したりできます
お手軽ですが、これでは足りない部分があります
OOMを検出した際に、OOMが起きたことやプロセス名は見てすぐにわかるのですが、たとえばphp-fpmのプロセスが落ちた場合、php-fpmのプロセスが落ちたことしかわからず、どのコンテナのphp-fpmプロセスが落ちたのかは、(メトリクスを見ればなんとなくわかりますが、)syslogを見てコンテナIDを見て、そのIDのコンテナは…と照合していく作業が必要になります
これらが気にならないなら設定も簡単なのでこれでよいかなと思います
案2. lokiのrecording rules
上記に比べると設定は多少複雑になりますが、色々と自動で繋げるやり方です
lokiの他に、kube-state-metricsとprometheusが必要になりますが、kubernetesモニタリングとしては基本セットなので許してください
recording rulesが使えるlokiのバージョンは2.3以降です
流れとしては
- promtailでnodeのsyslogをtargetに追加して保存する
- recording rulesでoomのログをメトリクス化してprometheusに保存
- kube-state-metricsのメトリクス
kube_pod_container_infoとjoinしてoomkilledのメトリクスとコンテナを紐付ける - あとはそれを元に通知するなりなんなり
といった流れです
細かく見ていきます
syslogをtargetに追加
journalの場合はpromtailのconfigにこんな感じのを追加で取得できます
- job_name: journal
journal:
path: /var/log/journal
max_age: 12h
labels:
job: systemd-journal
relabel_configs:
- source_labels: ['__journal__systemd_unit']
target_label: 'unit'
- source_labels: ['__journal__hostname']
target_label: 'hostname'
journalでない場合はわかりません ![]()
lokiのrecording rulesを設定
recording rulesを有効化する設定は終わっているものとして
(これに関しては別の記事で書くかも)
このようなruleを設定します
groups:
- name: oomkilling
rules:
- record: oom_killed_container_count_info
expr: sum by(uid,cid)(count_over_time({job="systemd-journal"} |~ "^oom-kill:" | regexp ".+task_memcg=/kubepods(/burstable)?/pod(?P<uid>[0-9,a-f].+)/(?P<cid>[0-9,a-f].+),task.+" [1m]))
これで、OOMが発生すると、oom_killed_container_count_infoという名前で、uid(=podのid)とcid(=コンテナのid)をlabelにしたOOMKillerがどのプロセスをkillしたのかのカウンター(厳密にはゲージ)メトリクスが作成されます
(今回結局uidは使わなかったんですけど)
kube-state-metricsのメトリクスと繋げる
以下のようなクエリでkube-state-metricsが出すコンテナ情報のメトリクスとjoinします
avg by(pod,container)(
label_replace(kube_pod_container_info,"cid","$2","container_id","(docker|containerd)://(.+)")
* on(cid) group_left
oom_killed_container_count_info
)
kube_pod_container_infoのcontainer_idはdocker://やcontainerd://が頭に付いてるので、label_replaceで取り除く必要があります
これで、どのpodのどのコンテナでOOMKilledが起きたかがすぐにわかるメトリクスが完成しました
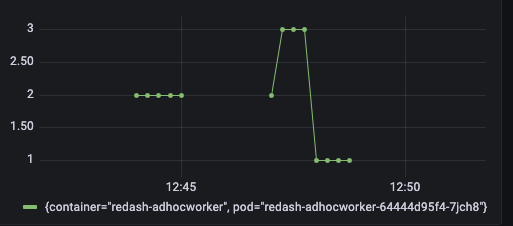
更に問題
この方法の結構な問題は、syslogをgrepとparseしているところで、
なにが問題かというと、OOMが発生した時のログ出力って意外とちょいちょい変更が入るんですよね
なので突然検出できなくなる可能性は大いにあります![]()
根本解決は
cgroupOOMも情報出してくれ、というkubernetesのissueがあります
https://github.com/kubernetes/kubernetes/issues/100483