AWSでサービスを運用する場合、ALB(ELB)はかなりよく使うサービスかと思います
私の運用しているサービスの場合はEKSクラスタへの入り口にALBがあり、全てのトラフィックはALBを経由してサービスにリクエストを行っています
動機
サービスを監視計測するにあたって、ロードバランサのメトリクスはわかりやすい基本になります
ALBのメトリクスにも、各ステータスのカウンタや、平均レイテンシのメトリクスがあり、役に立てている人も多いかと思います
しかしこのメトリクス、ALBの運用方法や取りたいデータ次第では少し足りない部分もあります
- バックエンドまで到達できずエラーになった場合、
HTTPCode_ELB_*_Countというメトリクスになり、どのTG(ターゲットグループ)に向けたリクエストがエラーになったのかがわからない- バックエンドが障害で落ちていたり、が高負荷で処理不能に陥った時これになる
- ひとつのALBに複数のTGを設定してトラフィックを分岐させていると困る
- パスやリクエストメソッドなどの単位で集計できない
- これは仕方ないでしょうけど…
後者なんかは、アプリケーション側でメトリクスを取得することが多いかと思いますが、結局前者のようなアプリケーションに到達できなかったエラーを無視することはできないので、結局ALBのメトリクスも監視せざるを得ません
そこで便利なのが、ALBのログです
ALBのログ
ロードバランサーに設定しておけば、S3バケットにログファイルを保存してくれます
上記のドキュメントを見てもらえばわかるように、情報も基本的なものは一通り揃っています
- 処理時間
- ステータス
- メソッド
- ターゲットのドメイン
- URI
などなど、このあたりを集計すればアプリケーション側でどうにかする必要なく、ALBのメトリクスよりも有用な指標が手に入ります
ログにはどのTGに向けたリクエストなのかは記録されませんが、リスナールールとログを照合すればわかるかと思います
保存先
ALBのログを集計することにしたわけですが、集計結果の保存先の選択があります
AWSのリソースのことなのでCloudwatchが無難かなとなるのですが、私の場合、k8sクラスタを運用していて基本的にモニタリングはprometheusを使用しています
RDSなどのマネージドサービスのメトリクスは仕方なくCloudwatchを見ていますが、できればprometheusで完結させたいのです
ので、今回は集計結果をprometheusに保存します
方法
流れ
ALBのログは、5分毎、ALBのノードごとにログファイルがS3に格納されます
このファイルの作成をLambdaでフックして解析し、pushgatewayに結果を送信
それをprometheusに持っていってもらうという流れでいきます
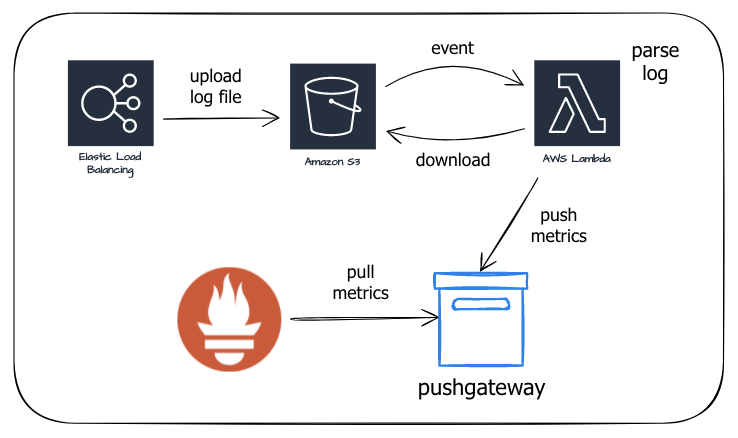
ただし、pushgatewayですが、カウンターメトリクスを作りたいという希望がありまして、今回こちらを使用しています
https://github.com/weaveworks/prom-aggregation-gateway
pushgatewayと同じように使えます
gaugeで問題なければおとなしく本家のpushgatewayでよいと思います
また、lambdaからpushgatewayはグローバルな接続になるのでpushgatewayにベーシック認証を入れて対応します
lambda
今回は、host、request_method、status、pathをlabelにして
- リクエスト数
alb_log_request_count
- 処理時間の合計
- 今回はbackend_processing_timeを集計する
alb_log_request_duration
- albエラー数
- backendに到達できかなった(backendがステータスを返さなかった)5xxの数
- メトリクス名
alb_log_elb_5xx
- backendエラー数
- backendが返した5xxの数
- メトリクス名
alb_log_target_5xx
counterだからか、メトリクス名の後ろに_totalが勝手に付くみたいです
通常の集計だと上のふたつで事足りるのですが、別件で5xxがbackendに到達したものかどうかが欲しかったので取ります
以下がlambdaで使用するpythonのスクリプトになります(クオリティは許して)
# -*- coding: utf-8 -*-
# 使用する環境変数
# USERNAME: pushgatewayのベーシック認証username
# PASSWORD: pushgatewayのベーシック認証password
# PUSH_ENDPOINT: pushgatewayのエンドポイント
from prometheus_client import CollectorRegistry, Counter, push_to_gateway
from prometheus_client.exposition import basic_auth_handler
import io, re, os, gzip, boto3
fields = [
"type",
"timestamp",
"alb",
"client_ip_port",
"backend_ip_port",
"request_processing_time",
"backend_processing_time",
"response_processing_time",
"alb_status_code",
"backend_status_code",
"received_bytes",
"sent_bytes",
"request_verb",
"request_url",
"request_proto",
"user_agent",
"ssl_cipher",
"ssl_protocol",
"target_group_arn",
"trace_id",
"domain_name",
"chosen_cert_arn",
"matched_rule_priority",
"request_creation_time",
"actions_executed",
"redirect_url",
"error_reason",
"target_ip_port_list",
"target_status_code_list",
"classification",
"classification_reason",
"new_field",
]
regex = r"([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\"($|.*)"
def auth_handler(url, method, timeout, headers, data):
username = os.getenv('USERNAME')
password = os.getenv('PASSWORD')
return basic_auth_handler(url, method, timeout, headers, data, username, password)
def purge_path(request_url):
regex = r"https?://[^/]+([^\?]*).*"
match = re.match(regex, request_url)
uri = match.group(1)
return uri
def register_metrics(registry, elb_5xx, target_5xx, requests_total, duration_total, file_obj):
for row in file_obj.readlines():
matches = re.findall(regex, row)
if matches:
log = dict(zip(fields, list(matches[0])))
label_values = [log['domain_name'], log['request_verb'], log['alb_status_code'], purge_path(log['request_url'])]
requests_total.labels(*label_values).inc()
duration = float(log['backend_processing_time'])
if duration < 0:
duration = 0 # 404など、backend_processing_timeに-1が入ることがあり、そのままだとinc()でエラーになるので0にする
duration_total.labels(*label_values).inc(duration)
if int(log['alb_status_code']) >= 500:
if log['backend_status_code'] == '-':
elb_5xx.labels(*label_values).inc()
else:
target_5xx.labels(*label_values).inc()
return registry
def get_log_file(bucket, key):
s3_client = boto3.client('s3')
obj = s3_client.get_object(
Bucket=bucket,
Key=key
)['Body'].read()
file = gzip.open(io.BytesIO(obj), 'rt')
return file
def lambda_handler(event, context):
registry = CollectorRegistry()
label_keys = ['host','request_method','status','path']
elb_5xx = Counter('alb_log_elb_5xx', "A counter of elb_status_code 5xx", registry=registry, labelnames=label_keys)
target_5xx = Counter('alb_log_target_5xx', "A counter of target_status_code 5xx", registry=registry, labelnames=label_keys)
requests_total = Counter('alb_log_request_count', "Rows of alb log", registry=registry, labelnames=label_keys)
duration_total = Counter('alb_log_request_duration', "Total duration of alb log", registry=registry, labelnames=label_keys)
records = event['Records']
for record in records:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
file_obj = get_log_file(bucket, key)
register_metrics(registry, elb_5xx, target_5xx, requests_total,duration_total, file_obj)
push_to_gateway(os.getenv('PUSH_ENDPOINT') , job='dummy', registry=registry, handler=auth_handler)
コメントの通り環境変数を設定します
ベーシック認証が必要なければよしなに外してください
ここでは省略していますが、実際はhostとkubernetes内のアプリケーションを紐付けるためのlabelをつけたり、pathを正規化する処理などを入れたりしていますので、環境に応じて追加すると便利になるかと思います
トリガーは、albログ保存先のS3バケット・プレフィックスを指定して、イベントタイプObjectCreatedByPutを指定します
pushgateway
前述の通り、prom-aggregation-gatewayになるのですが、これは特に複雑な設定はないです
apiVersion: apps/v1
kind: Deployment
metadata:
name: prom-aggregation-gateway
labels:
app.kubernetes.io/name: prom-aggregation-gateway
spec:
strategy:
type: RollingUpdate
selector:
matchLabels:
app.kubernetes.io/name: prom-aggregation-gateway
revisionHistoryLimit: 3
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/name: prom-aggregation-gateway
spec:
containers:
- name: pushgateway
image: weaveworks/prom-aggregation-gateway:latest
imagePullPolicy: IfNotPresent
args:
- '-listen=:9999'
ports:
- containerPort: 9999
---
apiVersion: v1
kind: Service
metadata:
name: prom-aggregation-gateway
labels:
app.kubernetes.io/name: prom-aggregation-gateway
spec:
type: ClusterIP
ports:
- port: 9999
name: internal
selector:
app.kubernetes.io/name: prom-aggregation-gateway
ingressやベーシック認証部分は運用状況によるところがあるのでよしなにお願いします
prometheus周りの設定は省略します
見る
情報量は少ないですが、こんな感じで集計できています
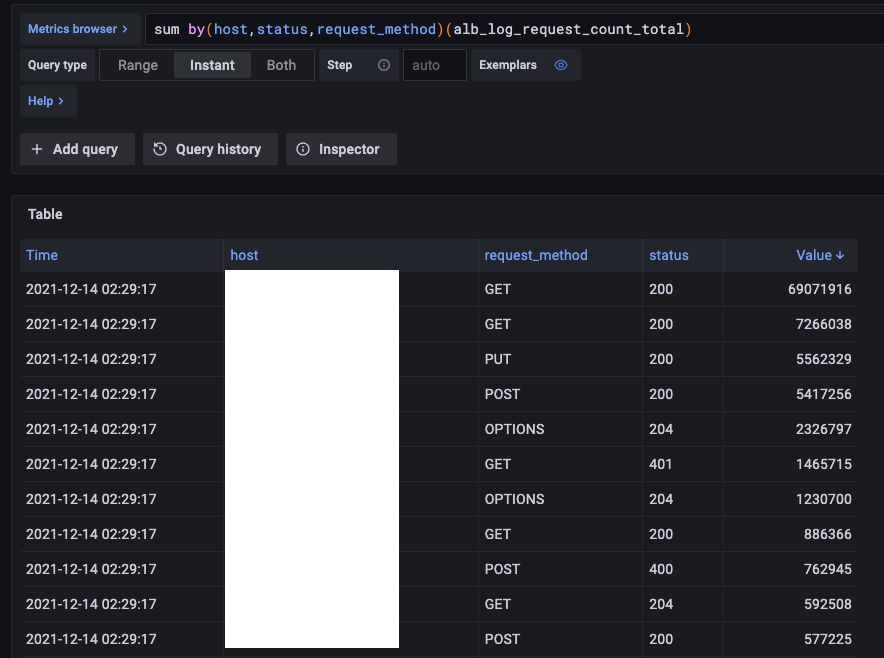
注意事項
- ログ記録はベストエフォートになっており、全てのリクエストが記録されることは約束されていない
- そうは言ってもそんなごっそり欠けることはないのでは?
- ログが出るのが5分ごとなので、リアルタイム監視にはあまり向かない…
- ここまでやっておいて…

- ここまでやっておいて…
- lambdaスクリプトは不具合や考慮漏れがあるかも