重みの初期値
重みの初期値によってNNの学習の成否が分かれることがある。
理想:重みの値を小さくし、その分布もできるだけ均等にする。
→アクティベーションの偏りが小さくなり表現力が向上
→結果的に、過学習を抑えられ、汎化性能が向上する
「アクティベーション」 = 「活性化関数の後の出力データ」
なぜアクティベーションが偏るとまずいか?
例えば、Sigmoid関数
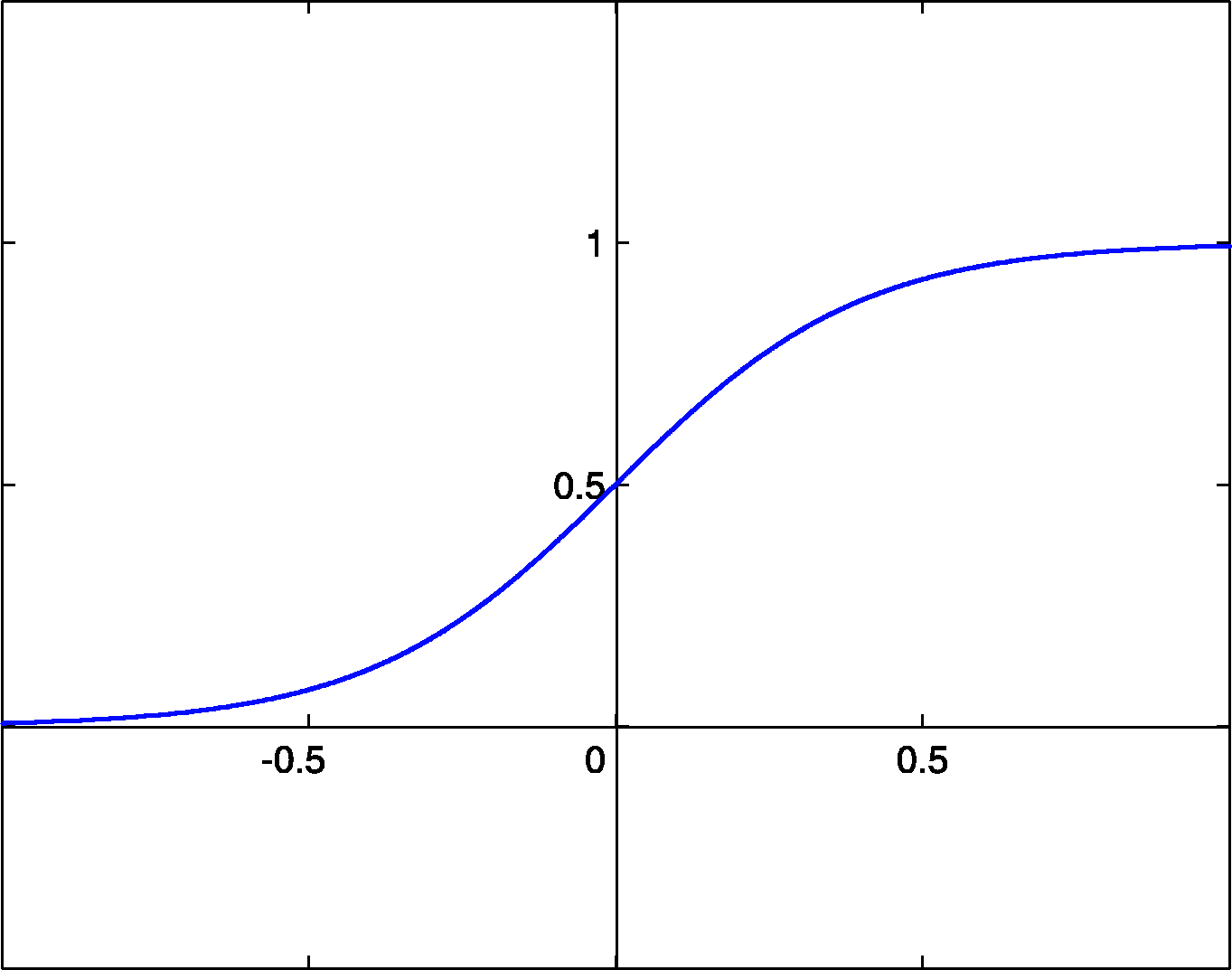
アクティベーションは活性化関数後の値である。
この値がもし0や1に偏っていた場合、その勾配はほとんど0であることが分かる。
この勾配が0になることが非常にまずい。なぜかというと逆伝搬の際、勾配の値が出力層から降りてくるにつれてどんどん小さくなってしまうからである。これが勾配消失(gradient vanishing)と呼ばれる問題。
活性化関数ごとの推奨初期値
| 活性化関数 | 初期値 |
|---|---|
| Sigmoid, tanh(中法付近が線形関数) | "Xavierの初期値" |
| ReLU | "Heの初期値" |
Xavierの初期値
目的:各層のアクティベーションを同じ広がりのある分布にすること
アルゴリズム:前層のノードの数を $n$ とした場合、$\frac{1}{\sqrt{n}}$ の標準偏差を持つガウス分布で重みを初期化する
※活性化関数に用いる関数は、原点対称であることが望ましい性質とされている。
Heの初期値
アルゴリズム:前層のノードの数を $n$ とした場合、$\frac{2}{\sqrt{n}}$ の標準偏差を持つガウス分布で重みを初期化する
Batch Normalization
ポイント:強制的にアクティベーションの分布を調整する
Batch Normの利点
- 学習を早く進行させることができる
- 初期値にそれほど依存しない
- 過学習を抑制する