結論から先に言うと
自分が知っている限り、スクレイピングをせずに競馬のデータを取得するには大きく分けて3つある
基本的にすべて有料
毎週・毎日最新のデータを手に入れるには、継続して費用を払う必要がある。
一方で、過去のデータについてはまとめて取得しておけば、再度そのデータを閲覧するためには費用は掛からない。
(DBやローカルに保存されているので)
-
JRA-VAN DataLab
- 中央競馬のデータを取得することができる。
- 主に.NET Framewoerk系の言語でデータを取得することができる。
- 後述の方法で、RDB経由でデータを取得することができる
- レース情報や、成績など基本的なデータは揃っているが、調教やパドックなどのデータについてはイマイチ。
- スマホアプリのJRA-VANの利用権も含まれているので、レースや、パドック映像なども、スマホから見ることができる
- 月額2090円
- https://jra-van.jp/dlb/
-
地方競馬DATA
- 地方競馬のデータを取得することができる
- ばんえい競馬のデータもある
- 基本的に個々人で地方競馬DATA向けのアプリケーションを自作することはできない
- が、後述の方法で、地方競馬DATAをRDBに取り込んで集計することができる
- データのフォーマットは、JRA-VAN DataLabとほぼ同じフォーマット
- DataLabでは提供されているが地方競馬DATAでは提供されていないデータなどもある(レースごとの脚質など)
- 月額1800円
- https://saikyo.k-ba.com/members/chihou/
-
JRDB
- 中央競馬のデータを取得することができる。
- 主にデータはテキストファイルをダウンロードすることで取得することができる。
- JRA-VAN DataLab同様、基本的なレース情報や成績は網羅されている。
- パドックや、馬場が内外どれだけ荒れているかなど、細かい情報も取得できる。
- 配布されているデータのパーサを書く必要がある。
- 月額2000~3500円ほど
- http://www.jrdb.com/
どのデータを使うと良さそうなの?
- 中央競馬だけ予想するなら、JRDBのみでデータは大方賄えそう。ただし、データのパーサは自分で書く必要がある。
- 中央競馬と、地方競馬両方予想するなら、DataLabのフォーマットに沿ってデータを取得すると、地方競馬にも対応しやすい
自己紹介
こんにちは、まさちゃこといいます。
普段は、競馬AI開発系 VTuberユーミィちゃんの、技術支援をしています。
ユーミィちゃんは、主に競馬AIの予想をつぶやいたり、各レースに関する動画を投稿したりしています。
予想は中央競馬の予想がほとんどで、たまに地方競馬の予想も呟きます。
予想は↓のような形です。
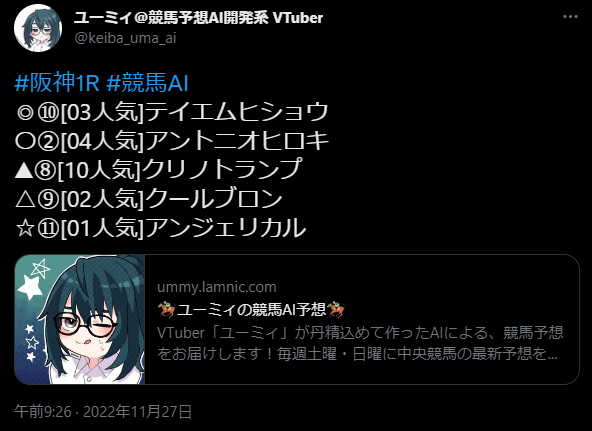
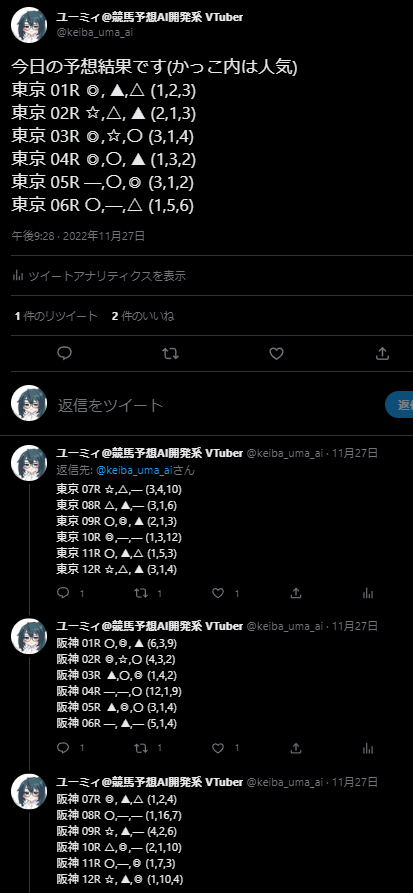
先週の結果はこんな感じです。結構穴目も拾ってくれていました。
人気どころもそこそこ押さえつつ、10人気や、9人気も拾えるようになったのが嬉しいです。
もしよければ、ユーミィちゃんを応援してあげてください(∩´∀`)∩
自己紹介
私も例に漏れず、ウマ娘から競馬の詳細を知ったタイプです。
そのため、競馬歴は1年ちょいほどになります。
知り合いと試しに予想をし、競馬の馬柱が見づらかったため、自作のビューアや、ツールを作っているうちに
競馬AIを作り、ユーミィちゃんの裏方をすることになりました。
最初は、人力で競馬予想をしていたのですが、馬柱や新聞の見づらさに困っていました。
というのも、馬毎のデータを比較したいはずなのに、馬柱や新聞はソートやフィルタリングなど、
比較のための機能は備わっていないからです。
そこで、最初は、個人用に馬毎のデータをスクレイピングで集め、
比較するためのツールを作っていました。
競馬データ比較ツール作成から、競馬AI作成への着手
自作ツールで比較するようになってから、しばらくして、大体データはここら辺を見れば良いな。
ということが分かってきます。
となると、自分が着目しているデータに基づいて、データから、自分の好みであろう順に馬さんを表示する機能が欲しくなります。
最初は、手動でデータを集計し、計算式を作り、おススメの順に表示していました。
が、やはり、手動ではデータが膨大でうまくいかず、機械学習で競馬AIを作ることになりました。
スクレイピングをあきらめる
競馬AIを作るにあたって、スクレイピングはあきらめようという気持ちが、最初にありました。
理由とはしては
- 恐らく後々、膨大なデータをAIに渡して学習させたくなるので、スクレイピングではデータを収集に時間がかかりすぎるようになる
- スクレイピング先がリニューアルすると、プログラムを大幅に書き直す可能性が出てくる
- スクレイピングしたデータの後処理などで、AI開発以外に大幅に時間を割いてしまう
というものでした。
そのため、別途、標準化されたデータを取得できる方法を探しました。
データの取得元の選定
ということで、スクレイピングはあきらめて、お金を払ってデータを買うことにしました。
その、主なデータの取得元が下記の3つです
- JRA-VAN DataLab
- JRDB
- 地方競馬 DATA
各データを使いこなすまでに、紆余曲折ありましたが、大体半年~1年ほど使ってみたものをまとめてみます。
JRA-VAN DataLab
言わずもがな、中央競馬を開催しているJRA公式の中央競馬のデータです。
JRA-Datalabは、仕様書が提供されているので、どのようなデータが取得できるのか見ることができます。
(PDF版仕様書)
JRA-VAN DataLabは、.NET Framework向けのSDKが公開されており
JRA-VAN DataLabを使用するアプリの開発マニュアルなども公開されています。
JRA-VAN DataLabのデータをPostgresSQLにインポートする
私には.NET Frameworkに関する開発知識がありませんでした。
C#などを習得するのも手ですが、調べてみるとどうやらDataLabのデータをPostgreSQLにインポートするツールが公開されているようです。
DataLabのアプリとしても紹介されており、DataLabのデータをDBにインポートして使用することには問題ないようです。
PC-KEIBAを利用してDataLabのデータを取り込む上でのデメリット
PC-KEIBAは過去のレースデータを無料でPostgreSQLに取り込むことができます。
一方で、リアルタイムオッズや、レース直前(1時間前)の馬体重、馬場状態を取得するには、PC-KEIBAの有料会員(\980月)に登録する必要必要があります。
継続して運用するのであれば、自力で.NET FrameworkのSDK経由で開発するのがいいのかもしれません。
JRA-VAN DataLabではどんなデータが取れるの
Postgresに取り込んだデータを元に、「a5m2」でER図を生成してみました。
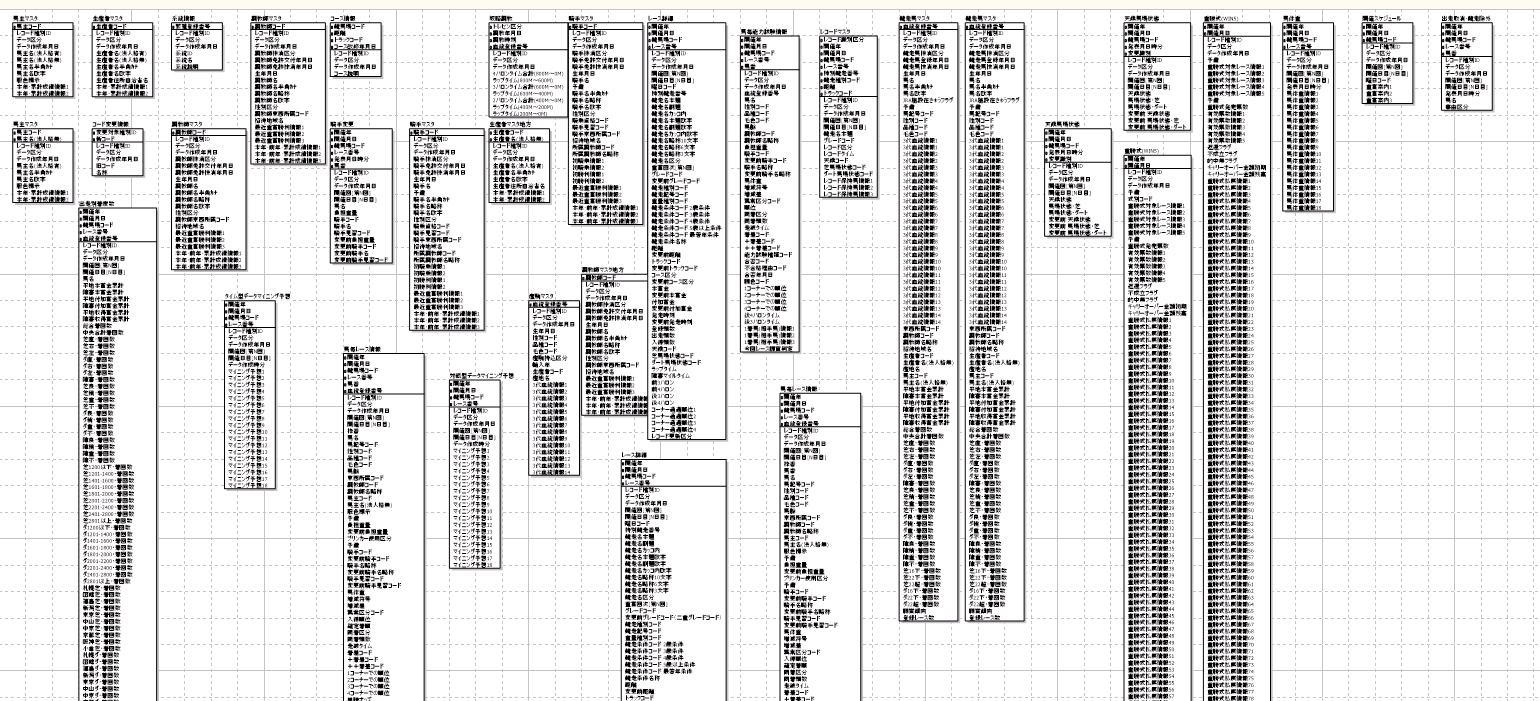
めっちゃデータあるー。
次の章で主なテーブルについて説明します。
大雑把にAI予想に必要なデータのとり方を説明する
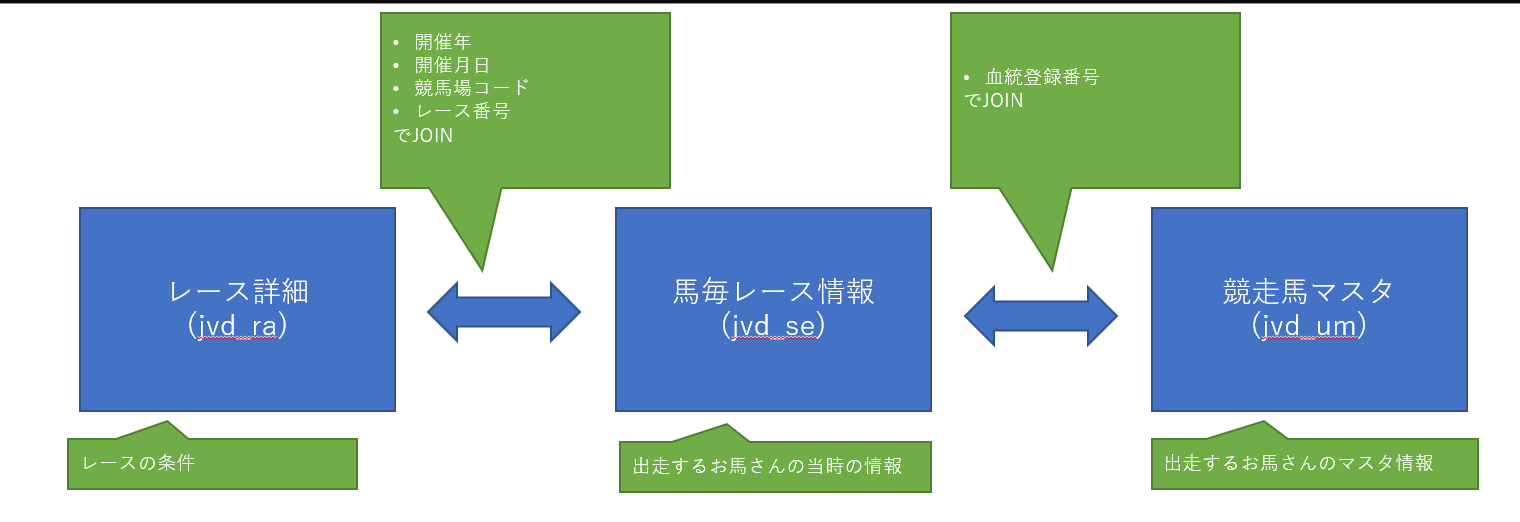
大まかに、JRA-DataLabを使用すると、以下のようなデータの取得方法になると思います
- レース詳細(jvd_raテーブル)を取得する
- そのレースに対応する、馬毎レース情報(jvd_se)を取得して、レース詳細にJOINする
- 馬毎レース情報に対応する競走馬マスタを取得して、馬毎レース情報にJOINする
JRA-VAN DataLabのデータを、PC-KEIBA経由でPostgreSQLに取り込んだ場合の注意点
JRA-VAN DataLabの各データは固定長で管理されています。
例えば、レースの「開催月日」というデータは、4バイトで管理されており、4バイトに満たない分は0埋めされています。
具体的な例を挙げると、1月1日のレースなら、「0101」という4桁の形式で格納されているということです
そのほかにも、馬名には、36バイト分のデータ領域が用意されています。36バイトに満たない分は空白スペースで埋められています。
そのためSQLのwhereに「bamei = 'ディープインパクト'」と指定しても検索に引っかかりません。
「bamei like 'ディープインパクト%'」 としてやる必要があります。
基本的に、数値で表すことのできるデータは0埋め、表すことのできないデータはスペースで埋められているようです。
PC-KEIBA経由で、PostgresSQLに取り込んだ、DataLabのよく使うデータ
PC-KEIBA経由で、PostgreSQLに取り込んだデータは、先述のDataLab仕様書とおおよそ対応付いているようです。
その、DataLabのデータで主に競馬予想AI開発に使用するであろうデータとテーブルについて紹介します。
私は.NET Frameworkに関する知識が無いため、 これ以降は、PC-KEIBAに取り込んでPostgreSQLに取り込んだ前提で
データの紹介をします。
レース詳細 (テーブル名:jvd_ra)

開催されるレースそのものの、詳細です。
- 開催年(カラム名:kaisai_nen/例:2022)
- 開催月日(カラム名:kaisai_tsukihi/例: 1127)
- 競馬場コード(カラム名:keibajo_code/例: 05)※東京競馬場の競馬場コード
- レース番号(カラム名:race_bango/例: 11)
の情報をキーに引くことができます。SQLにすると
select
*
from
jvd_ra
where
kaisai_nen = '2022'
and kaisai_tsukihi = '1127'
and keibajo_code = '05'
and race_bango = '11';
のようになるはずです。
このテーブルからは、開催されるレースの
- 距離
- 競馬場
- 出走時刻
- 使用されるトラック
- 賞金
などを取得できます。
注意点としては、
既に「結果の出ているレース」についての「馬場状態」や「天候」などはこのテーブルから取得することができます。
しかし、開催前の「馬場状態」や、「天候」などはこのテーブルから取得することができません。
別途リアルタイムの天候情報のテーブル(jvd_we)から取得する必要があります。
そのため、レース直前の予想をするのであれば、リアルタイムの天候情報テーブルから情報を取得する必要があります。
また、このレース詳細テーブルには、「出走頭数」というカラムがあります。
が、このカラムは「実際に出走した頭数」が入ります。
「出走頭数」のカラムは、直前の出走取り消しや、中止などを含めて実際に出走した馬の頭数が入ります。
そのため、「レース出走前」には、このカラムにはデータが入っていません。
いわゆる「18頭立て」といった、「このレースで何頭走る予定なのか?」という情報は「登録頭数」のカラムより取得することができます。
馬毎レース情報 (テーブル名: jvd_se)
レースに出走する、お馬さんの「出走する当時」詳細です
- 開催年(カラム名:kaisai_nen/例:2022)
- 開催月日(カラム名:kaisai_tsukihi/例: 1127)※11月27日
- 競馬場コード(カラム名:keibajo_code/例: 05)※東京競馬場の競馬場コード
- レース番号(カラム名:race_bango/例: 11)
- 馬番(カラム名:umaban/例01)
をキーに引くことができると思います。
AI用のデータを作る際は、先ほどの「レース詳細」にこの「馬毎レース情報」をJOINしていくことになるはずです。

見ての通りこのカラムでは、出走するお馬さんの当時の情報を取得することができます。
騎乗する騎手や、当時の調教師、馬主、負担重量などを取得できます。
また、レースの結果・着順もこのテーブルに格納されます。
が、ここでもリアルタイムデータに関しては注意する必要があります。
レース直前でもここには、「馬体重」や「馬体重増減」「人気」など直前にリアルタイムで変化する情報はセットされません。
レース終了後にセットされます。
馬の直前情報を取得したい場合は、別途「apd_sokuho_se」テーブルを参照して、直前情報を取得する必要があります。
競走馬マスタ (テーブル名: jvd_um)
お馬さんのマスタデータが入っているテーブルです
- 血統登録番号(カラム名:ketto_toroku_bango/例:2002100816)
をキーに引くことになると思います。
血統登録番号は、お馬さんごとのプライマリーキーと思ってもらって、ほぼ問題ないと思います。

お馬さんの血統や、プロフィールについて取得することができます。
馬名や、性別、毛色、誕生日などもこのテーブルに入っています。
芝で何回1位になったなどの情報もあります

が、これは、レースごとに毎回更新されるので、AI予想では使うことはあまり、無いと思います。
(過去のレースでこのデータを使用すると、未来の情報がリークしてしまうため)
坂路調教 (テーブル名: jvd_hc)
調教データもあるにはあります・・・

が、上記を見ての通り
「どのような追い方をしたたのか」「どのコースを走ったのか」
という情報が無いので、活用しづらい状態です。
また、どのレースに対応する調教かも「調教年月日」を元に推測する必要があります。
その他のデータ
そのほかには、騎手や、馬主、オッズなどのデータも取得することができます。
一方で、騎手の各レース当時の勝率などは自力で計算・集計する必要があります。
競馬場や、トラックのマスタデータはどこにあるの???
これまでに「競馬場コード」という単語が出てきました。
その名の通り、どこの競馬場を表すかのコードです。(競馬場コード「05」なら東京競馬場といった具合)
また、このレースは「芝」なのか、「ダート」なのか。
内回りなのか、外回りなのか。左回りなのか右回りなのか。
を判別するために「トラックコード」というものがあります。
そのコードに対応するマスタデータはどこにあるのでしょうか。
答えは JRA-VAN DataLabの仕様書末尾です。
ここから、マスタデータテーブルを自分で起こすか、JSONなどのマスタファイルを作成する必要があります。
レース条件戦の条件はどこから取得することとができるの?
レースには、出走のための条件があります
例えば「2歳未勝利戦」であれば、2歳の1度も1着になったことのない馬しか出走することはできません。
それらの条件はどこから取得できるかというと、「レース詳細」の
「競走条件コード」に記載されています。

ここの、各年齢ごとの条件にマッチした馬が出走できることになります。
「競走条件コードの詳細は」仕様書の「2007.競走条件コード」から確認することができます。
レースタイトルから、レースの条件を引くことはできません。
例えば、「2歳未勝利戦」というタイトルはどこにも格納されていません。
DataLabについてのまとめ
.NET Frameworkの開発経験が無い場合外部プログラムに頼る必要がある
PC-KEIBAを利用して、予想のためにリアルタイムデータを使用する場合、更に月1000円上乗せなのが辛い
パドックでの状態や、調教の追い方など主観を要するデータは少し弱い
地方競馬DATA
より購入できる地方競馬DATAは、その名の通り地方競馬のデータを取得することができます。
JRA-VAN DataLabと違って 個人開発用のSDKは公開されていません。
ですが、先述のPC-KEIBAを利用してJRA-VAN DataLabと同様に、PostgreSQLに取り込むことができます。
取り込み方については、PC-KEIBAのHPや、地方競馬DATAのセットアップ方法を参照してください。
これ以降は、地方競馬DATAをPC-KEIBAで取り込んだ場合のデータ構造について説明します。
地方競馬DATAをPC-KEIBAで取り込んだ場合のデータ構造
地方競馬DATAをPC-KEIBAで取り込んだ場合のデータ構造は、JRA-VAN DataLabとほぼ同じになります。
JRA-VAN DataLab向けに作成されたテーブルの「jvd_」を「nvd_」とすると、地方競馬向けのデータを取得できます。
つまり。
JRA-VAN DataLabでは
レース詳細(テーブル名:jvd_ra)
馬毎レース情報(テーブル名:jvd_se)
競走馬マスタ(テーブル名:jvd_ra)
というテーブルに格納されていましたが、
地方競馬向けのデータは
レース詳細(テーブル名:nvd_ra)
馬毎レース情報(テーブル名:nvd_se)
競走馬マスタ(テーブル名:nvd_ra)
というテーブルに格納されています。
JRA-VANと地方競馬DATAの違い
JRA-VANでは提供されていたが、地方競馬DATAでは提供されていないデータなどがあります。
- レースの開催スケジュール
- 中央競馬のレース開催スケジュールは「jvd_ys」テーブルで提供されています。
- しかし、地方競馬に対応する「nvd_ys」というテーブルは存在しません。
- 地方競馬の開催スケジュールを得るには「レース詳細(nvd_ra)」を集計する必要があります。
- 馬のレースごとの脚質
- DataLabの「馬毎レース情報(jvd_se)」では、レースごとの脚質(逃げ/先行/差し/追込み)をレース後に取得することができましたが、地方競馬DATAには含まれていません
- 中央所属の馬と、地方所属の馬のデータ
- DataLabには地方所属の馬のデータが存在せず、地方競馬DATAには中央所属の馬のデータが存在しない場合があります
- これらの情報を上手いこと解決しておかないと、交流戦などを予想する場合に困る場合があります
その他、テーブル構造はほぼ同一ですが、データの有無が異なる箇所はあると思います。
だいたい、データが取り込めたらJRA-VAN DataLabとデータ内容・形式は共通しているため話すこととしては、以上です。
地方競馬DATAについてのまとめ
- データの形式はJRA-VAN DataLabを踏襲している
- そのため、中央・地方競馬両対応を目指しているのであればDataLabのフォーマットを元に作ると作りやすい
- 地方競馬、中央競馬相互に持ってないデータがあるので補完しあう必要がある
- DataLabでは提供されていても、地方競馬DATAでは提供されていないデータなどあるので注意
JRDB
JRDBは、中央競馬のデータを提供してくれます。地方競馬には対応していません。
JRA-DataLab、と地方競馬DATAがほぼ、同じフォーマットで提供されていたのに対してこのJRDBは少し独特です。
基本的に、下記のようなDataLabが提供しているデータと同じ粒度のデータは提供されているようでした
- レースの詳細
- 馬の詳細
- 馬毎のレースの結果
etc...
一方で、データのフォーマットは独自の形式となっています
どのようなデータが提供されているかについては、下記のページを見てもらったほうが早いと思います
確認していただくと、ほぼDataLabで提供しているようなデータはJRDBでも取得できることが分かると思います。
JRDBのメリット
JRDBの良さは、「主観性が必要になるデータの提供」だと個人的には感じています
JRA-VAN DataLabでは、主に以下のデータを取得できないことに不満がありました
- パドックの状態・評価
- どのコースを使用して調教したか
- 調教時の追い方
- レースで出遅れたかどうか
これの不足していた情報を、JRDBでは取得することができます。
これらは、比較的予想において重要な要素だと感じていましたが、
一方で、おおよその場合「主観」を排除することができない情報です。
そのため、AI予想に採用することは一長一短ではあると思います。
しかし、調教やパドックの情報などは、「前のレースから今回のレースまでの違い」や、「出遅れやすいかどうか」といった強力な情報を
取り込むことができ、できれば取り込みたいものと言えると思います
JRDBのデメリット
データはすべてテキスト形式で配布されます。
SDKなども提供されていないため、パーサやDBに取り込む処理は仕様書を元に自作する必要があります。
まとめると
- スクレイピングをせずにデータを取得するとなると結構お金がかかる
- 中央競馬だけ予想するなら、JRDBのみでデータは大方賄えそう
- 中央競馬と、地方競馬両方予想するなら、DataLabのフォーマットに沿ってデータを取得すると、地方競馬にも対応しやすい
といったところでしょうか。
思ったより長くなったので力尽きてしまいました。
できれば、補足したり、より遂行した内容でまた書こうと思います。
最後に
私が、競馬AIを作り始めて困ったことをずらっと並べたので、わかりづらい内容だったかもしれません。
質問などあれば、Twitterの @masachaco または、コメント欄よりお願いします。