1. 概要
マルチビュー画像からの3D認識のための統合フレームワークであるPETRv2を提案している。PETRv2は、3D物体検出の向上を目指し、過去のフレームの時間情報を活用する効果的な時間モデリングを探求している。具体的には、PETRの3D位置エンベディングを拡張し、異なるフレーム間のオブジェクト位置の時間的な整列を可能にする。また、異なるタスクをサポートするために、PETRv2ではタスク固有のクエリを導入し、シンプルで効果的な解決策を提供する。
2. 新規性
- 位置埋め込み変換の概念的にシンプルな拡張を研究した。3D位置埋め込みによって、時間的なアライメントを実現可能。
- マルチタスク学習をサポートするために、PETRに対して簡単で効果的な解決策を導入した。タスクごとのクエリを導入することで、BEVセグメンテーションと3D車線検出をサポートした。
- 実験結果は、提案されたフレームワークが3Dオブジェクト検出、BEVセグメンテーション、3D車線検出のいずれにおいても最先端の性能を達成していることを示している。また、PETRフレームワークの包括的な評価のための詳細なロバスト性分析も提供されている。
3. 実現方法
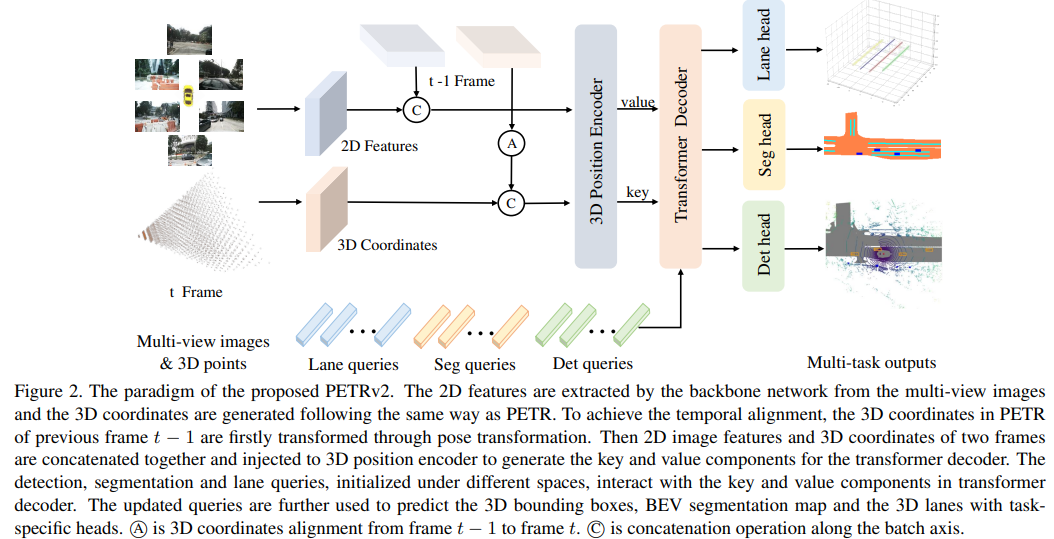
バックボーンネットワークによってマルチビュー画像から2D特徴が抽出され、PETRと同様の方法で3D座標が生成される。時間的な整列を実現するために、直前のフレームt-1のPETRの3D座標はまず姿勢変換を通じて変換される。次に、2つのフレームの2D画像特徴と3D座標を結合して、トランスフォーマーデコーダのキーと値のコンポーネントを生成するための3D位置エンコーダに注入する。検出、セグメンテーション、およびレーンクエリは、異なる空間で初期化され、トランスフォーマーデコーダのキーと値のコンポーネントと相互作用する。更新されたクエリは、タイムステップごとの3Dバウンディングボックス、BEVセグメンテーションマップ、および3Dレーンを予測するために使用される。 ⃝Aはフレームt-1からフレームtへの3D座標の整列を示している。 ⃝Cはバッチ軸に沿った結合操作である。
4. 結果
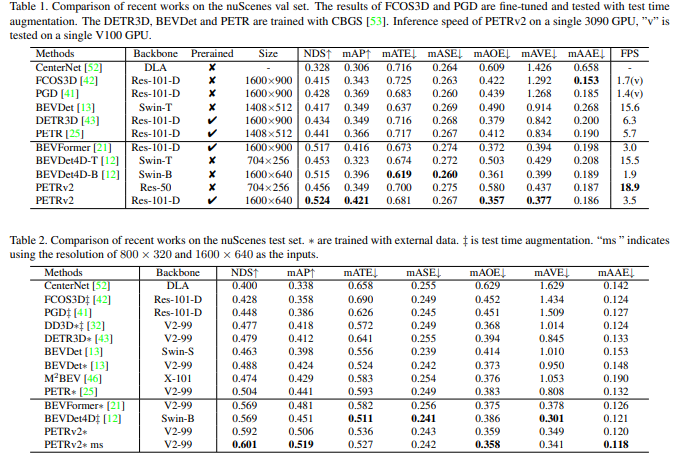
3D物体検出、BEVセグメンテーション、3D車線検出のいずれのタスクでも最先端のパフォーマンスを達成している。さらに、本論文ではPETRフレームワークの頑健性分析も行われている。