ビットキーではこれまでメインのDBとしてFirestoreを使ってきましたが、現在RDBへの移行を進めています。
移行の理由としては、主にビジネス上のドメインが広がり、Firestoreにおける検索性能の弱さがネックになってきたことが挙げられます。
これまで検索性を補完するためにElasticsearchやAlgolia、検索用途のRDBなどを併用してきましたが、メインDBをRDBとすることで基本はサブのDBなしに運用できるようにしていきたいと考えています。
今回はオフィス領域のプロダクトである workhub において移行を進める際に、どのように実装したのかについて紹介します。
方針
今のところ、Pubsub等の非同期は使わずに同期的にRDBへデータを同期しています。
これは書き込み直後の整合性を重視するためです。
移行の単位は基本(一部の仕様整理まで踏み込んだもの以外)はコレクション単位で行っています。
対応するRDB側のテーブルとしては1〜複数テーブルになります。
流れとしては以下のようになります。
- Firestoreへの書き込みをRDBにも書き込む。既存データはマイグレーション。
- Firestoreから参照を剥がしていく
- Firestoreへの書き込みを止めて廃止
構成
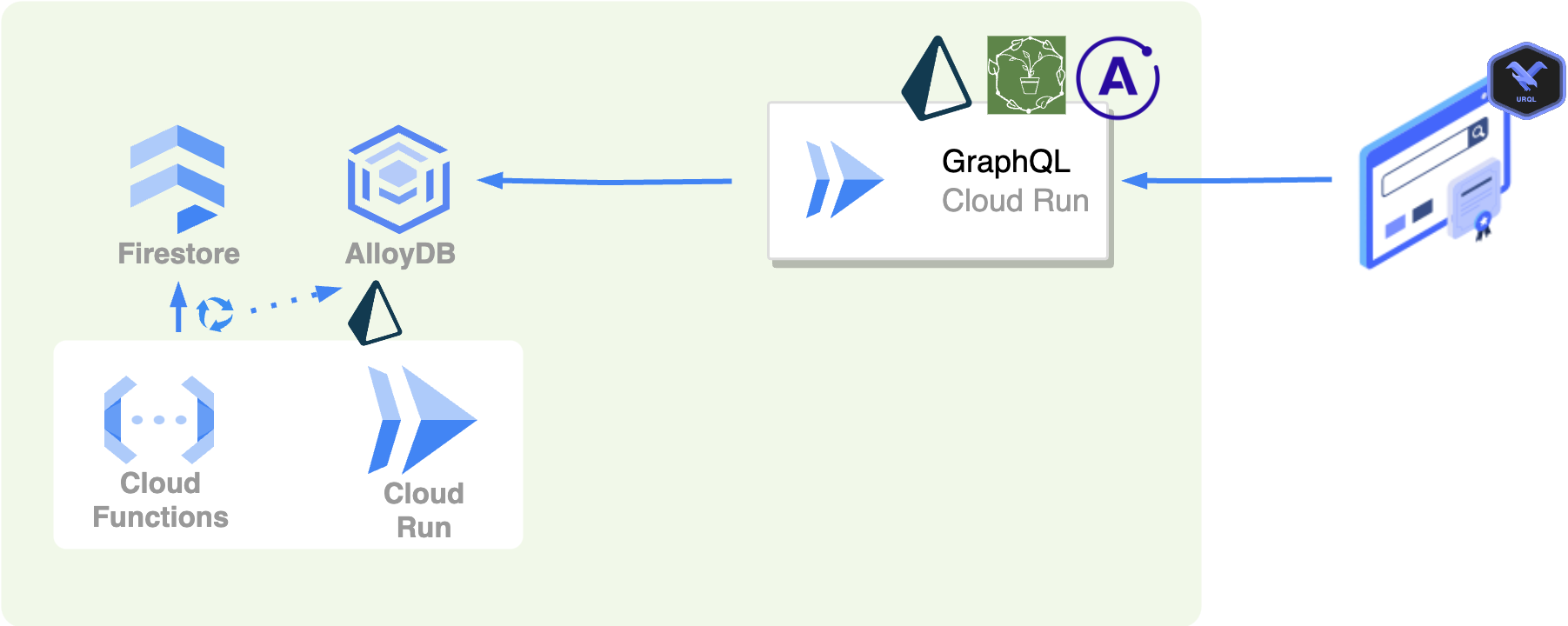
ざっくり上記のような構成です
1. Write
Firestoreへの追加・更新・削除をRDBへ同期する、いわゆるETLにあたる処理を行います。
あまり一般的なソリューションがないようで、Firestoreをサポートしている Google Cloud の Dataflow を検討しましたが、
- 基本はApache Beam SDKでサポートされている Java / Python / Go を使うことになる。その中でも Google Cloud で提供されている実装はJavaが多い。
- FirestoreとRDBで構造が異なるため、それなりに複雑な変換処理を実装する必要がある
- Firestoreを主に扱っているチームでは主にNode.js(TypeScript)を使っている
という点で、Javaを書かないといけないとなるとチーム内でスケールに時間がかかることからDataflowの採用は見送りました。方針で述べた同期のレイテンシーに関する懸念もあります。
他に良い候補も見つからなかったため、自前でETLを行うことにしました。
どのように同期処理を組み込むか
方針で述べたように、同期的なETLを行いたいですが、その場合、あらゆる箇所の更新操作でETLが実行されるようにしなければなりません。
あらゆる箇所に明示的にRDBへの書き込みを追加していくのは面倒であり、漏れも発生しうる状態になってしまいます。
workhubでは元々、Firestoreへの書き込みを社内で用意したオペレーションベースのフレームワークを使って行っていました。
コレクションごとにOpenAPI形式で定義したSpecからジェネレートした型や関数群がありますが、最終的には以下のOperationを構成し、これをFiresbase SDKへ入力することで書き込み処理を行っています。
export type FirestoreOperation = {
path: string;
operation:
| {type: 'overwrite'; data: {id: string} & Record<string, any>}
| {type: 'merge'; data: {id: string} & Record<string, any>}
| {type: 'delete'; id: string};
};
この書き込み処理にETLを挟み、Operationを元にRDBへのETL処理を構成することにより、透過的に同期することにしました。
- Extract: pathを元にフィルタ
- Transform: Prismaの標準インターフェースに対する Input あるいは Raw SQL へ変換
- Load: Prismaで書き込み
を行っています。
ドキュメントすぎるフィールドをどうするか
Firestoreはドキュメント指向のDBであり、ネストや配列などが柔軟にできます。多くはRDBであればサブのテーブルに切り出していく形になりますが、一部でテーブルへのマップが困難な場合があります。
そういった場合にはJson型にしていますが、中身の型は縛りたいです。
その他にもvalidationをしたいユースケースがいろいろあるので社内で以下に近いzodのschema用ジェネレーターを実装しています。
schema.prisma上で
/// @zod.object({
/// ...
/// ...
/// })
complecatedField Json?
としてzod schemaをジェネレートしています。
文字列でしかないので、シンタックスが効かないのがネックです。
2. Read (バックエンド)
Firestoreではブラウザやモバイルアプリから直接クエリすることができる特徴があります。これによりユースケースに応じた柔軟な条件でクエリすることができています。
この体験をそのままに移行できるように、GraphQLを採用することにしました。
PrismaをDBとしたGraphQLサーバーとして公式にいくつかのソリューションがまとめられています。
その中のいくつかを試す中で、一番体験の良かった Pothos を採用しました。
公式のExampleにあるように、Prismaのフィールドをそのまま露出する場合はそれなりに簡単に、GraphQL用に特別にマップしたいときもある程度柔軟に定義することができます。
Prismaのフィールドをほとんどそのままマップするときもいちいちすべてのフィールドを定義しないといけないのは少し煩わしいですが、ちゃんと精査した方が良いのと最近はCopilotのおかげでそういった単純なマップはだいぶ楽になった感があります
// Create an object type based on a prisma model
// without providing any custom type information
builder.prismaObject('User', {
fields: (t) => ({
// expose fields from the database
id: t.exposeID('id'),
email: t.exposeString('email'),
bio: t.string({
// automatically load the bio from the profile
// when this field is queried
select: {
profile: {
select: {
bio: true,
},
},
},
// user will be typed correctly to include the
// selected fields from above
resolve: (user) => user.profile.bio,
}),
// Load posts as list field.
posts: t.relation('posts', {
args: {
oldestFirst: t.arg.boolean(),
},
// Define custom query options that are applied when
// loading the post relation
query: (args, context) => ({
orderBy: {
createdAt: args.oldestFirst ? 'asc' : 'desc',
},
}),
}),
// creates relay connection that handles pagination
// using prisma's built in cursor based pagination
postsConnection: t.relatedConnection('posts', {
cursor: 'id',
}),
}),
});
引用: https://pothos-graphql.dev/docs/plugins/prisma#example
柔軟なクエリパラメータ
Firestoreでは検索条件に in や array-contains などを使うことができますが、GraphQLでも同様のことができるようにクエリパラメータを定義しています。
たとえば id用の検索や
import {builder} from '@/graphql/common/builder';
export const IdInput = builder.inputType('IdInput', {
fields: t => ({
equals: t.field({type: 'String', required: false}),
not: t.field({type: 'String', required: false}),
in: t.field({type: ['String'], required: false}),
notIn: t.field({type: ['String'], required: false}),
}),
});
export type WhereIdInput = {
equals?: string | null | undefined;
not?: string | null | undefined;
in?: string[] | undefined | null;
notIn?: string[] | undefined | null;
};
export const prismaWhereIdNullable = (input: WhereIdInput) => {
return input;
};
export const prismaWhereId = (input: WhereIdInput) => {
return {
equals: input.equals ?? undefined,
not: input.not ?? undefined,
in: input.in ?? undefined,
notIn: input.notIn ?? undefined,
};
};
stringの検索
import {builder} from '@/graphql/common/builder';
export const StringInput = builder.inputType('StringInput', {
fields: t => ({
equals: t.field({type: 'String', required: false}),
not: t.field({type: 'String', required: false}),
// 使う時はindexに要注意
contains: t.field({type: 'String', required: false}),
notContains: t.field({type: 'String', required: false}),
startsWith: t.field({type: 'String', required: false}),
// 使う時はindexに要注意
endsWith: t.field({type: 'String', required: false}),
}),
});
string列の検索
import {builder} from '@/graphql/common/builder';
export const StringListInput = builder.inputType('StringListInput', {
fields: t => ({
equals: t.field({type: ['String'], required: false}),
has: t.field({type: 'String', required: false}),
hasEvery: t.field({type: ['String'], required: false}),
hasSome: t.field({type: ['String'], required: false}),
isEmpty: t.field({type: 'Boolean', required: false}),
}),
});
export type WhereStringListInput = {
equals?: string[] | null | undefined;
has?: string | null | undefined;
hasEvery?: string[] | undefined | null;
hasSome?: string[] | undefined | null;
isEmpty?: boolean | undefined | null;
};
export const prismaWhereStringListNullable = (input: WhereStringListInput) => {
return input;
};
export const prismaWhereStringList = (input: WhereStringListInput) => {
return {
equals: input.equals ?? undefined,
has: input.has ?? undefined,
hasEvery: input.hasEvery ?? undefined,
hasSome: input.hasSome ?? undefined,
isEmpty: input.isEmpty ?? undefined,
};
};
といったInputType用のユーティリティを実装しています。
使用する際には以下のようにします。
args: {
id: t.arg({type: IdInput}),
},
resolve: async (query, args) => {
return prisma.user.findMany({
...query,
where: {
id: args.id ? prismaWhereId(args.id) : undefined,
}
})
}
Prismaにそういった(hasEvery, startsWithのような)ヒューマンリーダブルなインターフェースが提供されているのもあり、InputTypeだけそれに合わせて定義してwhereへ受け渡せば簡単にフィルタすることができてます。
Pothos公式でも似たプラグインが実装され始めていて、現状は 「This package is highly experimental and not recommended for production use」とのことなので安定したら移行を検討したいと考えています。
セキュリティルール
Firestoreではセキュリティルールにより、リソースに対する認可を制御することができます。
match /organizations/{organizationId}/spaces {
allow read, write: if request.auth != null && request.auth.token.organizationId == organizationId
}
PothosではAuth Pluginが提供されており、同様のことが可能です。
たとえば以下のようにモデルに対する認可の制御をすることができます。
export const Space = builder.prismaNode('Space', {
authScopes: (space, context) => {
return !!context.operator && space.organizationId === context.operator.organizationId;
},
// ...
フィールド単位での設定もでき、柔軟に制御することが可能です。
より厳密に管理するためにはPostgreSQLにおいてRLS(Row Level Security)を使うこともできますが、workhubでは今のところ導入していません。
参考として、PrismaからextensionによるRLSにおけるテナントの切り替えのサンプルが提供されています。必要になった際にはこちらを参考に検討したいと思います。
その他
Pothosの前段には Apollo server を使っています。
特別Apollo serverを選定した理由もないので、そのうち必要に応じて GraphQL Yoga 等への移行を検討するかもしれません。
3. Read (フロントエンド)
フロントエンドのGraphQLクライアントには urql を採用しています。
今のところMutationは使っていないので、Apollo clientでもurqlでもさほど変わらないですが、シンプルさでurqlを採用しています。
こちらもそのうち必要に応じてApollo clientへ移行を検討するかもしれません。
TypeScriptへの対応には graphql-codegen の client-preset を使用しています。
GraphQLのスキーマの反映はサーバーへアクセスする形もできますが、素朴にファイル経由にしており、GitHub ActionsでGraphQLサーバー側の変更を検知してフロントエンドのリポジトリへ同期しています。
Pothosでスキーマを出力するには以下のようにします。
import {printSchema, lexicographicSortSchema} from 'graphql';
const schema = builder.toSchema({});
const schemaAsString = printSchema(lexicographicSortSchema(schema));
console.log(schemaAsString);
4. Subscription
Firestoreでは onSnapshot により更新があった場合に通知を得ることができる仕組みがあります。GraphQLにもSubscriptionという仕組みがあり導入を検討していますが、現状はさほど通知が必須な機能がないため導入していません。
ざっくり
Prismaからフック→Cloud Pubsub→Websocket(GraphQLサーバー・クライアントのWebsocketによるSubscription実装)
というイメージをしていますが、
- 別の顧客組織のデータをサブスクライブできてはいけないので認可の仕組みを整える必要
- Prismaからのフックをどうするか考える必要。
$onがdeprecatedになったのでextensionの形で実現するかなど。 - Websocketサーバーをどのように用意するか。Cloud Runでも実現できるが、長時間の接続において安定するか、コストに問題ないか検討が必要。
などの考慮が必要そうだと考えています。
おわりに
RDBと自前ETLとGraphQLを使ってなめらかに移行していけることを目指して構成しました。
その反面、更新処理時のオーバーヘッドや、GraphQLを経由したRDBのクエリ効率への注意など課題はあります。
クエリ効率についてはPrismaがData loaderに近い機構を持っていることでカバーできているところと、AlloyDBのQuery Insightsおよびインデックスのレコメンドの機能でテーブル定義の改善を行っています。
まだ実現できていない足りないパーツがいくつかあるので今後もそれらを埋めながら移行を推進していきます。
11日目の 株式会社ビットキー Advent Calendar 2023 は @0yoyoyo が担当します。お楽しみに!