この記事はリンク情報システムの2021新春アドベントカレンダー Tech Connect!のリレー記事です。
Tech Connect! は勝手に始めるアドベントカレンダーとして、engineer.hanzomon のグループメンバによってリレーされます。
本記事は6日目、1/14(木)分です。
(参考)
↓リンク情報システムのSNSです。よければフォローお願いします。
Facebook
Twitter
1.はじめに
就職しておよそ9年間システム運用現場にいたため、プログラミング関連の知識にまるでついていけていない筆者。
そんなとき、Microsoftがノーコードで画像認識モデルが作れるアプリLobeを公開したと盛り上がっていたのを思い出して触ってみました。
ついでに…GoogleのTeachable Machineも使って個人的な使いやすさの比較もしてみました。
2.利用するデータ
画像認識モデルを作成するのでそれなりの枚数の画像が必要です。
今回はGitHubにて公開されているトルコの学生さんが作ったハンドサインのデータを利用しています。
https://github.com/ardamavi/Sign-Language-Digits-Dataset
上記データの分類からからグーチョキパー(0,2,5)の3種類を抜粋しています。
3.Lobeで画像認識
公式サイトからDL&インストールします。記事公開時点では無料で利用可能。
(手順は割愛)
3-1 Lobeの起動
ショートカットのダブルクリック等で起動すると、デフォルトで新規プロジェクト画面が表示される。
(以下の画面がでたらNewProjectをクリック)
メイン画面

メニューを簡単に説明すると
1. [Label](ラベル):準備した画像のデータセットごとにラベリングする。
2. [Train](トレーニング):学習モデルのトレーニング。
3. [Play](実行):作成した学習モデルをテストする。
3-2 ラベリング
まずは画像を読み込んでラベル付けをしていく。
(各ラベル最低5枚から始められるらしい。)
(詳細手順は割愛)
インポート完了後の画面がこちら!
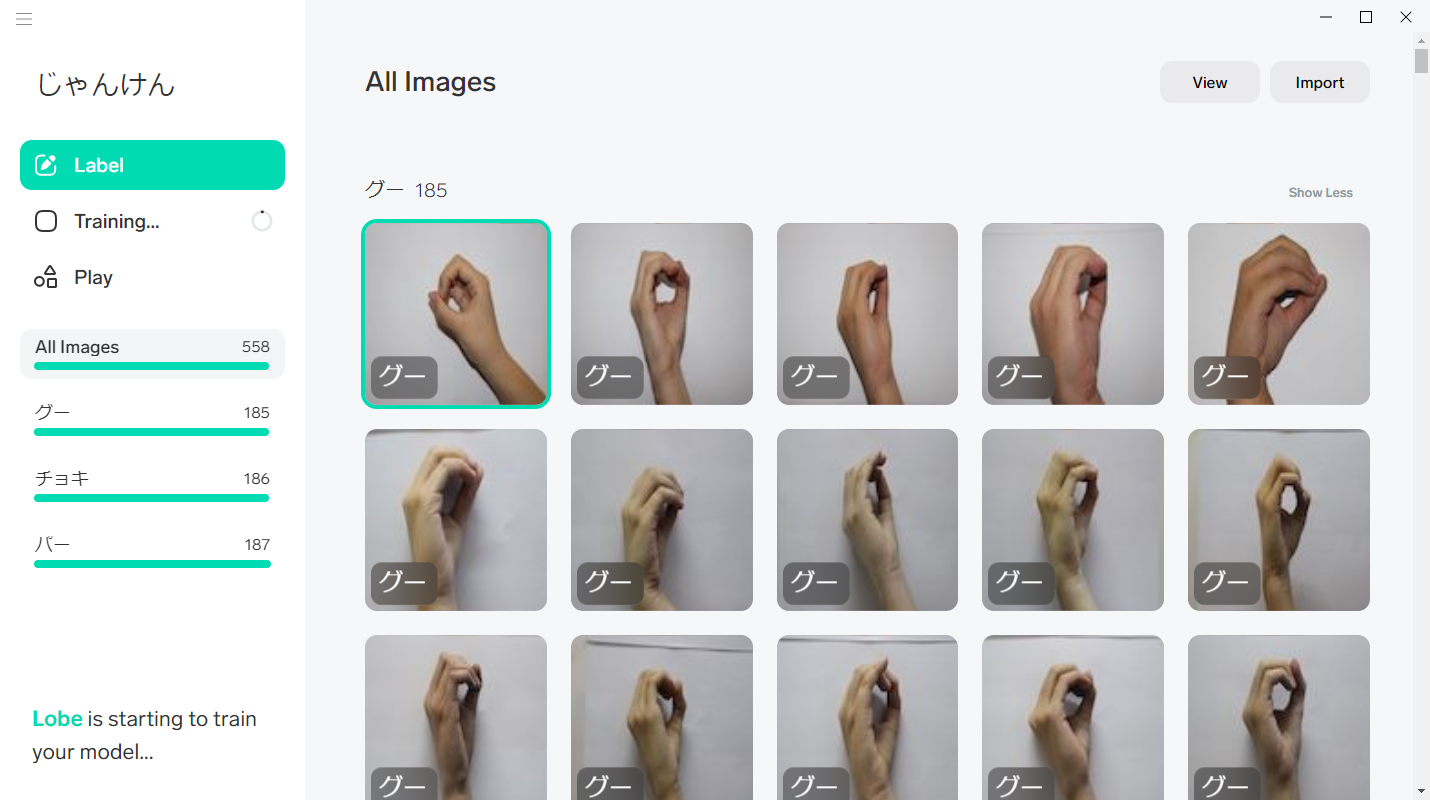
3-3 トレーニング
Lobeではデータをインポート&ラベリングすると自動でトレーニング(学習を行います。)
今回の結果はこれ。
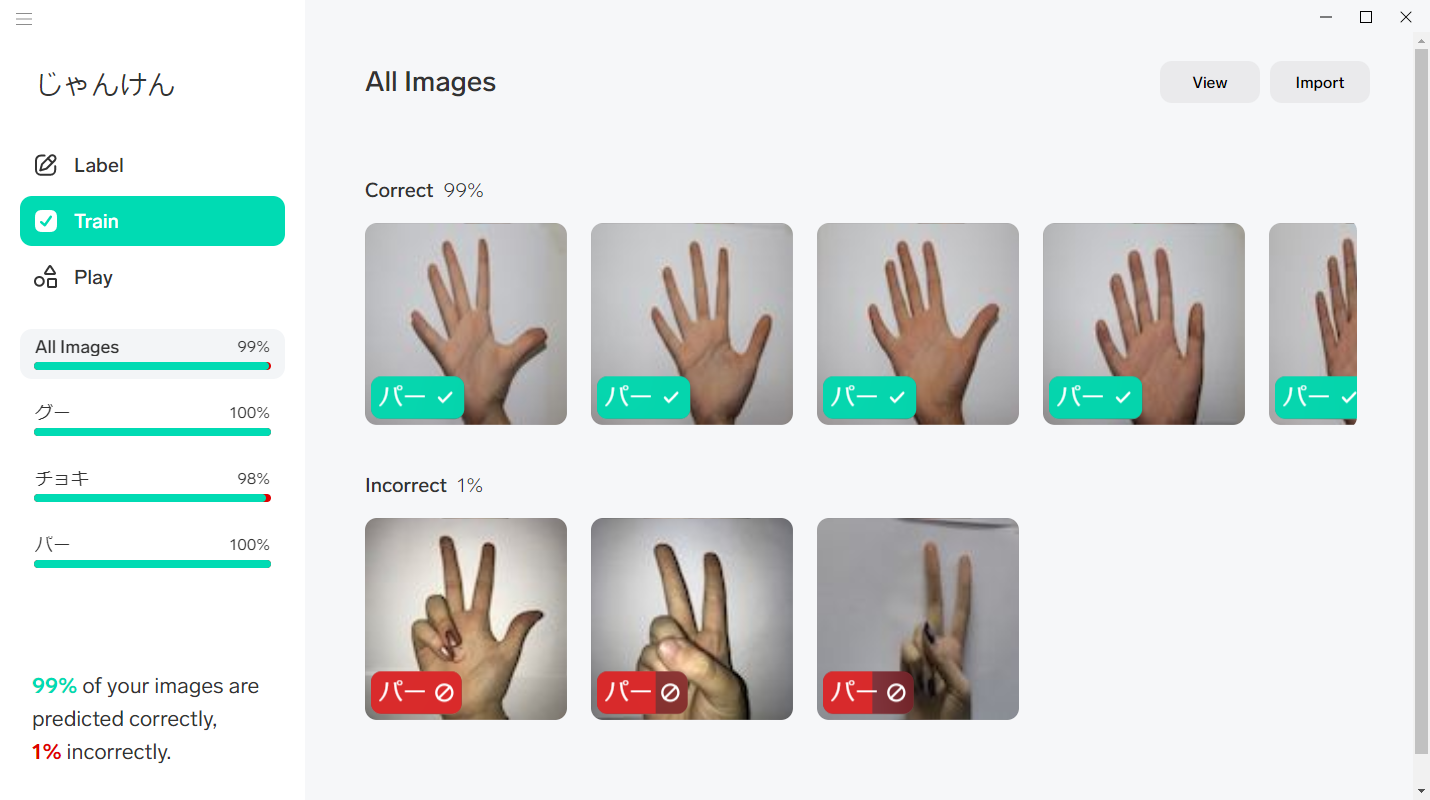
おおよそ各185枚の画像に対して99%の認識率。
認識率が甘いと感じたら…画像を追加する or 再トレーニングが実施することをおすすめします。
※めちゃくちゃ時間がかかります。(今回の450枚の画像で約5~10分。PCスペックにもよるかも)
再トレーニングはメニューからO【ptoimaize Modelをクリック】 → 【Optimize】
(下記参照)
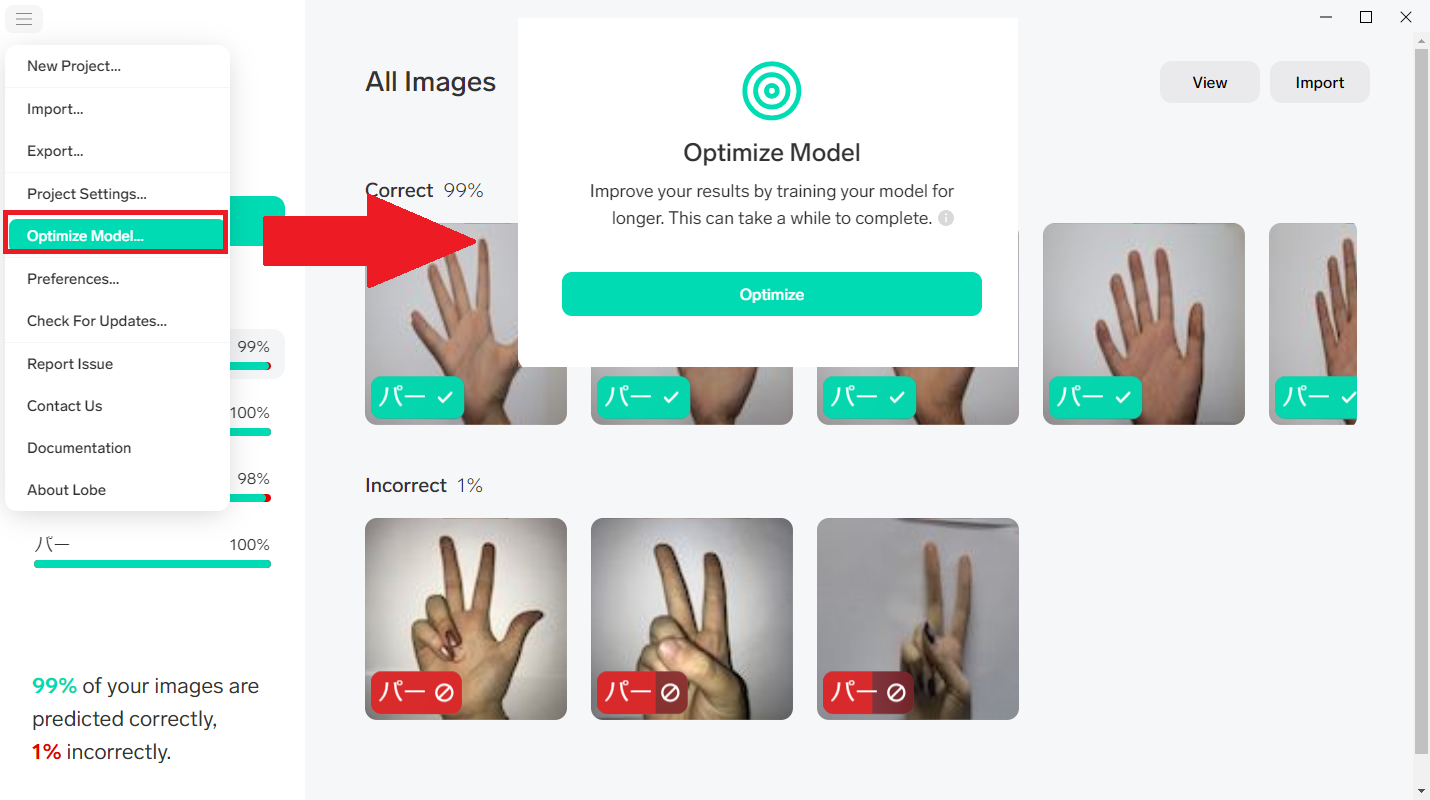
3-4 実行
学習結果に満足がいったら、新しい画像を用意してテスト(推論)します。
左メニューから【Play】を選んで画像をD&Dすることで実行可能。
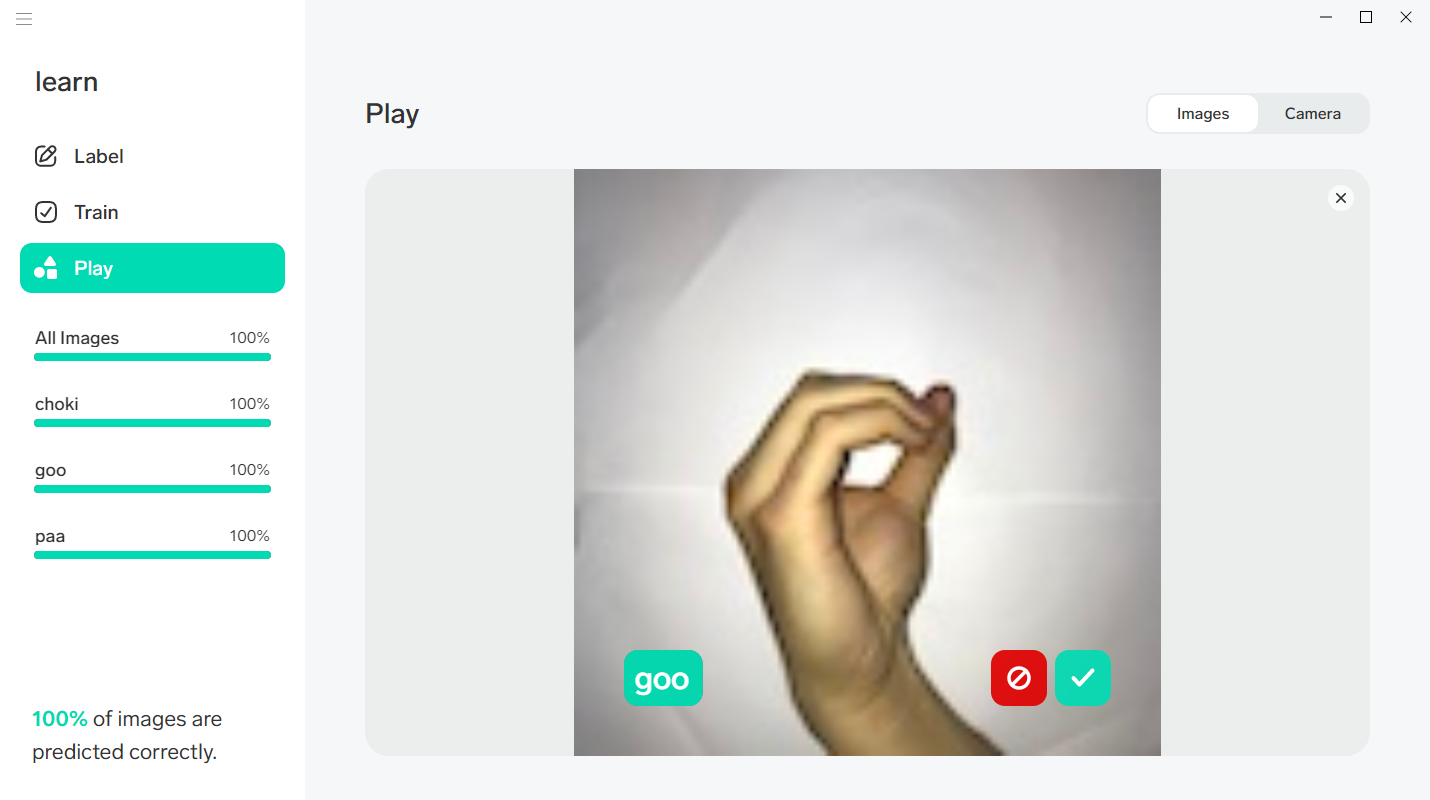
正しい結果なら右側のチェック。誤っているならば正しい結果を選ぶことで再学習させることが可能です。
3-5 エクスポート
ここまでの作業で学習モデルの作成は完了しました。
あとはモデルをエクスポートすることでTensorFlowなどで利用することが可能です!
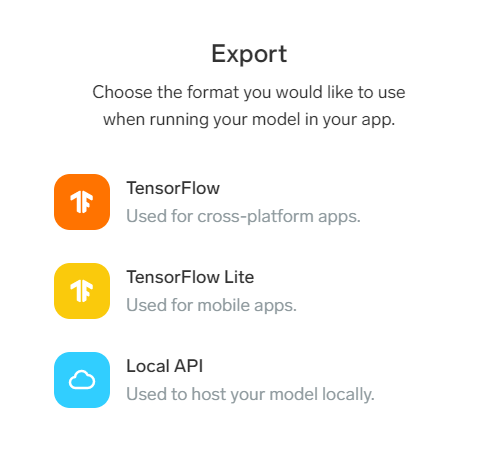
コードいらずでこんな簡単にできてしまうなんて驚き…
4.Teachable Machineで画像認識
GoogleのTeachable Machineでもやってみます。
こちらはLobeとは違いブラウザベース。
Lobeは画像認識Onlyですが、こちらは音声やポーズの認識も可能。
4-1 画像の追加
まずはタイトル名(Lobeで言うところのラベル)を変えます。
【クラスを追加】をクリックすることで分類を増やせます。
タイトルを変更したら画像を追加します。
・ウェブカメラ
・アップロード
のいずれかから選べますが、今回はLobeと比較するために同じデータセットを利用します。
こんな感じ

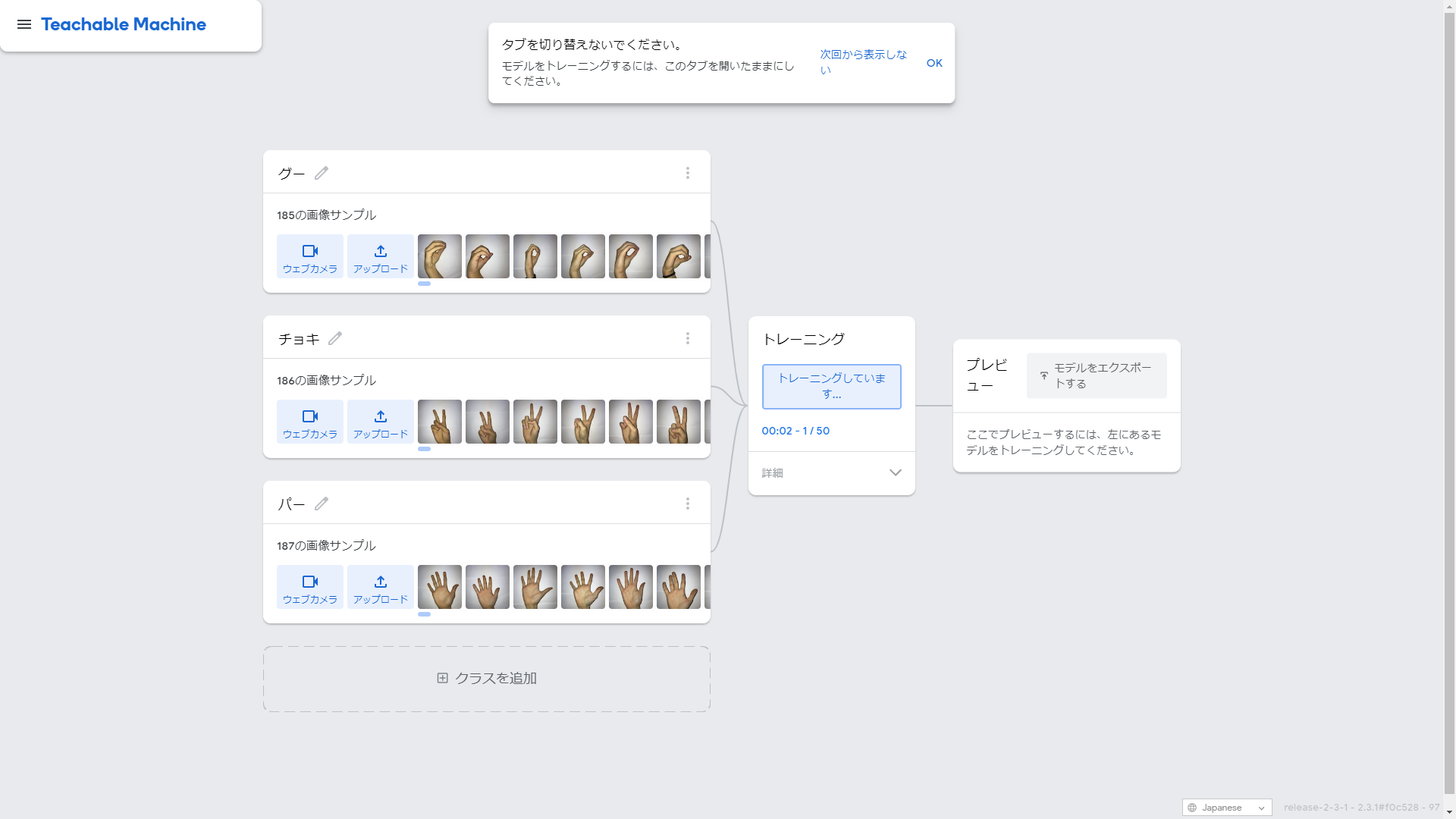
4-2 トレーニング
画像の追加が終わったらトレーニングを実行します。
ちなみに終了するまでタブの切替はNG。
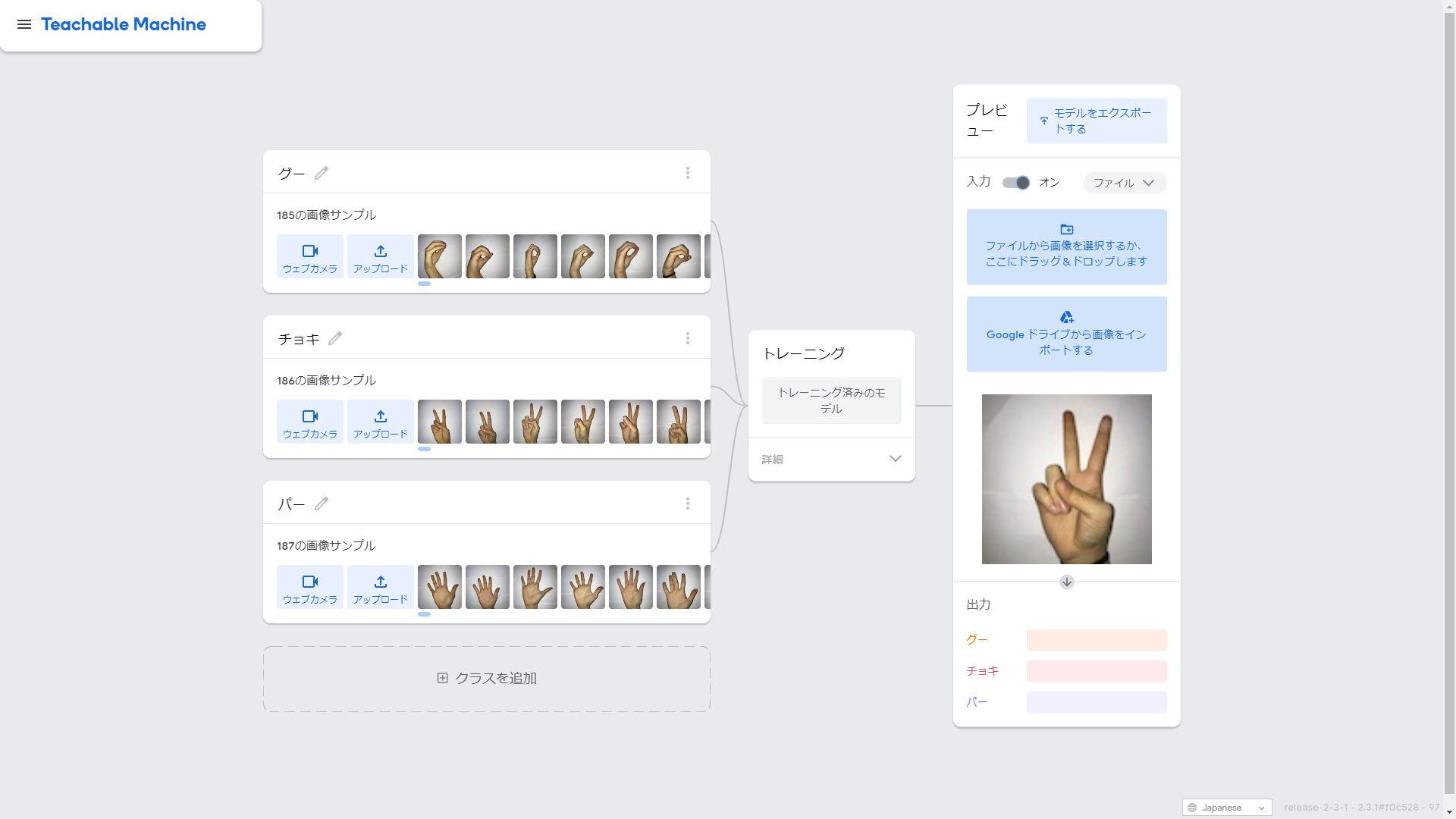
4-3 プレビュー
トレーニングが終了したらプレビュー機能で学習結果の確認が可能です。
画像 or ウェブカメラからの入力で確認が可能です。
4-4 エクスポート
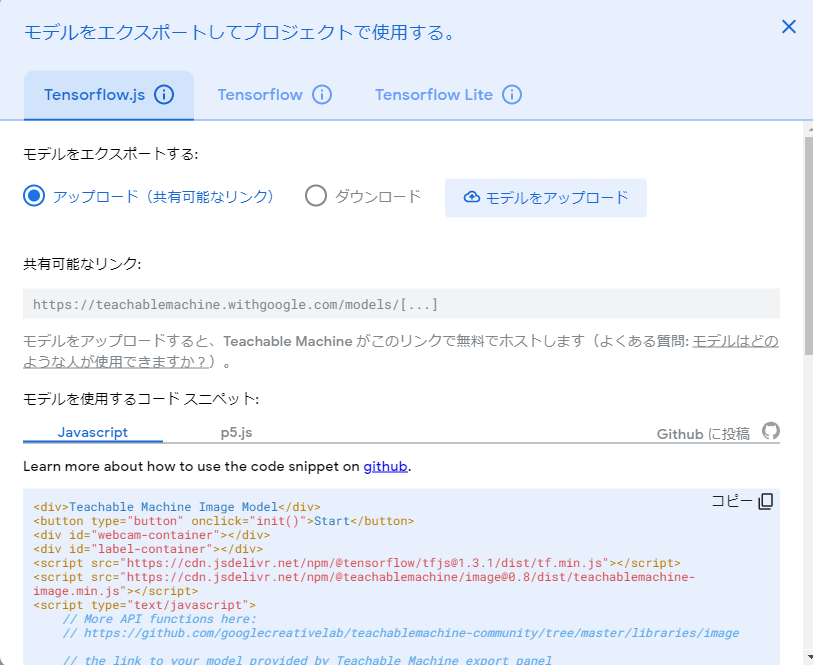
Teachable Machineでもエクスポートが可能です。
(TensorFlow関連のみ。)
5.まとめ
個人的に感じたそれぞれのメリット・デメリットは以下。
Lobe
メリット
・直感的で使いやすい。
・独立したアプリなのでローカルで利用可能 = セキュリティ性が高い
デメリット
・ローカル環境故にPCスペックに左右される面がある(現状GPU処理に対応していないのでCPU処理な点も気になる)
・画像認識でしか使えない(未来に期待)
Teachable Machine
メリット
・クラウドアプリなのでネット環境があれば使える
・画像以外のモデルも作成できる
・認識の精度が細かく調整可能(知識があれば)
・インターフェースが日本語対応
デメリット
・クラウド故の怖さ(情報漏洩はほぼ無いだろうが、機密情報をアップするのはちょっと…って感じる人もいるので)
・デフォルトの設定のままだと認識率はLobeに軍配が上がる(知識なしの人間がやった場合に関わる)
6.感想
大した知識の無い筆者でも簡単に機械学習モデルが作成できる時代になっていたことに驚き。
(知らなかったのですが、Teachable Machineは2017年頃から存在したらしい…Googleさんすご……)
どちらも機械学習の入口としてはいいツールだと感じました。
使える人が増えればデータサイエンティストがマストじゃなくなるかも?(素人が適当に作った結果、製品化しようとした際には逆に仕事が増えそうな気もする)
もっとプログラミング力が向上したらLobeから作成した学習モデルでなにか作ってみたいと思います。