Jingwen Wang, Wenhao Jiang, Lin Ma, Wei Liu, Yong Xu
CVPR 2018
arXiv, pdf
1. どんなものか?
密なビデオキャプショニング(Dense video captioning)を行う.
Dense video captioningとは?
ビデオ内のすべてのイベントのローカライズと,その各イベントについて自然言語で説明文の生成を行うこと.
2. 先行研究と何が違うのか?
- 過去と将来のコンテキストを考慮してキャプションを生成する.
- 従来のものでは同じイベントと見なされたほぼ同じ時間に終了する異なるイベントが区別できる.
- 周囲のイベントの情報を動的に選択して現在のイベントのキャプションを生成する.
3. 技術や手法のキモは何か?
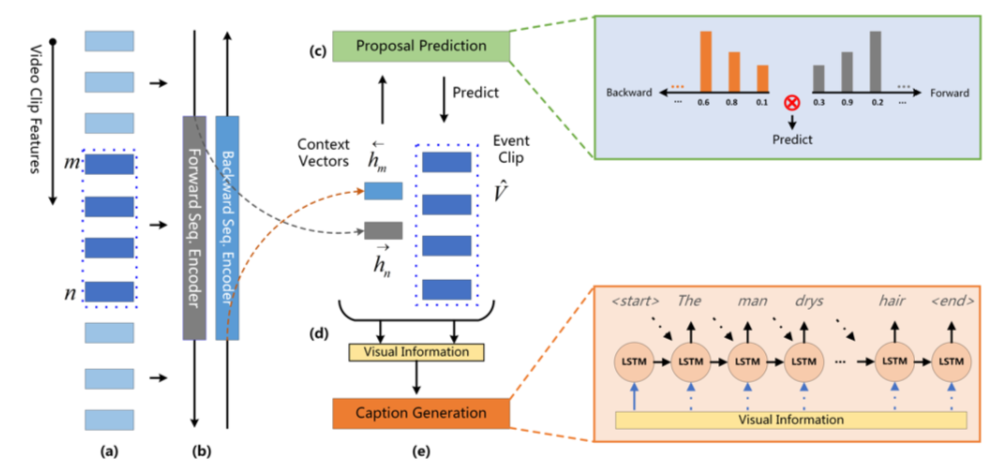
提案されたネッチワークはプロポーザルモジュールとキャプションモジュールによって構成されている.
双方向SST(Single-Stream Temporal Action Proposals)
SSTでは過去のコンテキストと現在のイベント情報のみを符号化して推論を行う.双方向のSSTにすることにより,将来のイベントの情報を汲み取ることができるようになる.つまり,順方向のパスが過去のコンテキストと現在のイベント情報をエンコードし,逆方向のパスが将来のコンテキストと現在のイベント情報をエンコードする.
Dynamic Attentive Fusion with Context Gating
過去と未来の両方のコンテキストを補足した順方向および逆方向パスからのプロポーザル状態と,検出されたプロポーザルの符号化された視覚的特徴を融合させる.
$$ F_t(s_i) = f(h_n^{\rightarrow}, h_m^{\leftarrow},
\hat{V}={v_i}^n_{i=m}, H_{t-1}) $$
Temporal Dynamic Attention
ビジュアル特徴$\hat{V}$を以下の式でアテンションする.
$$ z_i^t = W_a^T \cdot tanh(W_v v_{i+m-1} + W_h[h_n^{\rightarrow},h_m^{\leftarrow}]+W_HH_{t-1}+b) $$
ここで,$H_{t-1}$はタイムステップ$t-1$でのデコーダの隠れ状態,$[\cdot,\cdot]$はベクトル連結を表す.
\alpha_i^t = \exp (z_i^t)/\sum_{k=1}^{p}\exp (z_k^t) \\
\tilde{v}^t = \sum_{i=1}^p \alpha_i^t \cdot v_{i+m-1} \\
F(s_i) = [\tilde{v}^t,h^{\rightarrow}_n,h^
{\leftarrow}_m]
Context Gating
アテンションされたビジュアル特徴$\tilde{v}^t$をコンテキストベクトル$h_n^{\rightarrow}, h_m^{\leftarrow}$と直接連結させるのではなく,それらをバランスよく取り込むための「コンテキストゲート(context gete)」を学習させる.
\dot{v}^t = \tanh (\tilde{W}\tilde{v}^t) \\
h = \tanh (W_{ctx}[\tilde{v}^t,h^{\rightarrow}_n,h^
{\leftarrow}_m]) \\
g_{ctx} = \sigma(W_g[\dot{v}^t,h,E_t,H_{t-1}]) \\
F(s_i) = [(1-g_{ctx})\odot \dot{v}^t, g_{ctx} \odot h]
Inference by Joint Ranking
プロポーザルモジュールによって提案されたイベントに対して提案スコアを定義し,キャプションモジュールによって生成された各提案に対してのキャプションに信頼スコアを定義する.これらをランキングすることでよりよい結果を得る.
損失関数
Proposal Loss
\mathcal{L}_p(c,t,X,y) = - \sum_{j=1}^{K} w_o^jy_t^j \log c_t^j + w_1^j(1-y_t^j) \log (1-c_t^j)
Captioning Loss
\mathcal{L}_c(P) = -\sum_{i=1}^{M}\log (p(w_i))
Total Loss
\mathcal{L} = \lambda \times \mathcal{L}_p + \mathcal{L}_c
4. どうやって有効性を検証したか?
ActivityNet v1.3のデータセットで検証する.このデータセットには20k個のトリムされていないYouTubeの動画が含まれている.1つの動画のサイズは120秒くらいで,3つ以上のアノテーション付きのイベントが存在する.
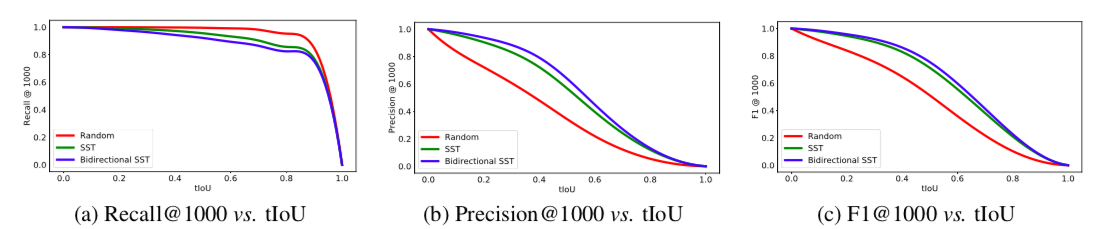
Event Localization
まず,以下の3つの手法でイベントローカライゼーションについて比較する.
- Random
- SST
- Bidirectional SST(提案手法)
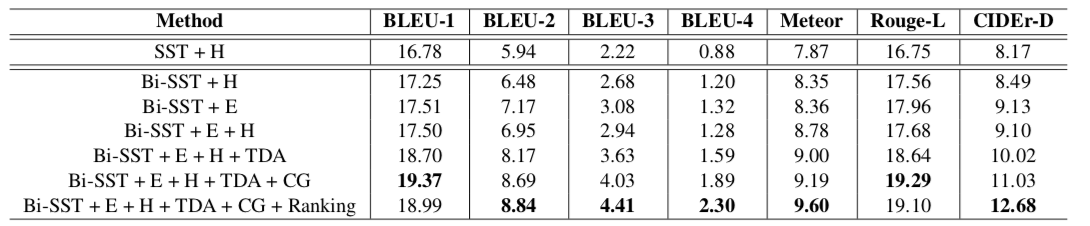
Dense Event Captioning
キャプション生成能力を評価する.
'H'はコンテキストベクトル,'E'はイベントクリップ特徴,'TDA'はtemporal dynamic attention fusion,'CG'はコンテキストゲートを表す.
- SST + H
- Bi-SST + E
- Bi-SST + E + H
- Bi-SST + E + H + TDA
- Bi-SST + E + H + TDA + CG
- Bi-SST + E + H + TDA + CG + Ranking
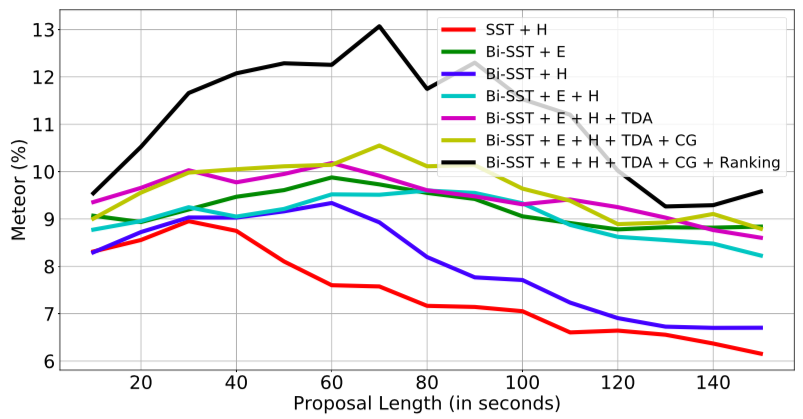
従来手法との比較

[20]Dense-Captioning Events in Videos
プロポーザルの長さによるMeteorスコアの変化
評価指標について
5. 議論はあるか
長いイベントになるとそれらのキャプション生成は困難になる.これはLSTMの長期依存性の学習の難しさが起因している.