Yangyu Chen, Shuhui Wang, Weigang Zhang, Qingming Huang, "Less Is More: Picking Informative Frames for Video Captioning", in ECCV 2018, 2018, arXiv:1803.01457
1. どんなものか?
ビデオキャプションにおいて有益なフレームをピックアップする__PickNet__を提案する.
標準的なEncoder-Decoderフレームワークに基づいて強化学習ベースの手法を行う.
各フレームのピッキングアクションの報酬を,視覚的多様性を最大化し,テキストの差を最小化するように決定される.
2. 先行研究との違いは何か?
先行研究におけるビデオキャプションのタスクでは,ビデオを等間隔にフレームサンプリングする方法が一般的である.しかしながら,本論文の提案手法は,__PickNet__と呼ぶ強化学習モデルを用いて,少ないフレーム数で効果的なキャプションを行う.
3. 技術や手法のキモはなにか?
本論文の提案モデルは2つのパートによって構成される.
- Encoder-Decoderベースのセンテンス生成器
- PickNet
Encoder-Decoder
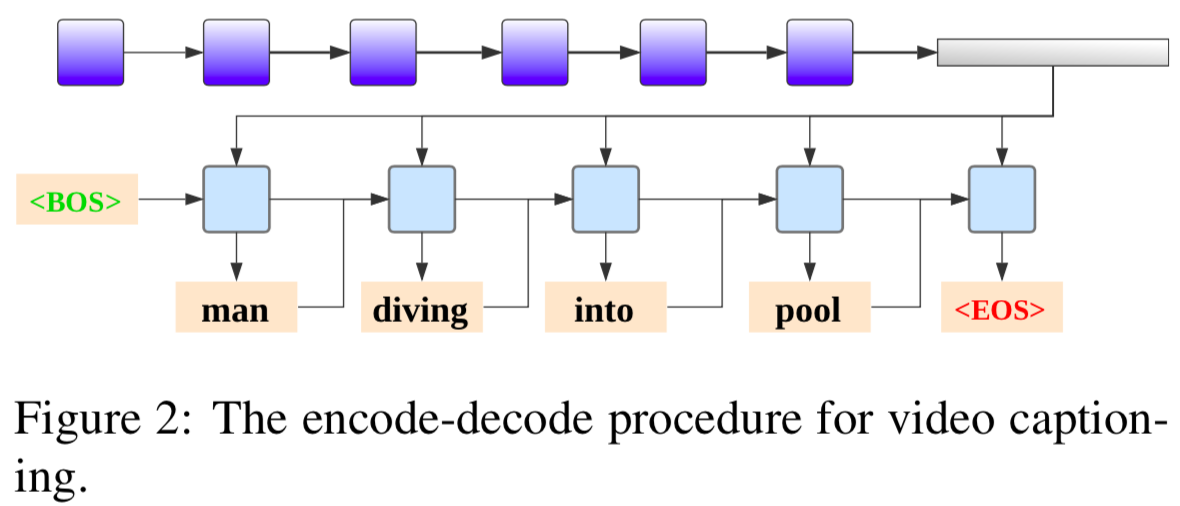
PickNet
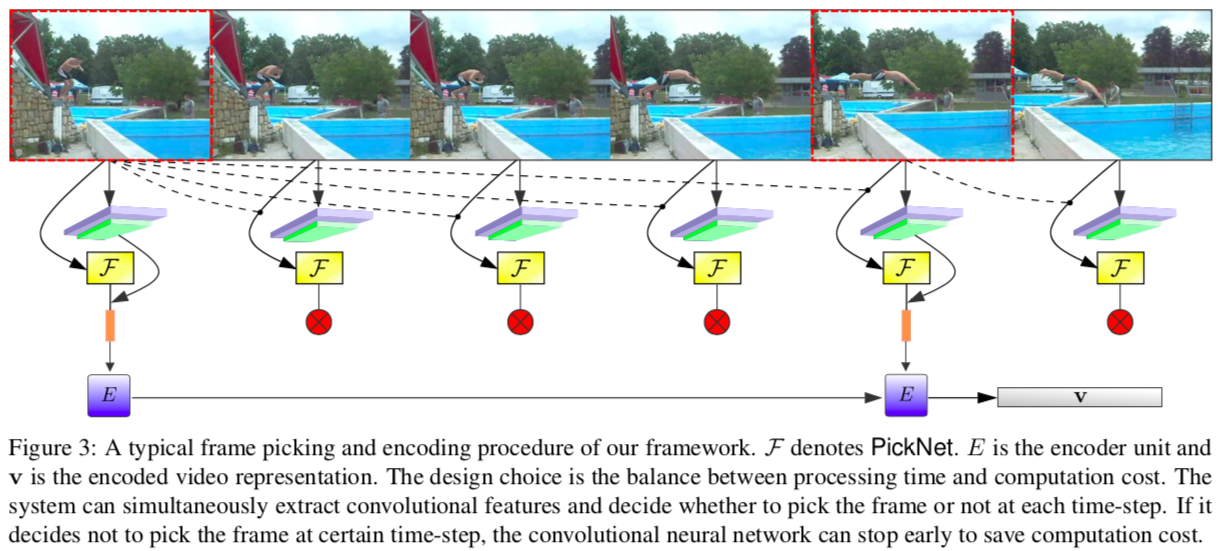
__PickNet__はすべてのフレーム情報を知ることなく,現在のフレームと過去のフレームの履歴のみを考慮してフレーム選択を行う.
ビデオから抽出されたフレーム画像シーケンスが与えられた場合に,エージェントはビデオコンテンツを可能な限り保持するために,特定のポリシーにしたがってそのビデオのサブセットを選択するという強化学習タスクとして考える.
まず,__PickNet__のプロトタイプとして単縦な2層のフィードフォワードニューラルネットを使用する.
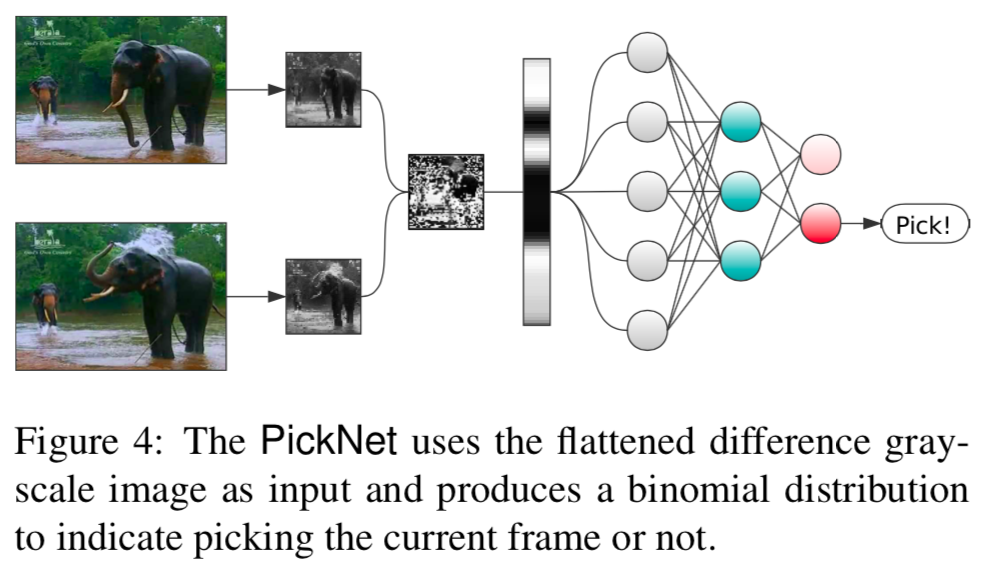
ネットワークには現在注目しているフレームを選択または削除する確率を示す2つの出力がある.
最初に,各入力フレーム$z_t$を最初にグレースケール画像に変換し,小さくリサイズした画像$g_t$を得る.
次に,最後に選択されたフレームのリサイズ画像$\tilde{g}$と現在のフレームの$g_t$との差分画像$d_t$を平坦化したベクトルを得る.
このベルトルを__PickNet__に入力する.
s_t = W_2 \cdot (\max (W_1 \cdot vec(d_t)+ b_1, 0)) + b_2 \\
p_{\theta}(a_t|z_t, \tilde{g}) \sim \text{softmax} (s_t)
トレーニング中は確率的方針を用いてアクションが上式で選択される.
現在のフレームが選択されると予めトレーニングされたCNNによってフレーム特徴が抽出され,Encoderに渡される.
また,
\tilde{g} \leftarrow g_t
となる.
Rewards
有益なビデオフレームを選択するために,__言語の報酬(Language reward)__と__視覚的な多様性の報酬(Visual diversity reward)__の2つの報酬を考慮する.
Language reward
生成された文章の評価スコアを報酬として使用する.評価にはCIDErを用いる.
ビデオ$v_i$と人間が生成した参照文$S_i={s_{ij}}$とモデルが出力した文章を$c_i$とすると,次のように言語報酬$r_l$が書ける.
r_l(v_i,S_i) = CIDEr(c_i,S_i)
Visual diversity reward
言語報酬のみを使用すると,重要な視覚情報が失われる可能性があるため,視覚的多様性報酬$r_v$を導入する.
全ての選択された特徴ベクトル{$x_i \in \mathbb{R}^D$}に対して,視覚的多様性報酬として特徴ベクトルの標準偏差を使用する.
r_v (v_i) = \sum_{j=1}^{D} \sqrt{\frac{1}{N_p}\sum_{i=1}^{N_p}(x_i^{(j)}-\mu^{(j)})^2}
$N_p$:選択されたフレームの総数
$x_i^{(j)}$:$i$番目のビジュアル特徴の$j$番目の値
total reward
r(v_i) = \begin{cases}\lambda_vr_v(v_i)\qquad \text{if} \quad N_{min} \le N_p \le N_{max}
\\ R^- \qquad \text{otherwise}\end{cases}
Training
トレーニング手順は3つの段階に分割される.
第1段階はエンコーダ・デコーダの事前トレーニングで,_supervision stage_と呼ぶ.
第2段階は強化学習によってPickNetをトレーニングすることで,_reinforcement stage_と呼ぶ.
第3段階はエンコーダ・デコーダの共同トレーニングで,_adaptation stage_と呼ぶ.
エンコーダ・デコーダをトレーニングするために標準的なバックプロパゲーションを使用し,PickNetをトレーニングするためにREINFORCEを用いる.
supervision stage
\mathcal{L}_X(\omega) = -\sum_{t=1}^m \log(p_\omega(y_t|y_{t-1},y_{t-2},\cdots,v))
reinforcement stage
下式を最小化するのが目的である.
\mathcal{L}_R(\theta) = - \mathbb{E}_{a^s \sim p_\theta}[r(a^s)]
ここで,$a_s=(a_1^s,\dots, a_n^s)$で,$a_t^s$は時間ステップ$t$で学習された方針からサンプリングされた行動である.
勾配は次式のように計算する.
\Delta_\theta\mathcal{L}_R(\theta) = \mathbb{E}_{a^s \sim p_\theta}[r(a^s)\Delta_\theta\log p_\theta(a^s)]
チェインルールを用いて次のように計算できる.
\Delta_\theta\mathcal{L}_R(\theta) = \sum_{t=1}^n \frac{\partial\mathcal{L}_R(\theta)}{\partial s_t}\frac{\partial \theta}{\partial s_t} \\
= \sum_{t=1}^n \mathbb{E}_{a^s \sim p_\theta}r(a^s)(p_\theta(a_t^s)-1_{a_t^s})\frac{\partial s_t}{\partial \theta}
ここで,$s_t$はソフトマックス関数の入力である.
実際には勾配は,$p_\theta$から単一のモンテカルロサンプルから求めることができる.
\Delta_\theta\mathcal{L}_R(\theta) \approx -\sum_{t=1}^{n} r(a^s)(p_\theta(a_t^s)-1_{a_t^s})\frac{\partial s_t}{\partial \theta}
adaptation stage
エンコーダ・デコーダと__PickNet__は事前にトレーニングされているが,エンコーダ・デコーダは入力としてビデオのすべてのフレームを受け取って学習しているので,そのギャップを埋めるために共同にトレーニングさせる.
4. どのように有効性を検証したか?
MSVDデータセットとMSR-VTTデータセットを用いて検証する.
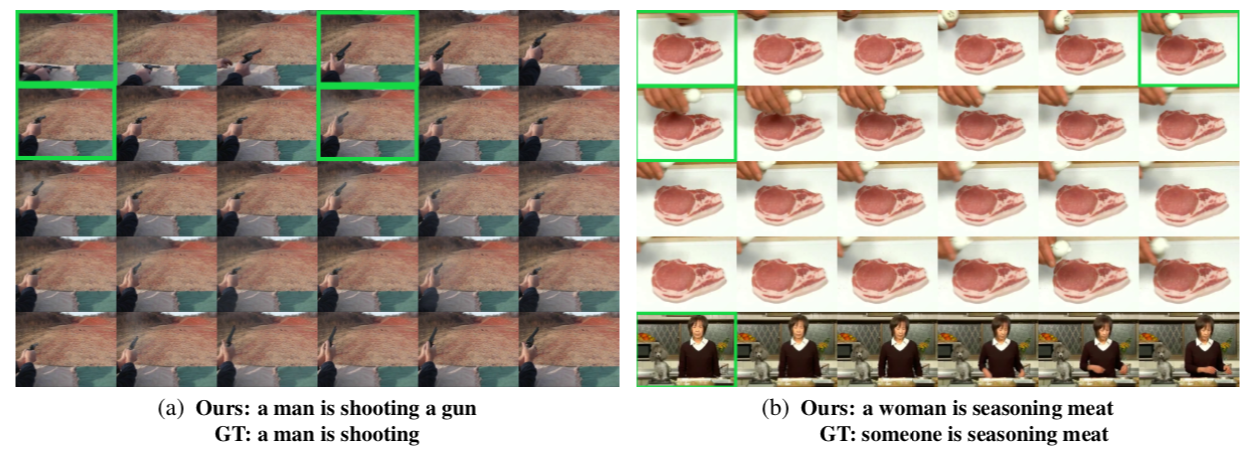
- PickNetの動作例

- MSVDデータセットでの従来手法との比較
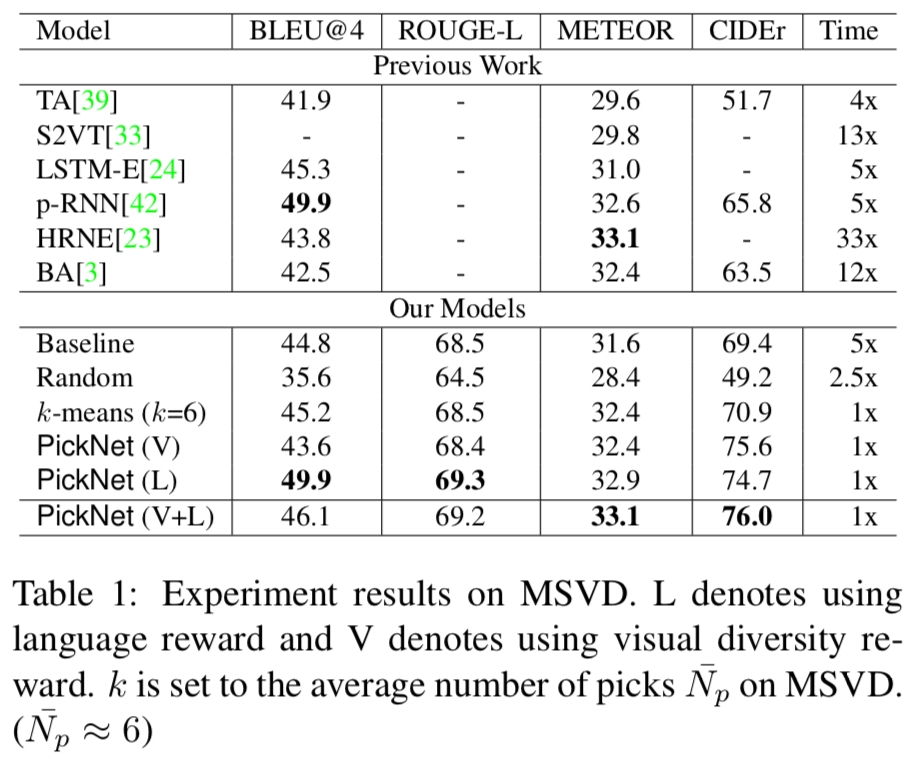
実行時間は,フレーム数と視覚的特徴抽出器から算定している.
すべての評価指標で高いスコアが出ており,実行時間も短い.
- MSR-VTTデータセットでの従来手法との比較
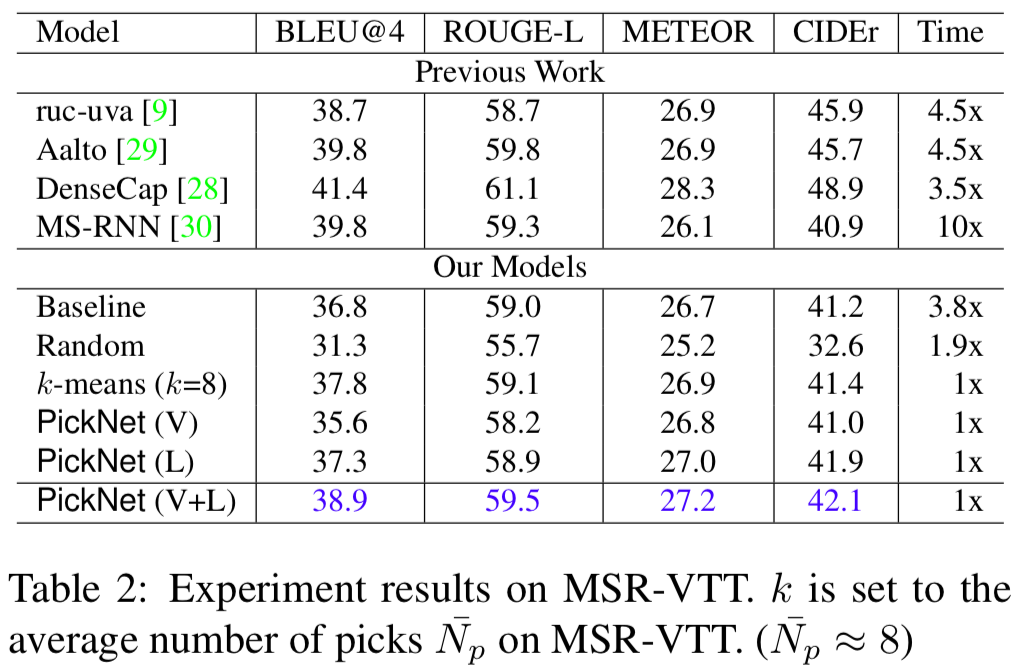
上と同様の結果が出ている.
- __PickNet__の分析
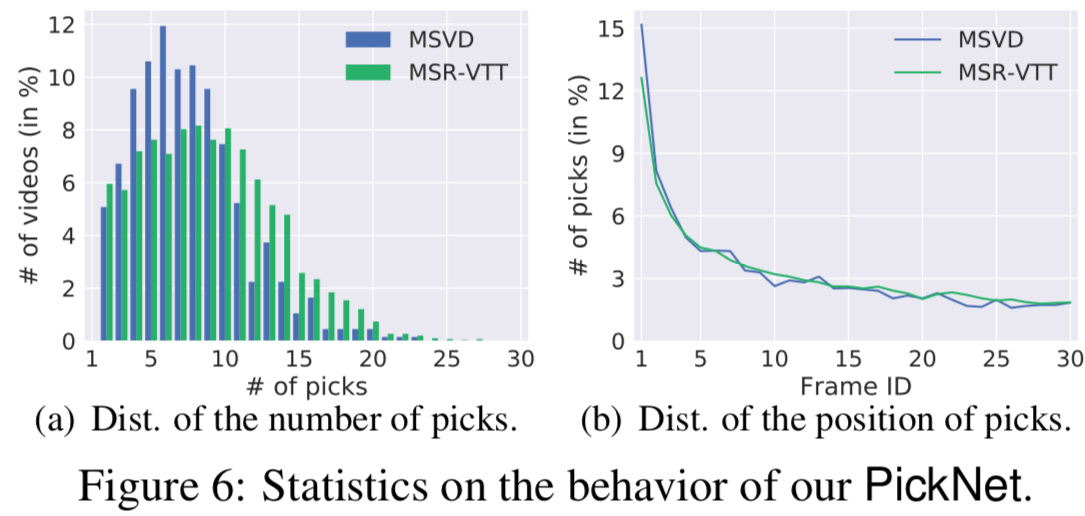
ほとんどのビデオで,10未満の数のフレームが選択されている.これはキャプションにおいてビデオ中の33パーセントくらいの数があれば十分であることが示されている.
また,右の図をみると,ビデオの時間経過とともにフレームを選ぶ確率が減少していることがわかる.ほとんどのビデオはシングルショットであり、前方のフレームはビデオ全体を表現するのに十分であることが示されている.
- 提案モデルの生成例