Bairui Wang, Lin Ma, Wei Zhang, Wei Liu, "Reconstruction Network for Video Captioning", in CVPR2018, pp.7622-7631, 2018. arXiv1803.11438
1. どんなものか?
ビデオに対して自然言語でキャプションを生成する.
従来のビデオコンテンツのてがかりを利用して言語記述を行う方法と異なり,本論文ではフォワード(ビデオから文章),バックワード(文章からビデオ)の両方を利用した新しいエンコーダ・デコーダ・リコンストラクタアーキテクチャを備えたリコンストラクションネットワーク(RecNet)を提案する.
2. 先行研究との違いは何か?
- 順方向(ビデオ→文章)と逆方向(文章→ビデオ)の二重学習を行うこと
- 下の図のエンコーダ・デコーダ・リコンストラクタアーキテクチャを使用すること
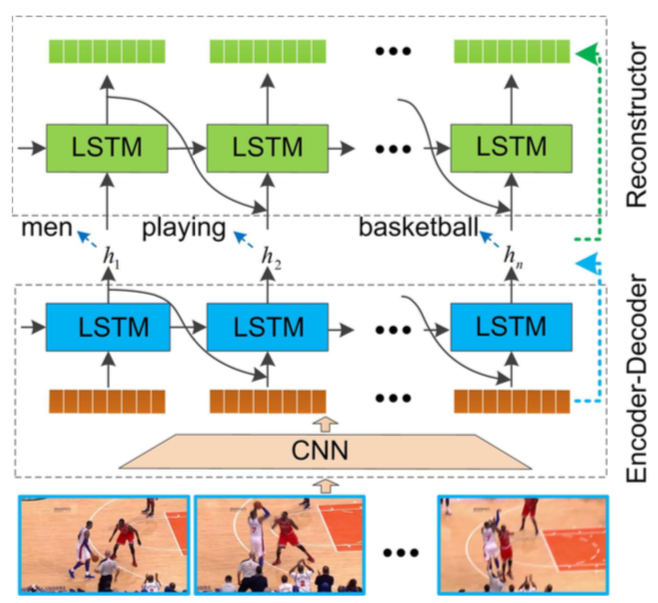
3. 技術や手法のキモは何か?
Encoder-Decoder-Reconstructor Architecture
エンコーダ・デコーダは,各ビデオフレームの特徴表現を生成し,続いて文章を生成する.
リコンストラクタは,デコーダの隠れ状態シーケンスに基づいて元のビデオ特徴シーケンスを再現する.
リコンストラクタの存在により,エンコーダおよびデコーダが元のビデオに関する意味情報をより多く埋め込むように促される.
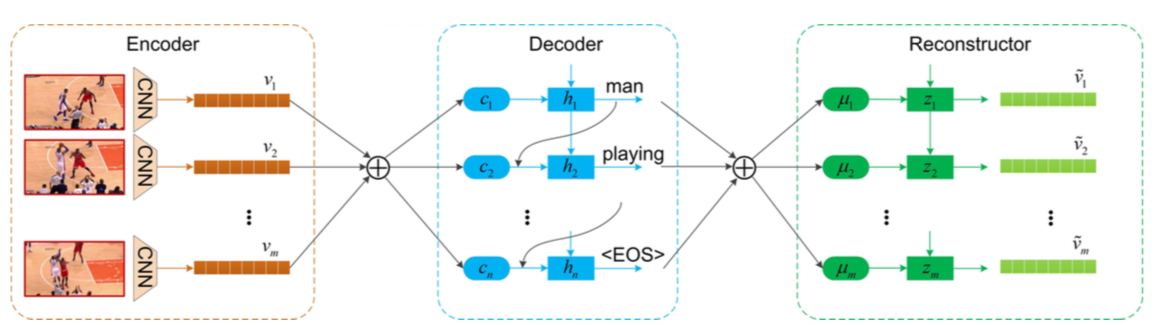
Encoder-Decoder
提案手法のエンコーダ・デコーダアーキテクチャはSequence to sequence - video to text(Venugopalan+, ICCV 2015)のものを使用する.
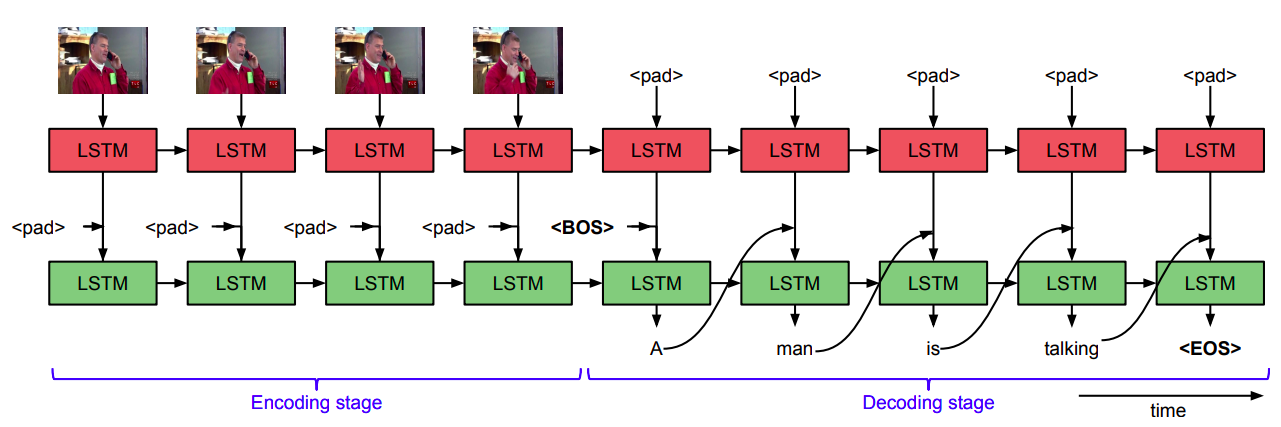
エンコーダは,各ビデオフレームを意味情報をキャプチャするためにInception-V4を使用してビデオ特徴を得る.
デコーダは,ビデオ特徴に基づいて1ワードずつ生成する.ビデオのグローバルな時間的情報をさらに利用するために,時間的アテンション機構を用いて,デコーダがキャプション生成に必要なキーフレームを選択するように促す.
Reconstructor
リコンストラクタの目的は,デコーダの隠れ状態シーケンスからエンコーダによって生成されたビデオ表現を再現することである.2種類のアーキテクチャがカスタマイズされる.
一方は,ビデオのグローバル構造を再現することに焦点を当てたものと,もう一方は,隠れ状態シーケンスを選択的に採択することによりビデオのローカル構造を再現するものである.
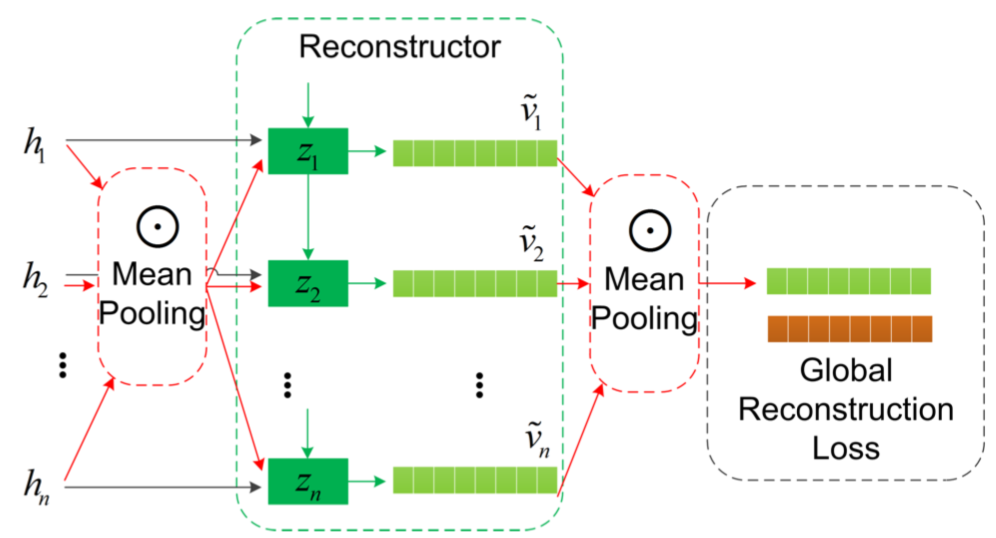
Reconstructing Global Structure
デコーダの隠れ状態($h_t$)に加えて,隠れ状態が平均プーリングを経て得られた文章のグローバル表現($\phi(H)$)が入力となる.
\phi(H) = \frac{1}{n}\sum_{i=1}^{n}h_i \\
\left(\begin{matrix}
i_t \\
f_t \\
o_t \\
g_t
\end{matrix}\right) =
\left(\begin{matrix}
\sigma \\
\sigma \\
\sigma \\
\tanh
\end{matrix}\right)T
\left(\begin{matrix}
h_t \\
z_{t-1} \\
\phi(H)
\end{matrix}\right) \\
m_t = f_t \odot m_{t-1} + i_t \odot g_t \\
z_t = o_t \odot \tanh (m_t)
ここで$i_t, f_t, m_t, o_t, z_t$は各LSTMユニットの入力,foget, memory, 出力, 隠れ状態である.
グローバル表現を再現するための損失は以下のようになる.
$$
\mathcal{L}_{rec}^g = \psi(\phi(V), \phi(Z))
$$
$\phi(V)$は元のビデオ特徴の平均プーリング,$\phi(Z)$はリココンストラクタの隠れ状態の平均プーリングである.$\psi(\cdot)$はユークリッド距離を計算する.
Reconstructing Local Structure
このリコンストラクタは上述のものとは異なり,各ビデオフレームを再構成することによって,時間ダイナミックスを学習することを目的とする.アテンション機構によって選択されたデコーダのキー隠れ状態から各フレームの特徴表現を再現する.
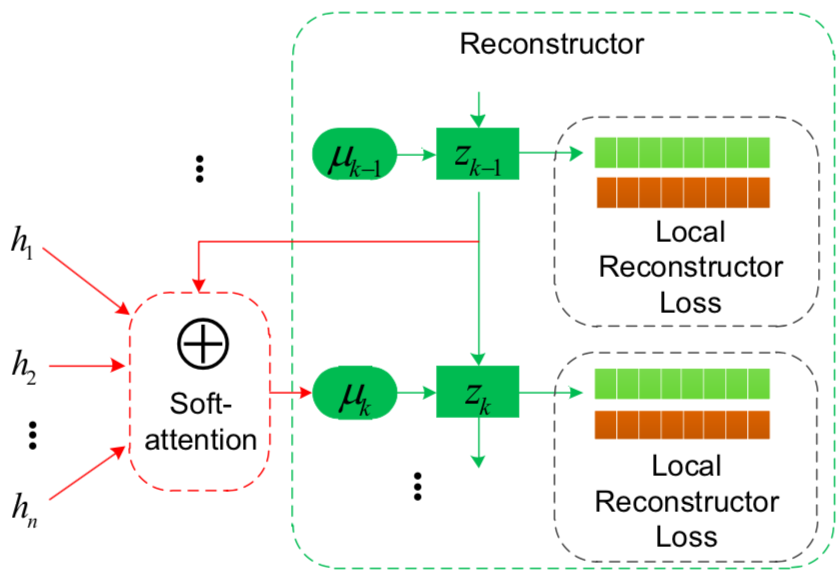
$$
\mu_t = \sum_{i=1}^{n}\beta_i^th_i
$$
$\beta_i^t$はタイムステップtでの$i$番目の隠れ状態についてのアテンションメカニズムによって計算された重みである.
また,各LSTMユニットでは次のように計算される.
\left(\begin{matrix}
i_t \\
f_t \\
o_t \\
g_t
\end{matrix}\right) =
\left(\begin{matrix}
\sigma \\
\sigma \\
\sigma \\
\tanh
\end{matrix}\right)T
\left(\begin{matrix}
\mu_t \\
z_{t-1}
\end{matrix}\right)
また損失は以下のものを用いる.
\mathcal{L}_{rec}^l = \frac{1}{m}\sum_{j=1}^{m}\psi(z_j, v_j)
全体の損失
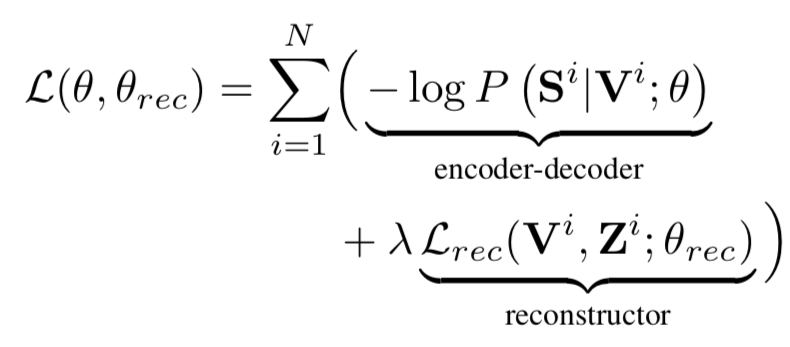
4. どのように有効性を検証したか?
MST-VTTデータセットを用いて,キャプション生成能力を評価する. MSR-VTTには10K個のビデオクリップと各ビデオクリップに対して20個の文章が含まれている.
比較する手法は,同じようなエンコーダ・デコーダの構造をしているMP-LSTMやSA-LSTMである.
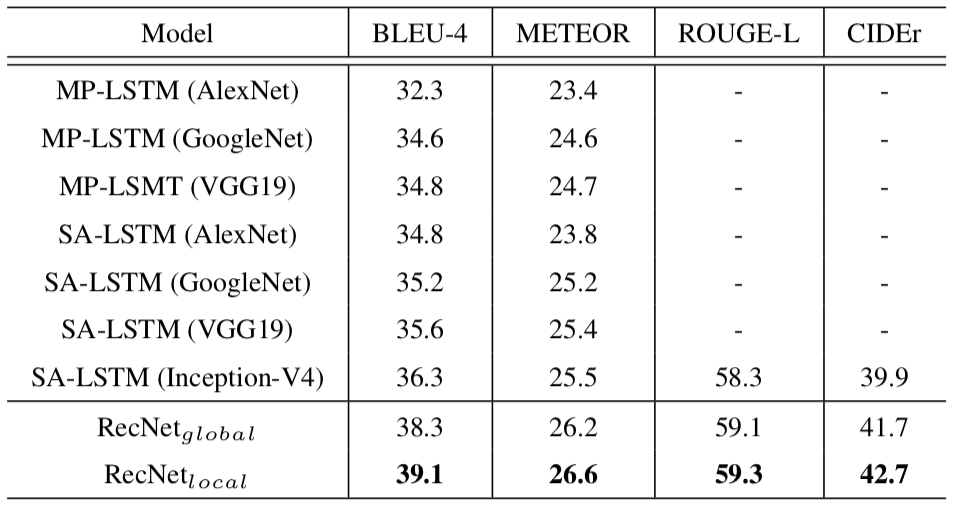
ローカルな情報に焦点を当てているリコンストラクタを組み込んだ提案手法のものが高いスコアを出している.
また,全体の損失における$\lambda$の値を変えた場合のBLEUスコアの変化をみる.つまり,リコンストラクタの影響の度合いを変化させている.
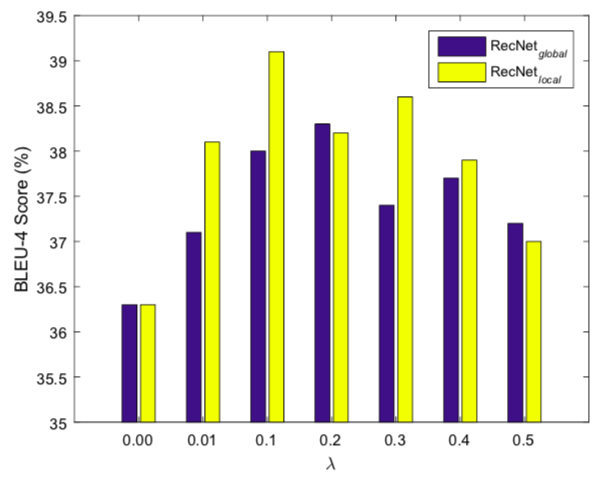
リコンストラクタを考慮しない$\lambda=0$のものより$\lambda$が0よる大きいものがスコアも高くなっているのでリコンストラクタの効果が現れていることがわかる.

5. 次に読むべき論文
-
Dual Learningを行うもの
- Dual Learning for Machine Translation $\cdots$ 言語⇆言語の機械翻訳
- Neural Machine Translation with Reconstruction $\cdots$ 言語⇆言語の機械翻訳
- Dual Supervised Learning $\cdots$ いろいろ
- テンプレートベースのもの
-
Natural Language Description of Human Activites from
Video Images Based on Concept Hierarchy of Actions $\cdots$ ビデオキャプション生成(古い) -
YouTube2Text: Recognizing and Describing Arbitrary Activities Using Semantic
Hierarchies and Zero-shot Recognition $\cdots$ ビデオキャプション生成(言語構造とツリーを利用) - Video Captioning with Transferred Semantic Attributes
- シーケンスの学習に焦点を当てたもの
- Translating videos to natural language using deep recurrent neural networks $\cdots$ CNN+RNN
- Sequence to sequence - video to text $\cdots$ S2VT