Wavenet Autoencoder
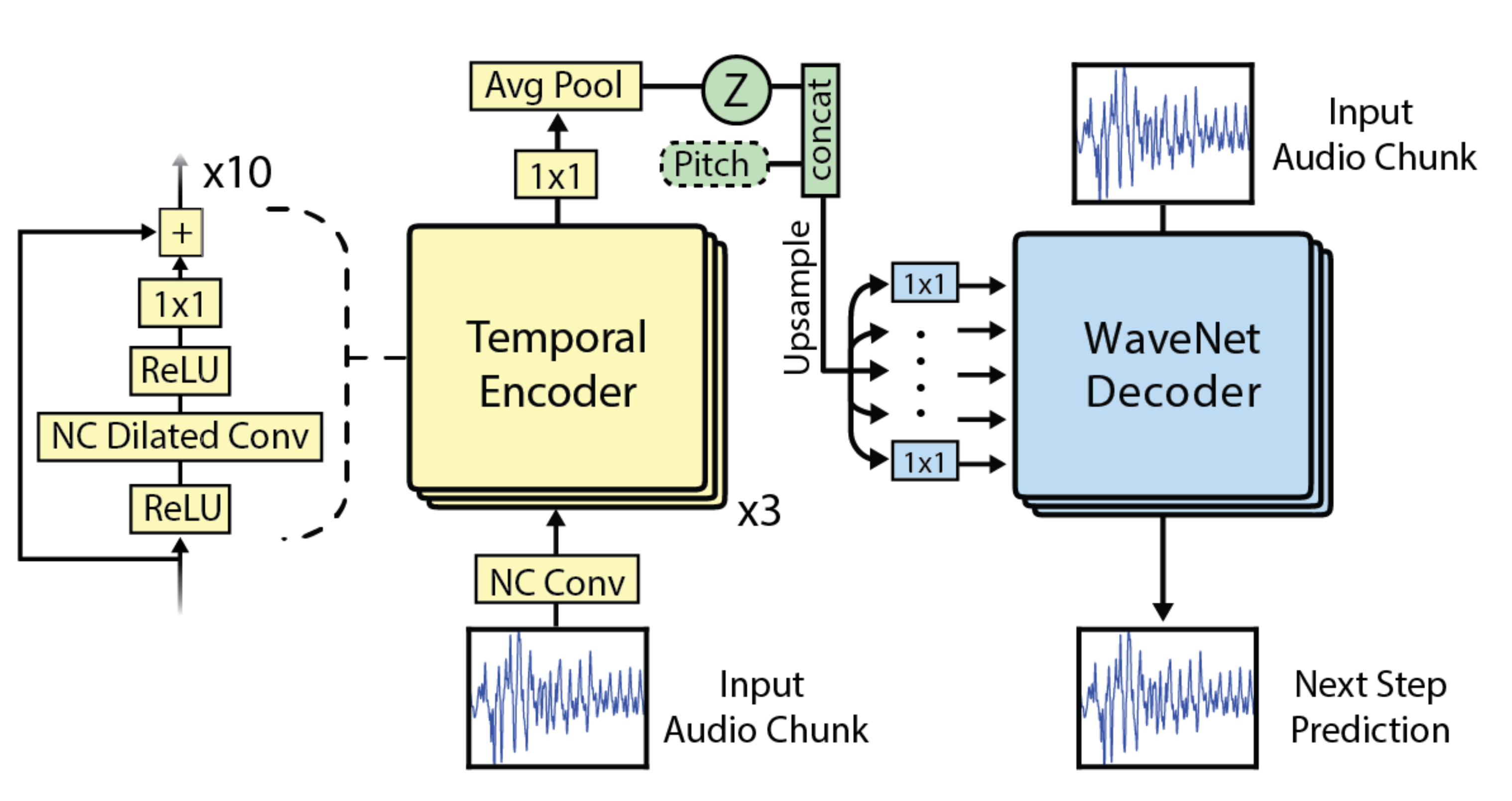
先日magentaがWavenet Autoencoderを発表しました.Wavenetと同じdilationを用いた,オートエンコーダーです.構造は下の図のようになっています.NCはNon Causalのことで,よく時系列のモデルでは,ある時点の畳み込みで,その時点の前の入力からしか入力を受け付けないようなことをしますが,これをしないということです.
Encoderでは各畳み込み層の出力を総計し,1×1の畳み込みをし,Avarage Poolongをしています.これによって,中間表現zを出します.DecoderではそのZに1×1の畳み込みを通し,各層のバイアスとして用いています.このDecoderはそのバイアス以外ではWavenetのものと同じ構造を使います.
今回,このWavenet Autoencoderを実装し,実際に音を作りました.
https://github.com/YoshikawaMasashi/wavenet-autoencoder-chainer
このWavenet Autoencoderは音色,音量,音程などの音楽の情報を抽出しようとしています. また,音程を中間表現zとは別にdecoderの入力にすることによって,音色などの情報だけを抽出できることが期待されます.今後音合成などで,ニューラルネットが音を合成するようなことが期待されます.この時に,音程は明確に指定できますが,音色は明確に言語化するには難しいものです.ですので,音色の情報だけ抽出できることはとても良いことです.
実装
実装は以下のようになっています.今回Decoder部分では,Wavenetで用いているgateという仕組みを割愛して実装しました.こういう時系列の生成では,理想的には最尤法を使いたいのですが,全ての波形の尤度を計算すると組合せ爆発を起こすので,別の方法を取る必要があります.magentaではビームサーチを用いて,尤も尤度の高い時系列を求めようとしていました.ここでは,ギブスサンプリングを用いました(つまり確率分布からサンプリングすること).ただし,そのままサンプリングするとノイズっぽくなったので,温度という概念を導入し,低音度でのソフトマックスの出力の確率分布からサンプリングしました.
import numpy as np
import scipy as sp
import scipy.io.wavfile
import chainer
from chainer import optimizers,serializers
import chainer.functions as F
import chainer.links as L
class WavenetAutoencoder(chainer.Chain):
def __init__(self):
super(WavenetAutoencoder, self).__init__()
self.d = 256
self.residual_cnl = 32
self.dilation_cnl = 16
self.skip_cnl = 64
self.z_cnl = 16
self.pitch_cnl = 7
self.dilation = [2**(i+1) for i in range(10)]*3
self.pooling = F.AveragePooling2D(ksize=(512,1))
self.add_link('embedid', L.EmbedID(self.d, self.residual_cnl))
for i,d in enumerate(self.dilation):
self.add_link('ecd_bfr_bn%d'%i, L.BatchNormalization(self.residual_cnl))
self.add_link('ecd_conv%d'%i,
L.DilatedConvolution2D(self.residual_cnl, self.dilation_cnl,
ksize=(3,1), pad=(d,0), dilate=d))
self.add_link('ecd_afr_bn%d'%i, L.BatchNormalization(self.dilation_cnl))
self.add_link('ecd_afr_conv%d'%i,
L.Convolution2D(self.dilation_cnl, self.residual_cnl,
ksize=(1,1)))
self.add_link('ecd_fnl_conv',
L.Convolution2D(self.residual_cnl, self.z_cnl,ksize=(1,1)))
self.add_link('dcd_bias_conv',
L.Convolution2D(self.z_cnl+self.pitch_cnl, self.dilation_cnl, ksize=(1,1)))
for i,d in enumerate(self.dilation):
self.add_link('dcd_bfr_bn%d'%i, L.BatchNormalization(self.residual_cnl))
self.add_link('dcd_conv%d'%i,
L.DilatedConvolution2D(self.residual_cnl, self.dilation_cnl,
ksize=(2,1), pad=(0,0), dilate=d, nobias=True))
self.add_link('dcd_afr_bn%d'%i, L.BatchNormalization(self.dilation_cnl))
self.add_link('dcd_afr_conv%d'%i,
L.Convolution2D(self.dilation_cnl, self.residual_cnl,
ksize=(1,1)))
self.add_link('dcd_fnl_conv1',
L.Convolution2D(self.residual_cnl, self.residual_cnl, ksize=(1,1)))
self.add_link('dcd_fnl_conv2',
L.Convolution2D(self.residual_cnl, self.d,ksize=(1,1)))
def encoder(self, x, test=False):
h = self['embedid'](x)
bs,seqlen,cnl = h.shape
h = F.swapaxes(h, 1, 2) # Variable (bs, cnl, seqlen)
h = F.reshape(h, h.shape+(1,))
step = []
for i,d in enumerate(self.dilation):
h_ = h
h = self['ecd_bfr_bn%d'%i](h, test=test)
h = F.leaky_relu(h)
h = self['ecd_conv%d'%i](h)
h = F.leaky_relu(h)
h = self['ecd_afr_bn%d'%i](h, test=test)
h = self['ecd_afr_conv%d'%i](h)
step.append(self['ecd_fnl_conv'](h))
h += h_
h = sum(step)
z = self.pooling(h)
return z
def decoder(self, x, z, pitch, test=False):
h = F.concat([z]*512,axis=3)
h = F.reshape(h, h.shape[:2]+(h.shape[2]*h.shape[3],1))
pitch = F.reshape(pitch, (1,)+pitch.shape+(1,))
bias = F.concat([h,pitch],axis=1)
h = self['embedid'](x)
h = F.swapaxes(h, 1, 2) # Variable (bs, cnl, seqlen)
h = F.reshape(h, h.shape+(1,))
bias = self['dcd_bias_conv'](bias)
bs,cnl,seqlen,_ = h.shape
step = []
for i,d in enumerate(self.dilation):
h_ = h
h = self['dcd_bfr_bn%d'%i](h, test=test)
h = F.leaky_relu(h)
pad = np.zeros((1,cnl,d,1), dtype=np.float32)
h = F.concat([pad,h],axis=2)
h = self['dcd_conv%d'%i](h)
h += bias
h = F.leaky_relu(h)
h = self['dcd_afr_bn%d'%i](h, test=test)
h = self['dcd_afr_conv%d'%i](h)
step.append(h)
h += h_
h = sum(step)
h = F.leaky_relu(h)
h = self['dcd_fnl_conv1'](h)
h = F.leaky_relu(h)
h = self['dcd_fnl_conv2'](h)
return h
def decode_generator(self, z, pitch, test=True):
h = F.concat([z]*512,axis=3)
h = F.reshape(h, h.shape[:2]+(h.shape[2]*h.shape[3],1))
pitch = F.reshape(pitch, (1,)+pitch.shape+(1,))
bias = F.concat([h,pitch],axis=1)
bias = self['dcd_bias_conv'](bias)
bs,_,seqlen,__ = bias.shape
x_ = 70
x = [x_]
pad = [np.zeros((1,self.residual_cnl,d,1), dtype=np.float32) for j,d in enumerate(self.dilation)]
for i in range(seqlen):
bias_ = bias[:,:,[i]]
h = self['embedid'](np.array([x_],dtype=np.int32))
h = F.reshape(h, h.shape+(1,1))
step = []
for j,d in enumerate(self.dilation):
h_ = h
h = self['dcd_bfr_bn%d'%j](h, test=test)
h = F.leaky_relu(h)
pad_ = pad[j]
h = F.concat([pad_,h],axis=2)
pad[j] = h[:,:,1:]
h = self['dcd_conv%d'%j](h)
h += bias_
h = F.leaky_relu(h)
h = self['dcd_afr_bn%d'%j](h, test=test)
h = self['dcd_afr_conv%d'%j](h)
step.append(h)
h += h_
h = sum(step)
h = F.leaky_relu(h)
h = self['dcd_fnl_conv1'](h)
h = F.leaky_relu(h)
h = self['dcd_fnl_conv2'](h)
beta = 1.7
h = F.softmax(h*beta)[0,:,0,0]
p = h.data
x_ = np.random.choice(256,p=p)
x.append(x_)
if i % 100 == 0:
print(i/seqlen)
return x
結果
一応学習やってみました.同じメロディで,128通りの音色で,128個の音声ファイルを作り,学習させました.
まずは元の音
https://soundcloud.com/ig4osq8tqokz/piano-original
生成された音
https://soundcloud.com/ig4osq8tqokz/wavenet-autoencoder
うーん微妙です.
多分,学習がまだ収束していないと思います.やはりこれは学習コスト高いです.
あとは,実装ミスっている可能性が高いので,指摘などいただけましたら幸いです.