はじめに
以前の記事で pythonで RestAPIを使ってサーチ結果を読み込む方法を書いたので、今度は逆にデータをSplunkに取り込む方法にチャレンジしてみます。
これができれば、データを取り込んで、加工して、その結果をSplunkに取り込むことが可能になります。(なんて便利な)
1. Splunk HECの設定
まずは、Splunk側の受け入れ体勢を整えておく必要があります。 Splunk側は HEC (HTTP Event Collector)という機能を設定して、RestAPI経由でデータを取り込むようにします。
HECの仕組みとしては、Global Portを設定して、データソースタイプ毎にTokenを発行することで、様々なログをRestAPIを使って取り込むことができます。またToken作成の際に sourcetypeやindexを指定できます。
1-1. HECのGlobal設定
[設定] - [データ入力] - [HTTP Event Collector] と進みます。
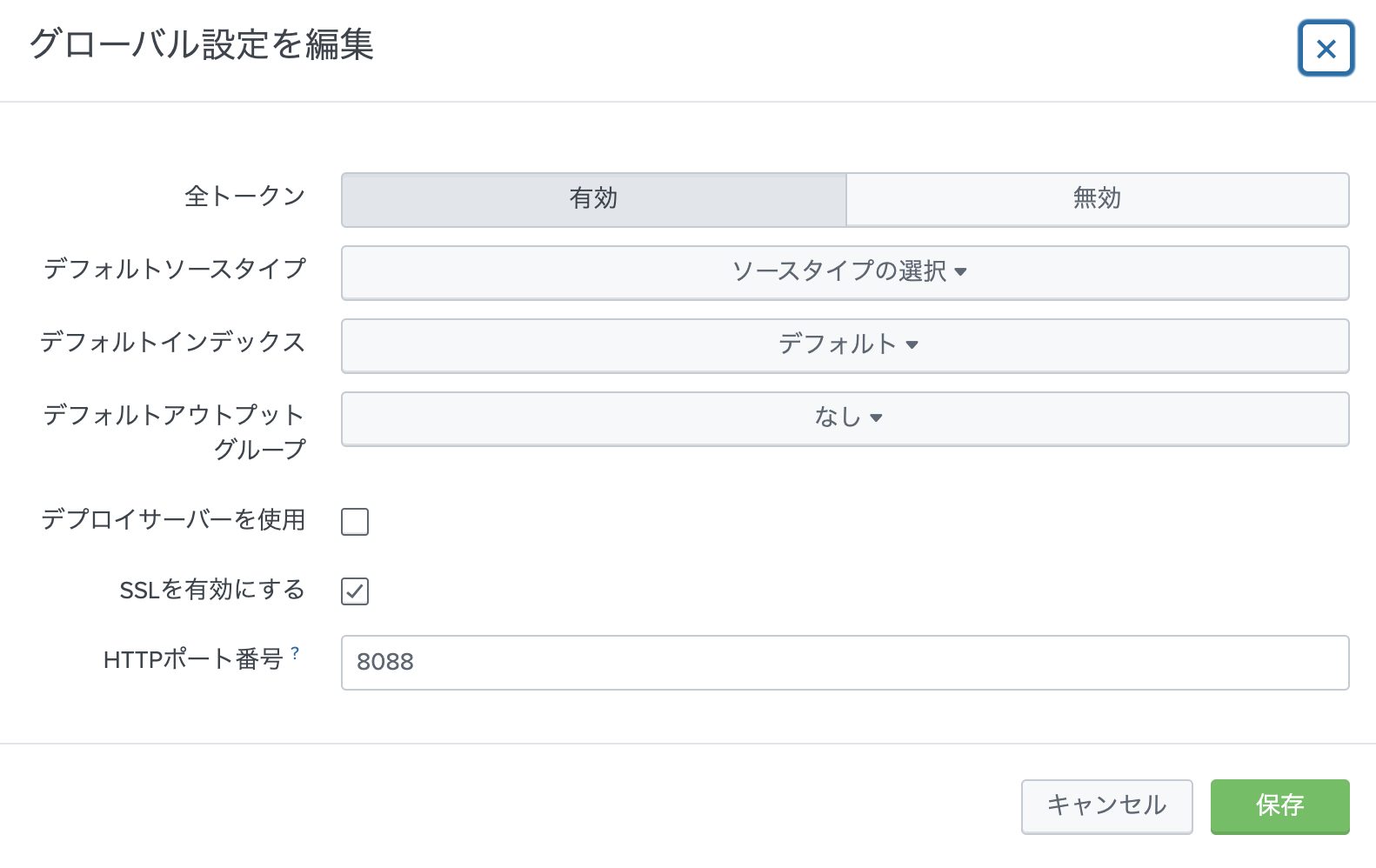
右上の グローバル設定をクリックします。

全トークンを有効にして、HTTPポート (default 8088)を確認します。SSLは有効が推奨ですが、証明書がないとワーニングが上がります。(ワーニングを無視もできますが)
1-2. Token作成
次に、Token作成をします。 一つ前の画面で右上の「新規トークン」をクリックします。
Tokenの名前を入力します。(あとはそのままでOK)
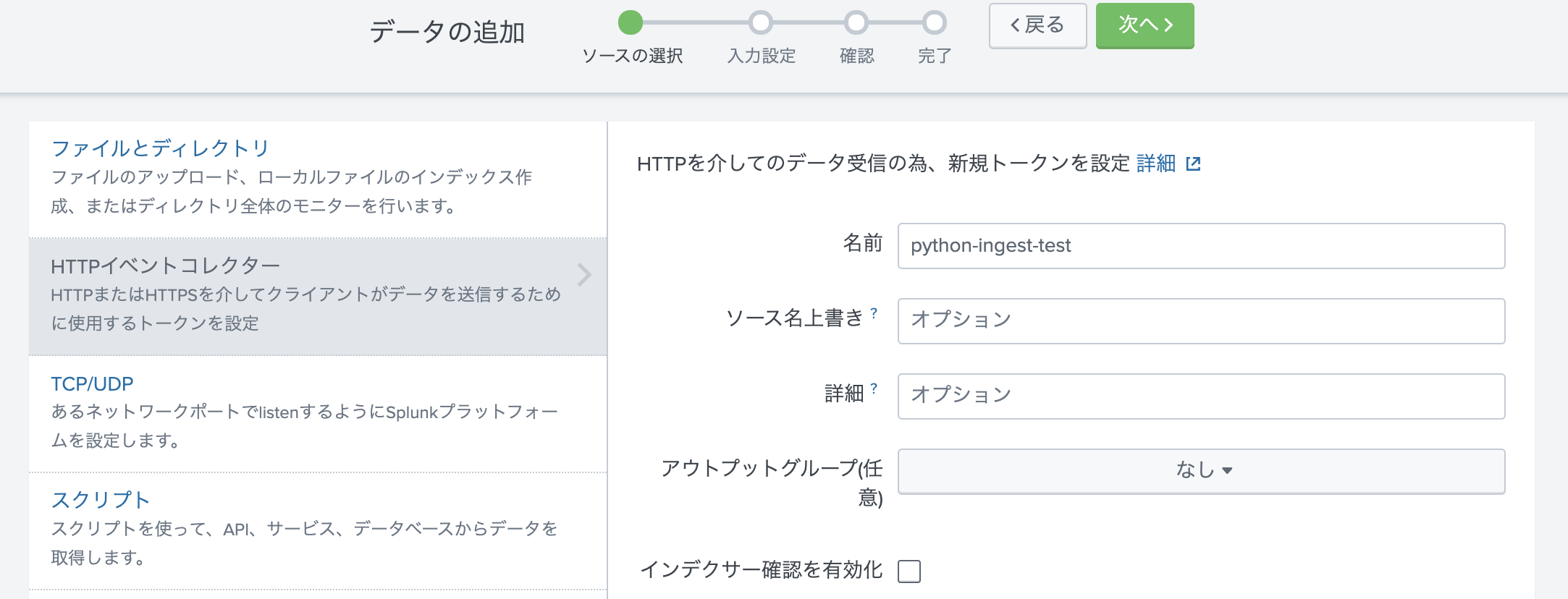
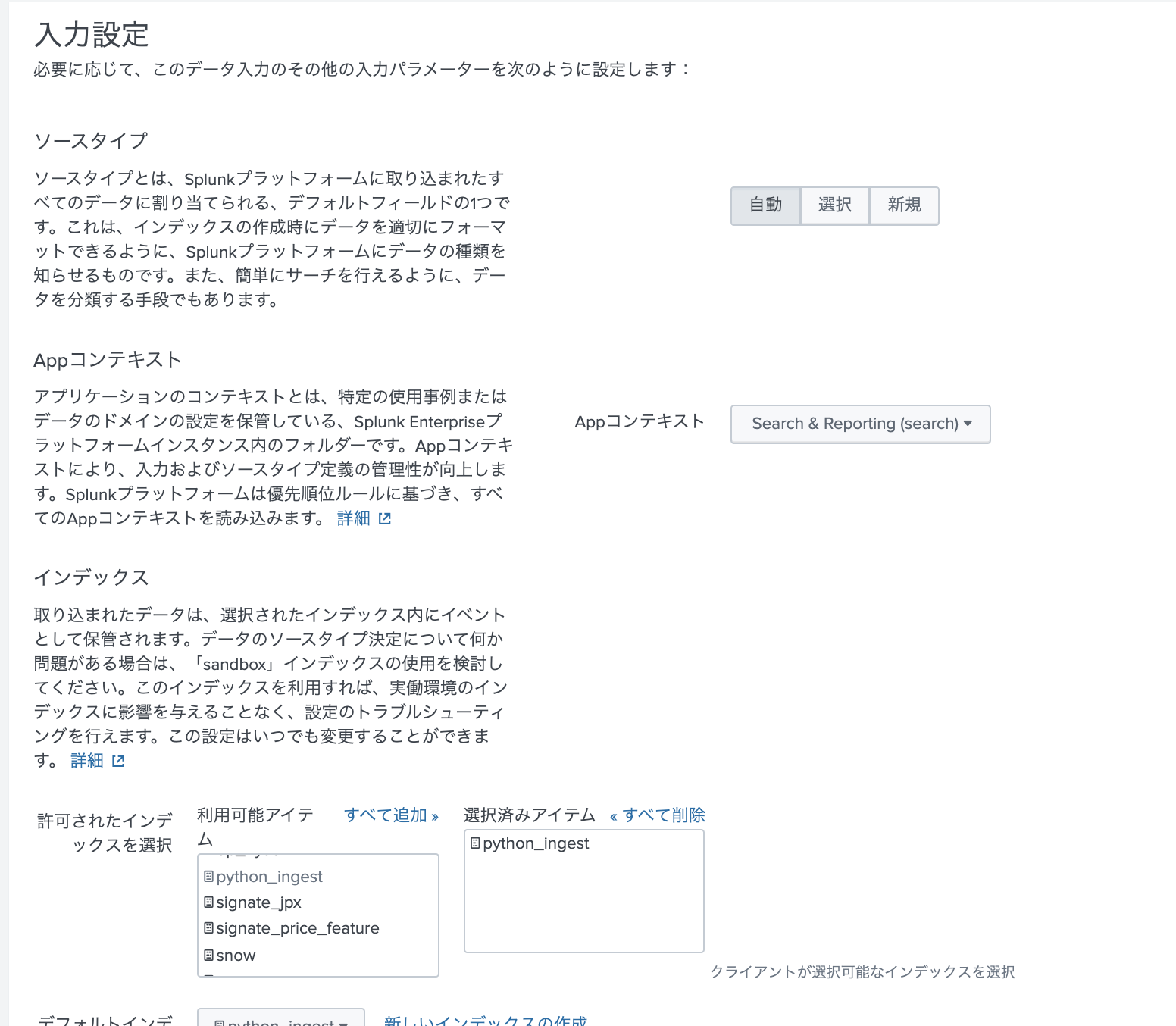
次に進んで、保存するIndexを指定します。ソースタイプは json形式になるので「自動」のままで大丈夫です。
必要に応じてIndexを新規作成して選択します。(既存のインデックスでも問題ありません)
1-3. Tokenの確認
HTTP イベントコレクターの画面に戻ると、作成したトークンが確認できます。このトークンを後ほど利用します。

2. curl を使ったデータ取り込みテスト
次に RestAPIでデータが取り込めるか curlを使ってチェックします。
以下のドキュメントにサンプルがあるので、そちらを参考に実行してみます。, を変更ください。
curl -k "https://<Splunk-server>:8088/services/collector/event" \
-H "Authorization: Splunk <TOKEN>" \
-d '{"event": "Hello, world!", "sourcetype": "cool-fields", "fields": {"device": "macbook", "users": ["joe", "bob"]}}'
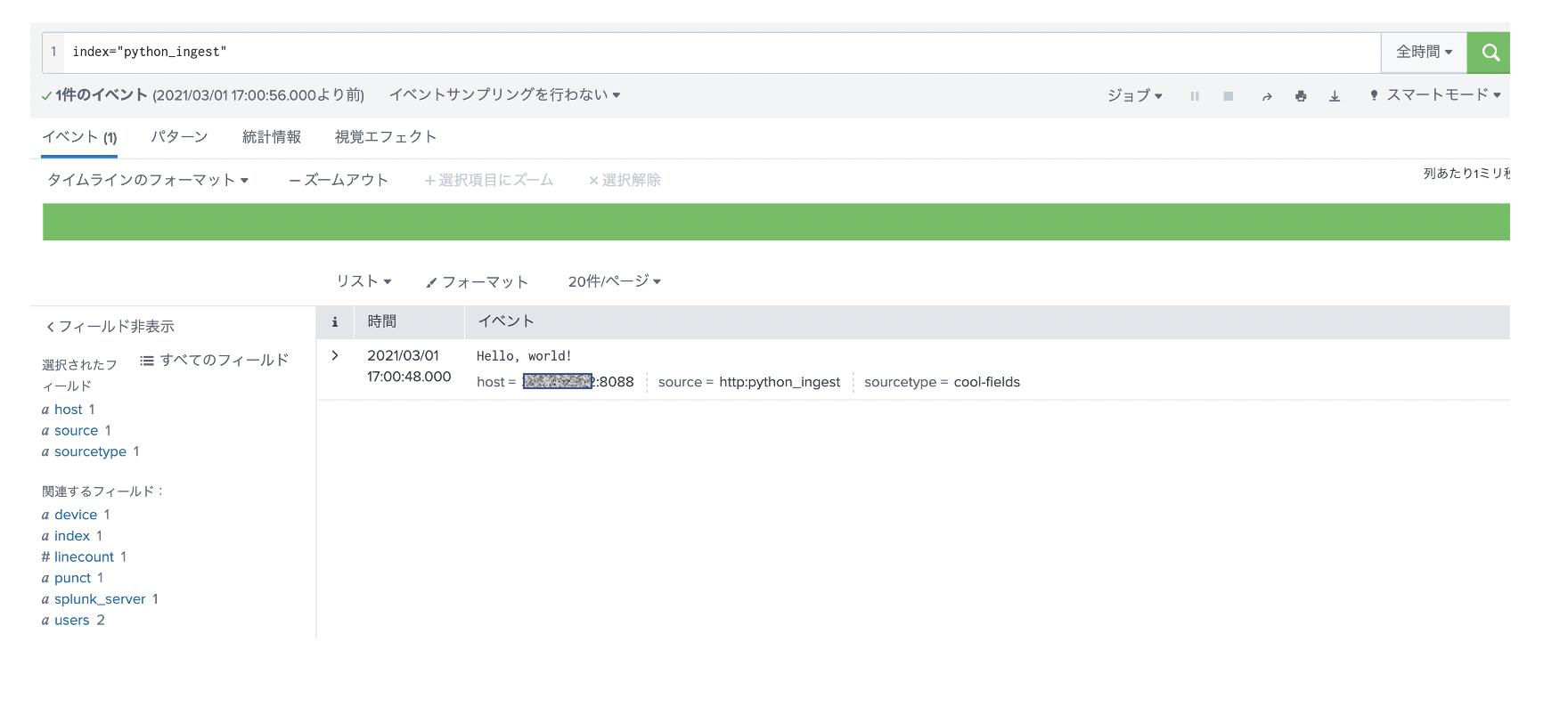
無事にデータを取り込めてますね。
3. pythonでの実装
curlでできることは、pythonでも行けるので、実装は簡単なのですが、シングルイベントではなく、複数イベントを取り込む必要があるので、そのあたりを実装する必要があります。
今回は、データフレーム形式のデータを、Splunkに取り込むまでを実装したいと思います。
元のサンプルデータはこんな感じ(NULLが多いなー)
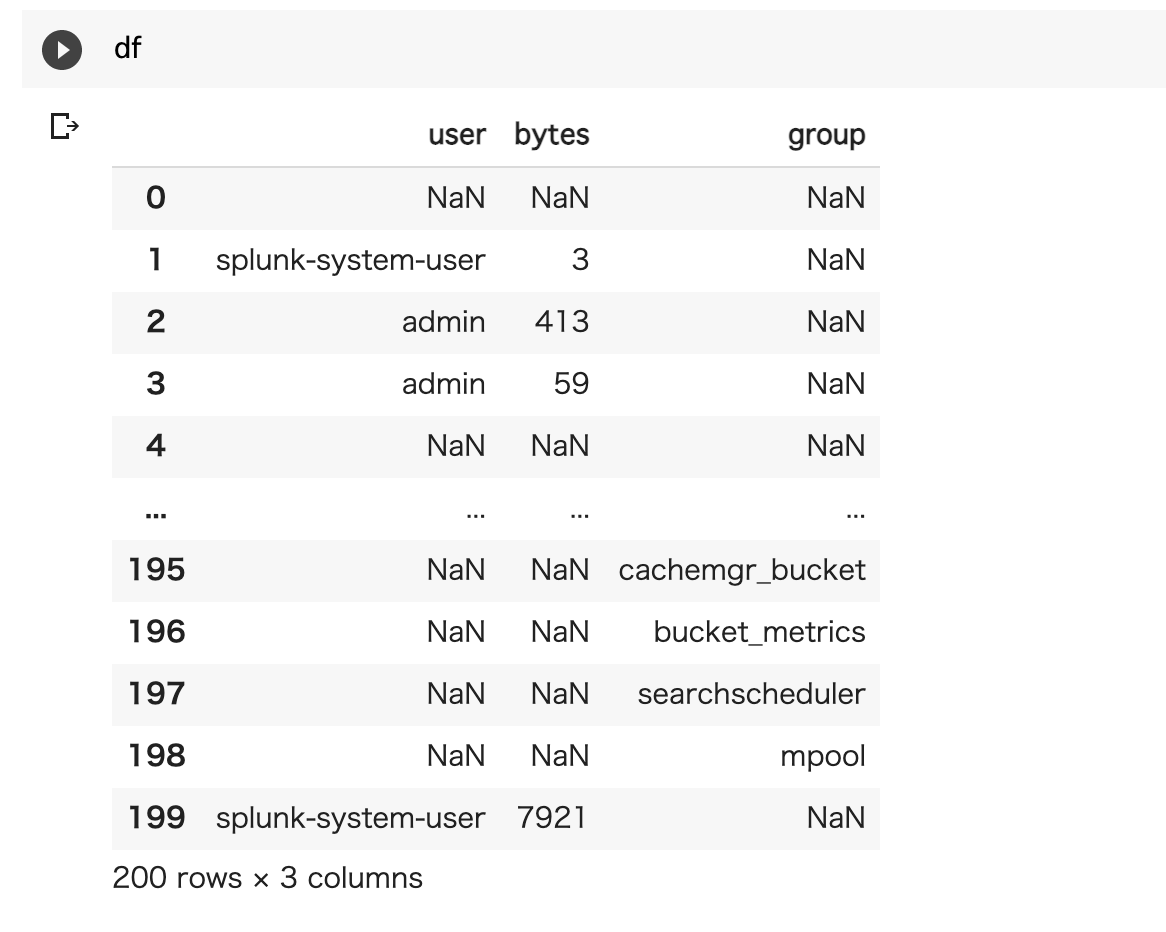
SpunkにHECで入れるためには、 rawデータもしくは、jsonフォーマットである必要があります。今回はjsonとして取り込もうと思います。
その場合、to_json()を使うことでjsonに変換できます。

これを for文を使って200件変換したデータをSplunkに取り込みたいと思います。
curlのコマンドを pythonで変換して、先ほどのデータをjsonに変換したものをループでHECに飛ばしてます。今回は証明書をセットしていないので、verify=f としてるので、ワーニングが出ますが今回は無視します。下のコードのうち、<TOKEN値>と<Server> を変更ください。
# HEC を使ったデータ投入
# Splunk Cloudの場合 443 ポートになります。
import warnings
warnings.simplefilter('ignore') # SSL のワークにングを無視。(証明書が必要になるため)
TOKEN = "<TOKEN>"
SERVER = "<SERVER>" # https://xxx.xxx.xxx.xxx など
import requests
headers = {
'Authorization': 'Splunk ' + TOKEN,
}
for i in range(len(df.index)):
data = '{"event": ' + df.loc[i].to_json() + '}'
response = requests.post(SERVER + ':8088/services/collector' , headers=headers, data=data, verify=False)
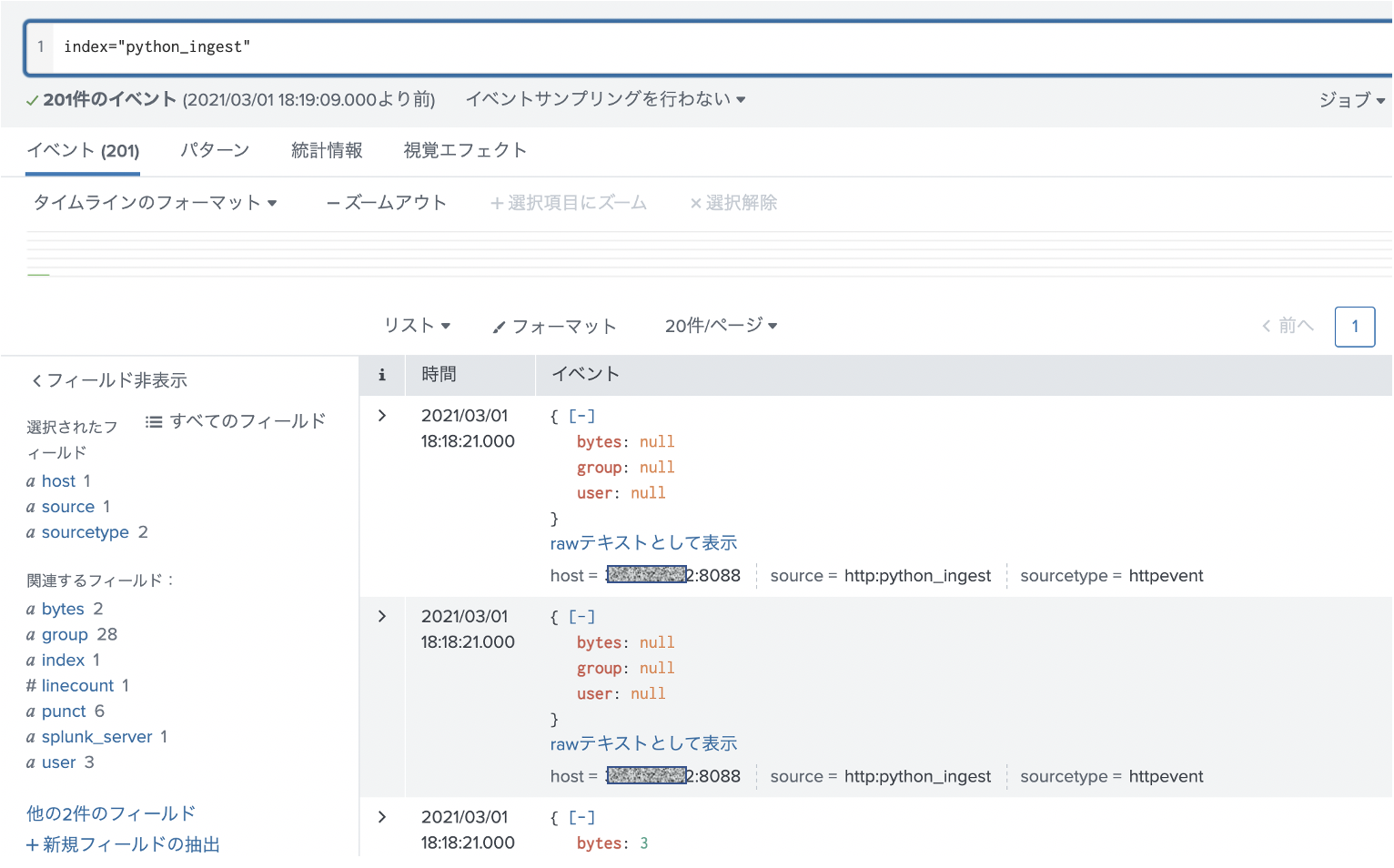
実行結果はこちらです。先ほどcurlコマンドでテストしたデータもあるので、全部で201件あります。json形式なのでそのままパースされてフィールド抽出まで完了してます。
最後に
大量のデータの場合、このループの方法だと時間がかかりそうなのでバッチ方式を検討した方が良さそうですが、分析で利用するためにsplunkから抜き出して、その結果をまたsplunkにフィードバックするだけなら、この方法で十分利用できそうです。
いちいちファイルに書き込んで、アップロードして。という手間が省けていい感じ。