追記修正
一部誤りがございましたので、追記修正させて頂きました。 (2020/1/24)
はじめに
Splunkでは、どんなテキストデータでも取り込めるようになってますが、取り込んだだけでは分析しにくいデータもあります。その一つが XML 形式のファイルです。Splunkでは、データフォーマットを自動で認識して、それぞれのフォーマットに合わせたイベント分類やフィールド抽出をしてくれるのですが、XML/jsonのような形式では、自動認識には対応していないため、読み込む時にひと工夫必要になります。(jsonの場合、ソースタイプで _jsonというのがあります)
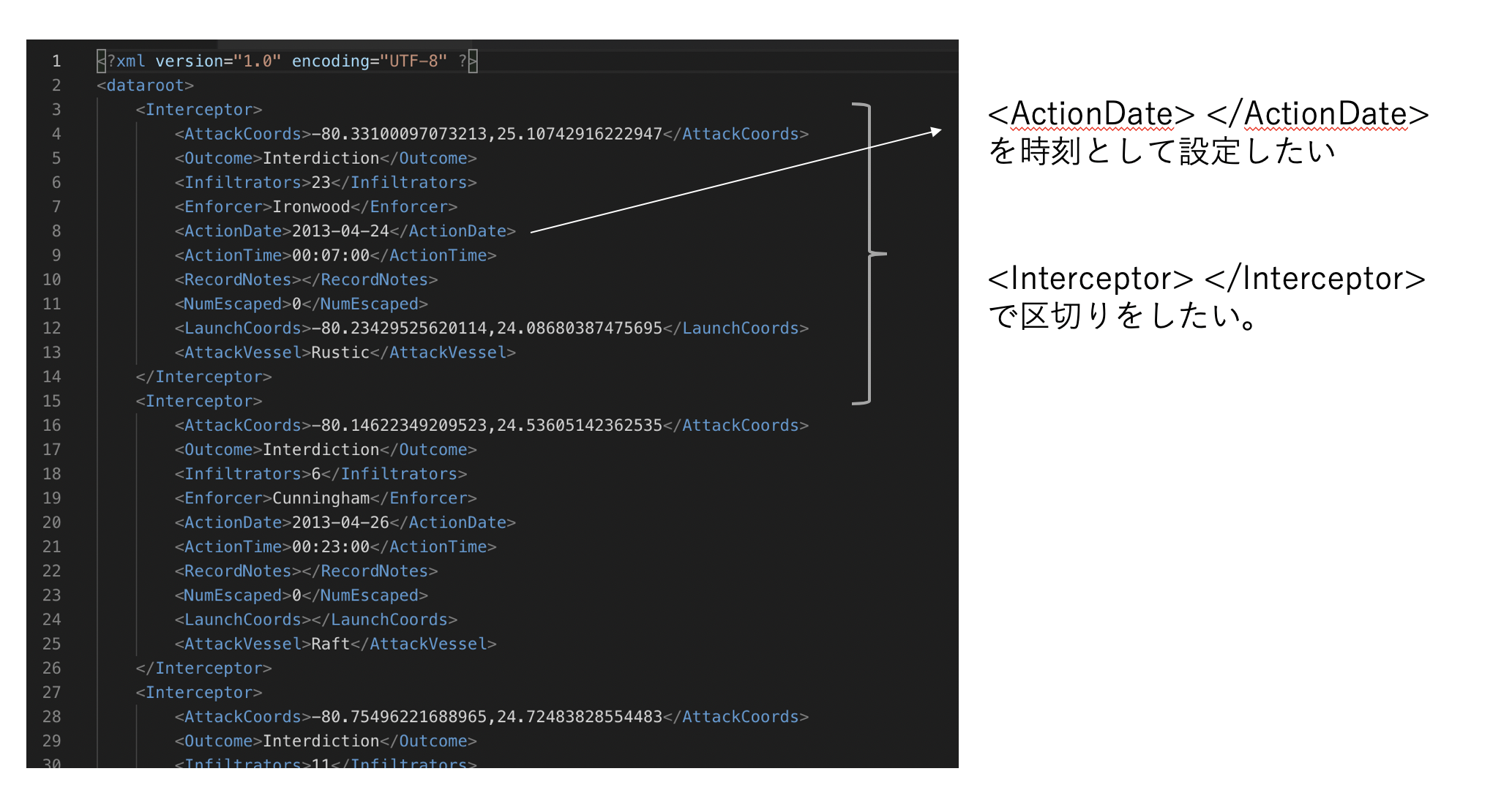
図:XMLサンプル
spath コマンドの紹介
そのまま読み込んだとしても、XMLごとに分けてくれる spath という便利なコマンドがあるので、まずはそちらを紹介します。
なにも考えずに XMLファイルを読み込むと、フィールド抽出もしていないので、その後の分析が非常に面倒です。(splunkでは、"=" で指定されていると自動的にフィールド抽出していくれるみたいです。)ただ spathコマンドを使うと、jsonやXMLタグごとにフィールド抽出をしてくれるので便利です。
https://docs.splunk.com/Documentation/Splunk/7.2.5/SearchReference/Spath
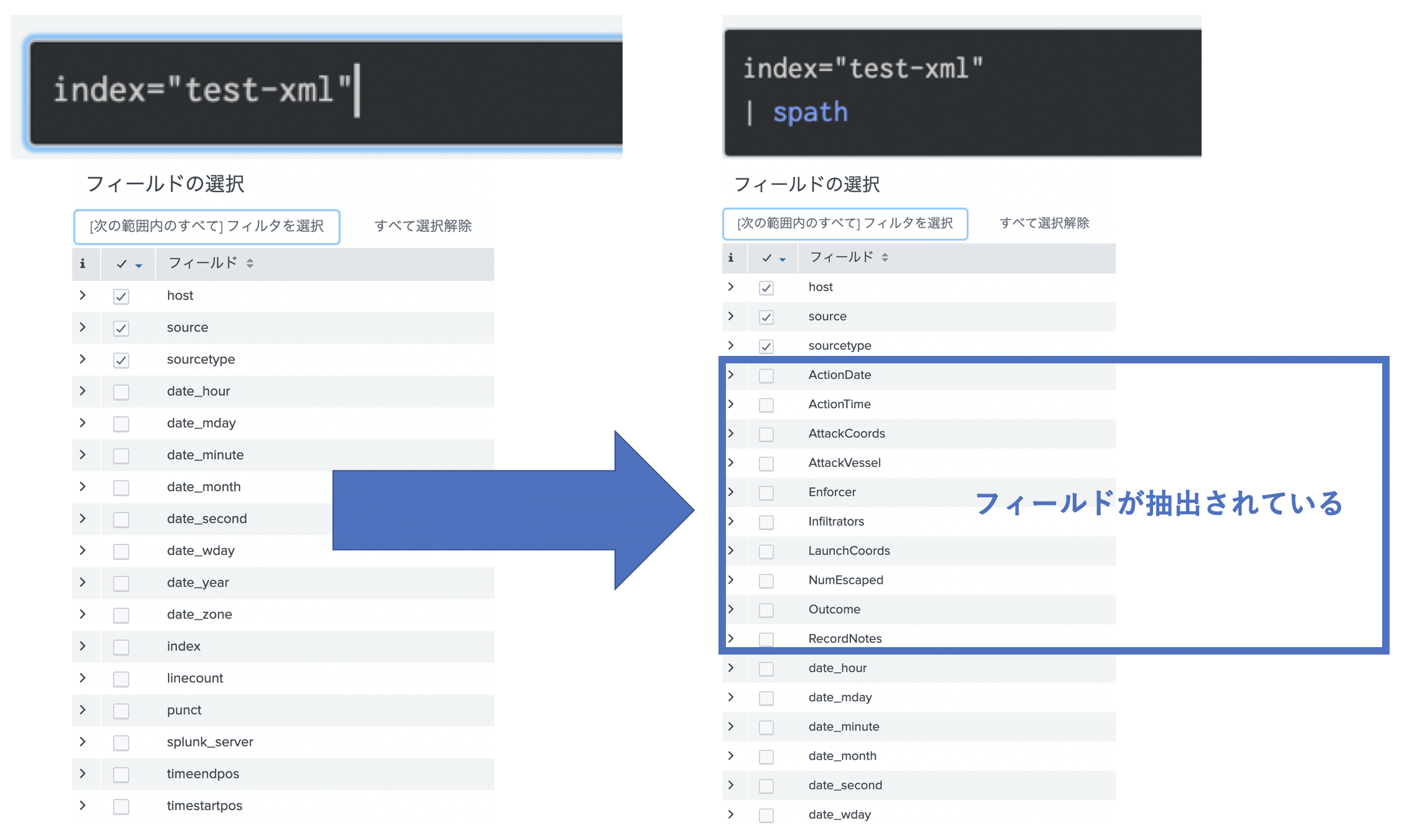
spath の課題
非常に便利なツールですが、spathには抽出してくれるのは、最初の5000 byteまでという制限があります(*追記あり)。また特定のフィールドをタイムスタンプとして指定するとか、イベント単位(イベントブレイク)の指定などができません。
(*追記修正) spath の制限は、limits.conf の設定により変更することが可能です。
また spathコマンドだけでなく、あとで紹介する KV_MODEも対象になります。そのため 1イベントの文字数が多い場合はどちらも設定が必要になります。
https://docs.splunk.com/Documentation/Splunk/latest/Admin/Limitsconf
[spath]
extraction_cutoff = 10000 (defaul:5000)
ソースタイプとは
データをサーチで読み込んだり、Index化する際の定義のようなものです。Splunkでは様々なタイプのログを取り込めるので、ログによってタイムスタンプの位置やイベントの改行ポイントが違っていたり、フィールド抽出の指定が違ったりします。そのためログにあったソースタイプを指定する事で、正しくデータを取り込めるようになります。各ベンダーのSplunk Appをインストールすると、その製品のソースタイプが予め用意されていたりします。
ソースタイプの作成
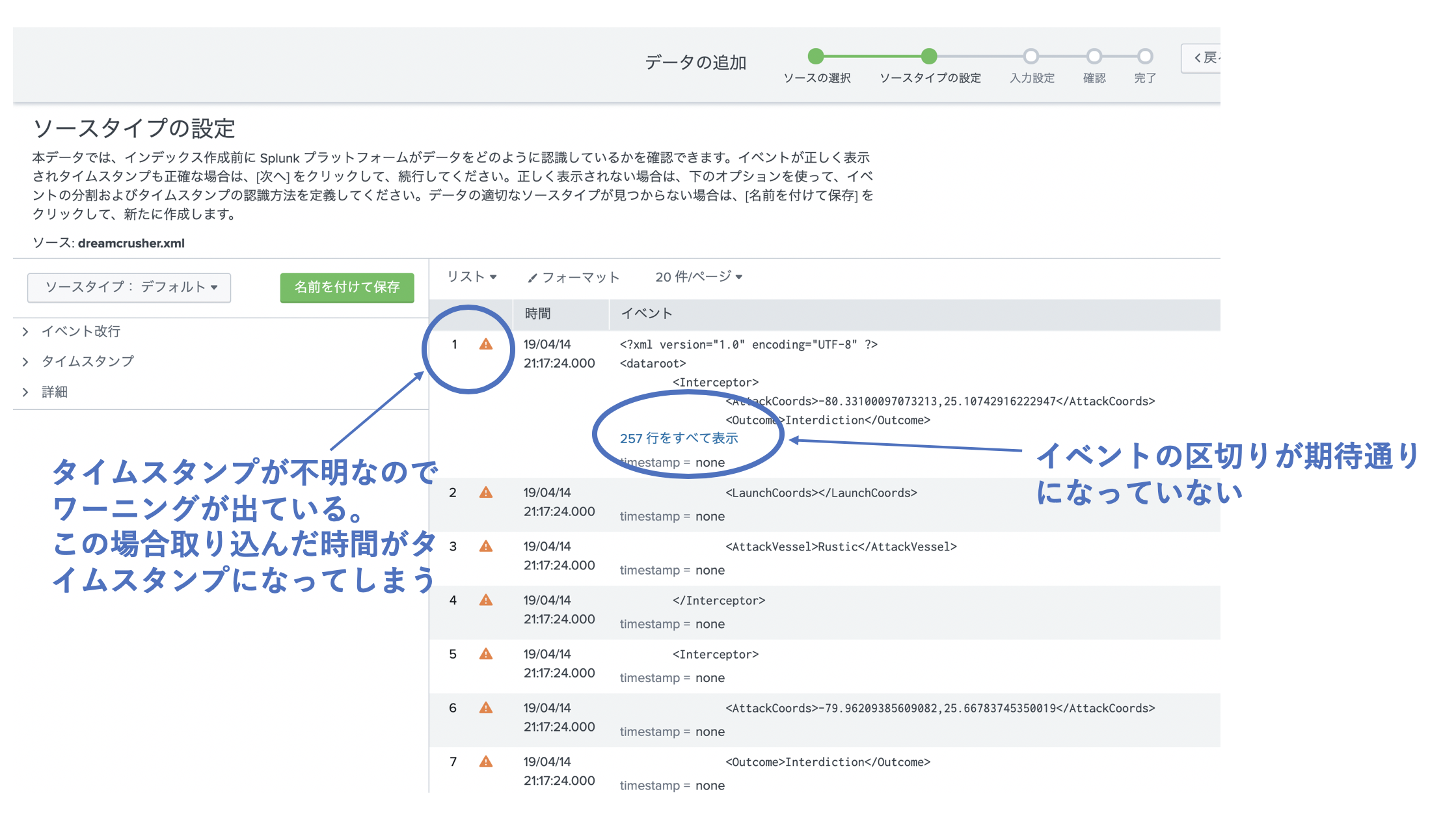
普通にXMLファイルを取り込むと以下のようになってしまいます。
今回は用意したXMLデータ(図1サンプルデータ)用にソースタイプで以下の3つを設定します。
- イベント単位(イベントブレイク)の指定
- タイムスタンプの指定
- フィールド抽出指定
1. イベント単位(イベントブレイク)の指定
そのままでは1行1イベントと認識されてしまうため、 <Interceptor> の箇所でイベントを区切るようにしたいと思います。イベント改行という設定箇所で「正規表現」を選択し、パターンに ([\r\n]*) を入力します。 ([\r\n]*)は、それぞれ改行を表す正規表現で、改行+ のパターンで区切るというイメージです。

2. タイムスタンプの指定
<ActionDate> で囲まれている、時刻をイベントのタイムスタンプとして指定したいとします。
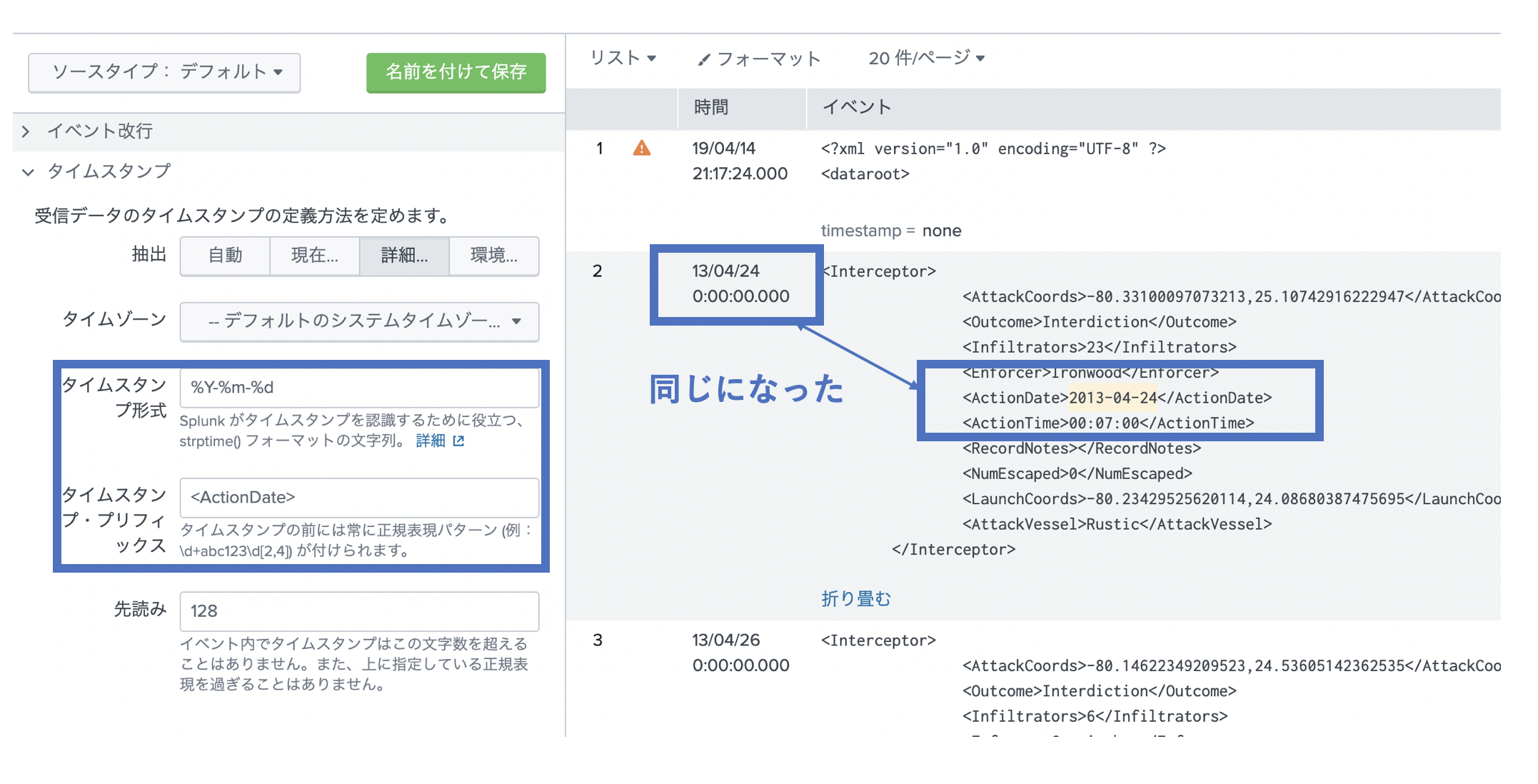
注意)指定した日付について、デフォルトでは過去に遡って2000日(約5-6年)前までのデータに制限されてます。そのためそれ以前のデータをタイムスタンプとして指定したい場合は、下の詳細設定で MAX_DAYS_AGO パラメータを追加設定する必要があります。
また今回は、日付と時刻が別のXMLタグにありましたが、このような場合は datetime.xml で指定するとうまく取得できます。(今回は日付だけで進めさせて頂きます。)
3. フィールド抽出
各XML タグをフィールド名として抽出します。KV_MODEというパラメータがあり、xmlと指定すると、サーチの際にフィールド抽出してくれます。同じくjsonと指定するとjsonを認識してフィールド抽出してくれます。この他にも INDEXED_EXTRACTION というパラメータがありますが、こちらは index 時にパースをすることになり、disk容量が増えてしまいますので、できる限り KV_MODEの利用をお勧めします。両者は排他的に動くのでご注意ください。
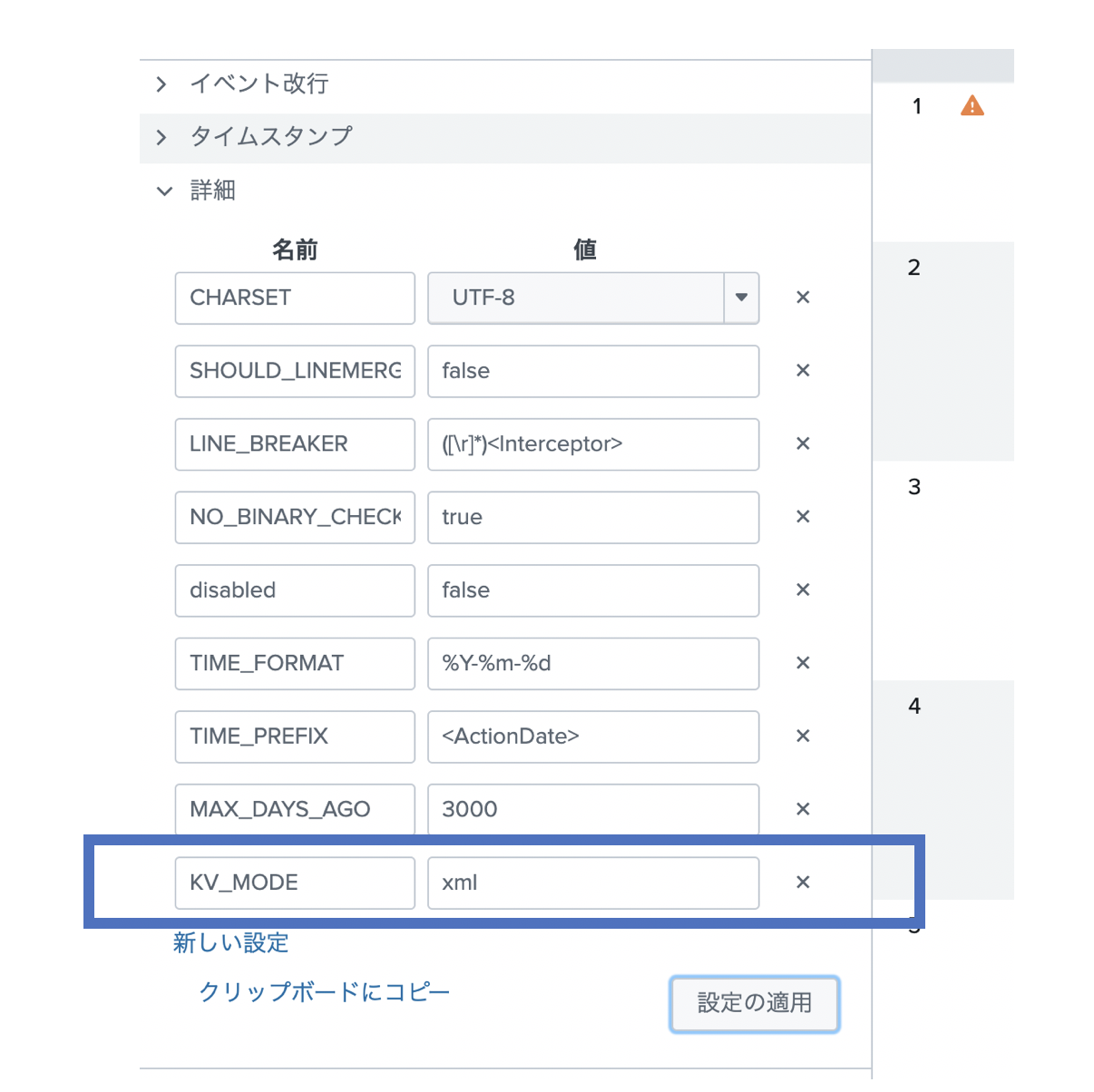
結果

その他
Splunkには、デフォルトで様々なタイプのソースタイプが用意されてます。jsonや csvの場合は、最初から_jsonや csvなどのソースタイプが用意されていますし、アプリをインストールするとソースタイプが用意されているので、まずはそちらを確認した方がいいかと思います。
https://docs.splunk.com/Documentation/Splunk/7.1.1/Data/Listofpretrainedsourcetypes