はじめに
Splunk MLTKを使った新しい機能として、Smart Workflowというのが発表 されました。
MLTK の機能としては、以下のように用途を限定する代わりにアルゴリズムとかそういう難しいことを気にせずに利用できるようにした機能(App)です。

このSmart Workflowsという機能の一つとして Smart Ticket Insight というAppがリリースされましたが、サービスチケットの中身をみて分類してくれるという機能になっております。ただし日本語でも大丈夫なのか? というのが気になったので今回日本語のログを使って利用時の注意点をチェックしたいと思います。
Smart Ticket Insight で何が出来るの?
詳細はこちらのBlogを参考にさせていただきます。
https://www.splunk.com/en_us/blog/platform/smart-ticket-insights-app-for-splunk.html
Blogによると、IT運用チームは日々膨大な種類のサポートチケットに直面しており、このAppを利用することでチケットデータのパターンを特定し迅速なトリアージを可能にするようです。パターンを特定出来ると問題特定を早めたり、その後の処理を自動化したり出来るようになるかもしれません。
この Ticket Insight Appでは、このようにチケットを内容によって自動的に分類するモデルを作ったり、モデルを管理したり、適用したときの結果をダッシュボードで表示することができるようになります。
前提条件
前提条件としては以下のAppを Splunkに追加する必要があります。
- Machine Learning Toolkit
-
Python for Scientific Computing Add-on
(OSの種類ごとに分かれております) - Smart Ticket Insight
- Wordcloud Custom Visualization
- Circlepack Viz
ちょっと沢山に見えますが、中身としては上位2つはMLTKのAppで、最後の2つはグラフの拡張Appになります。
あと、対象ログには以下のフィールドが必要になります。(field名は異なっても大丈夫ですが、類似の内容が存在している必要があります)
・ Ticket番号
・ カテゴリー
・ サブカテゴリー
・ 内容・説明
Blogの中では、ServiceNow や Jiraの AddOnと一緒に使うことを想定しているようです。(Blog参照)
利用方法
それでは、実際にどのように利用するかみていきたいと思います。すでに前提条件が整った状態で進んでください。
Step1: データインプット
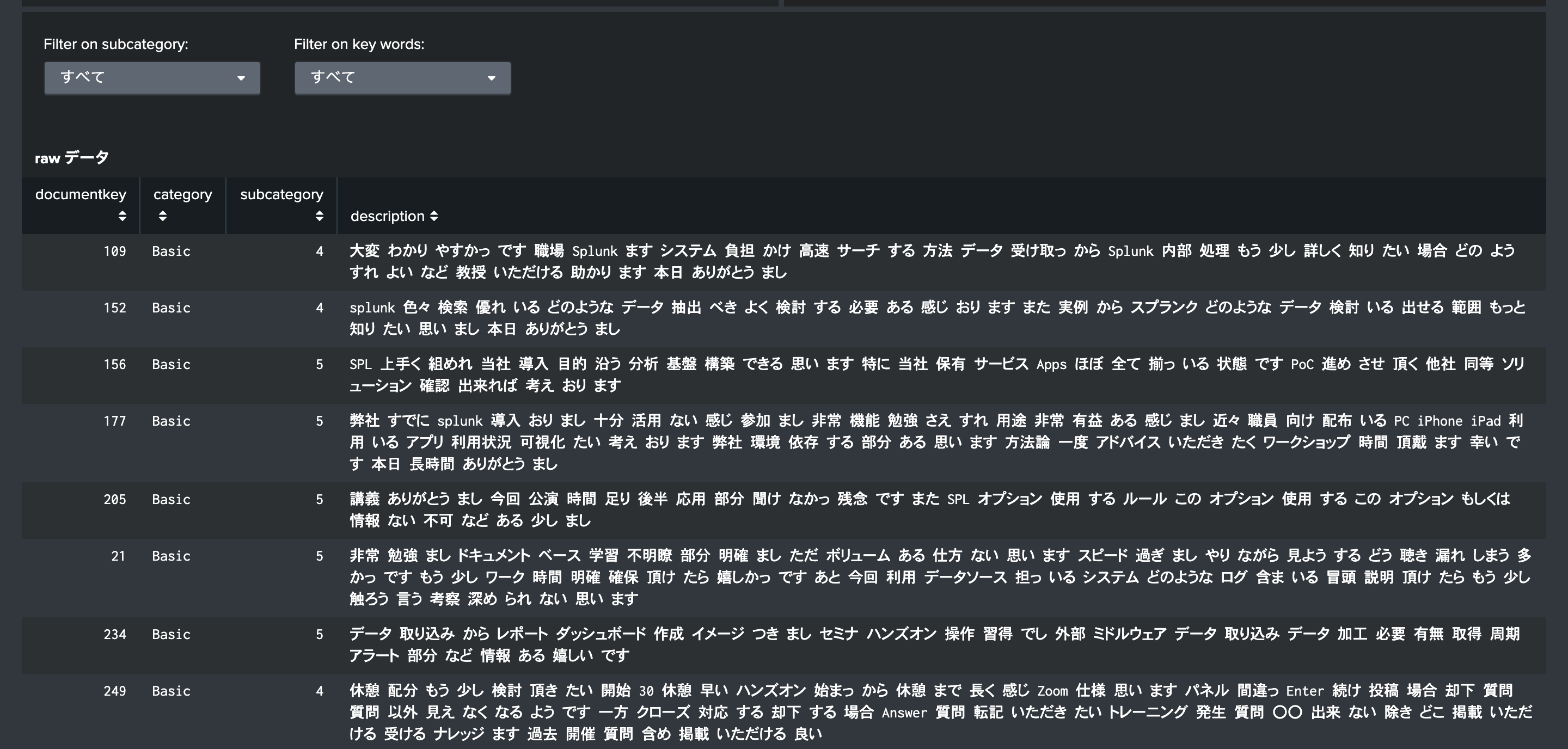
対象のログを検索し、条件にあうフィールドを指定していきます。条件とは前提条件にも書いた以下の4つです。(Ticket番号,カテゴリー、サブカテゴリー、内容・説明)
今回は日本語でのいいサンプルログが見つからなかったため、アンケート結果を分類してみたいと思います。
事前に確認したところ、日本後の場合はやはり形態素解析をした上でインプットしないとうまく分類してくれませんでしたので、日本語の形態素解析についてはこちらをご参考にしてください。
今回は、形態素解析済みのデータを利用していきます。
データをインプットすると、下図のような可視化が自動的にされます。このグラフを参考にいくつ以上の数があるカテゴリーを利用するか以下の閾値設定で指定します。
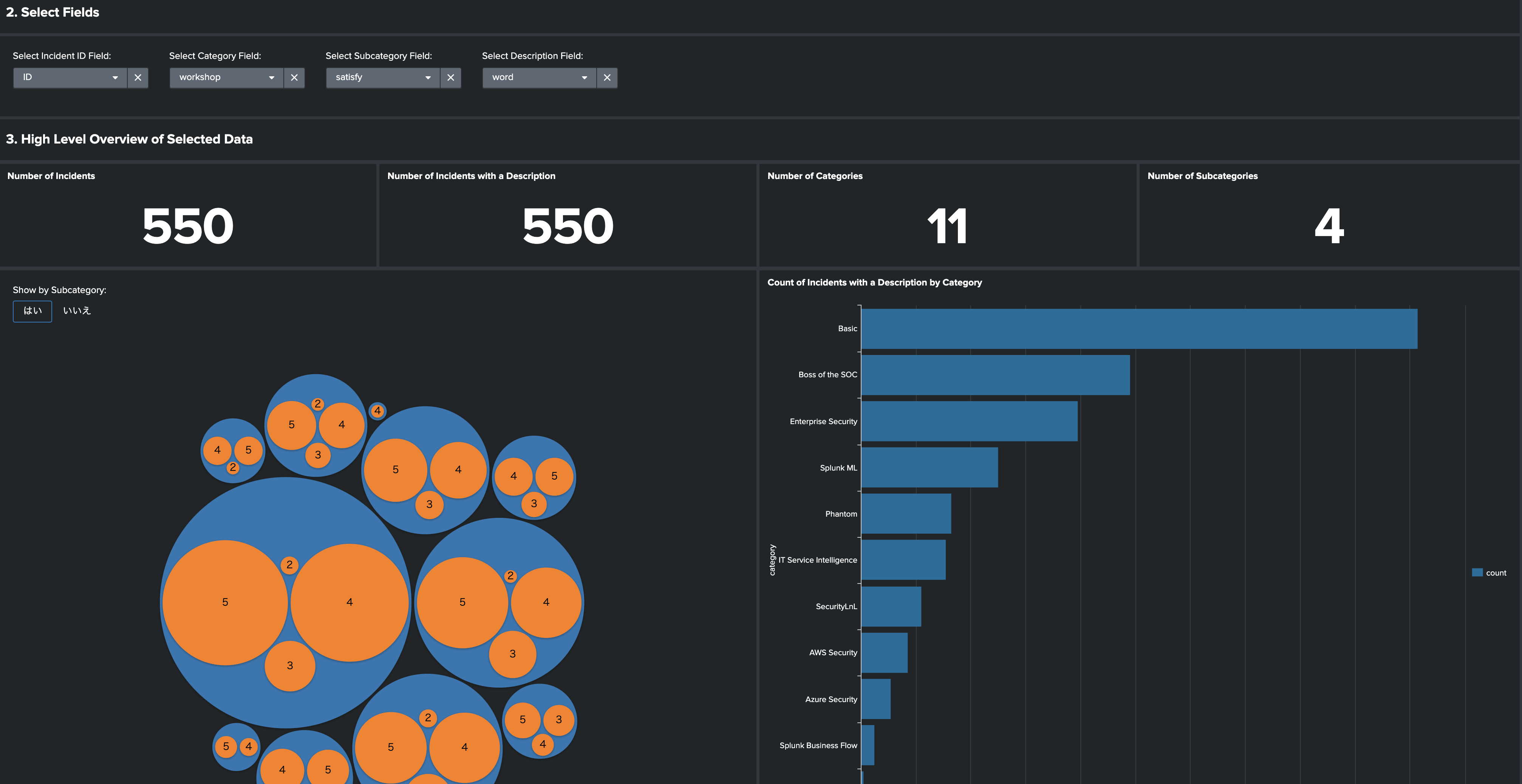
次に数の少ないカテゴリーは切り捨てるため、閾値を指定します。なぜならこの後カテゴリー毎にモデルを作成する必要があるからです。

Step2:
次のステップでは、カテゴリー毎にモデルを作成していきます。
設定する項目は以下の5つになります。
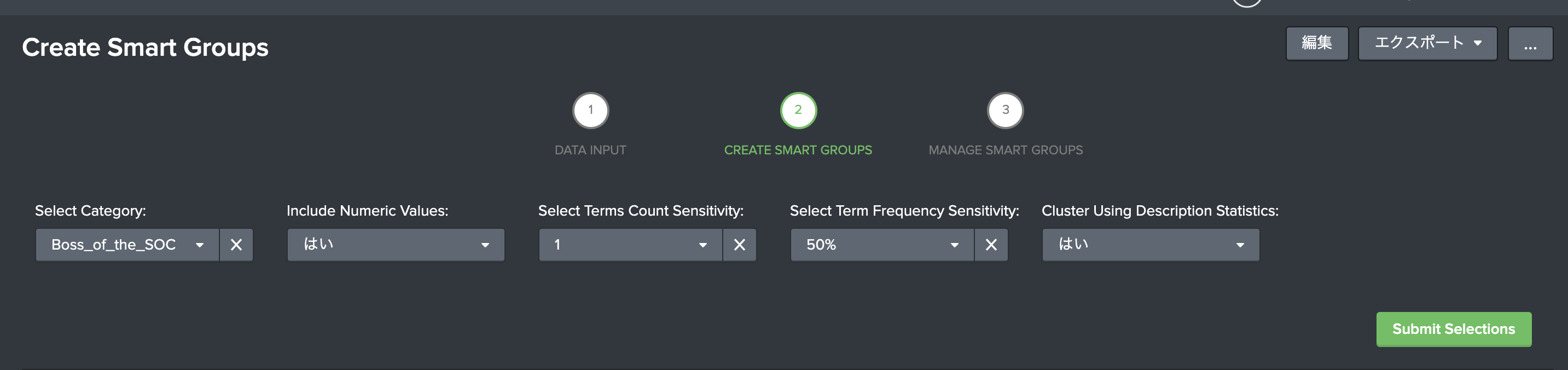
- Select Category : モデルを作成するカテゴリーを選択(1つずつしか作成できない)
- Incident Numeric Values (Yes / No) : 説明(文章)箇所で数値データも学習時に利用するかどうか。数字が無意味なものであれば、Noを選択してください。
- Select Terms Count Sensitivity : 説明(文章)箇所の最小文字数選択します。あまり短いと意味がないケースがあるため、絞り込むことができます。
- Select Term Frequency Sensitivity : TFIDFの max_df をセットします。 max_df とは頻出頻度の高いものを排除するため、その最大値になります。「私」などよく使われる単語が排除できます。ちなみに min_dfは 5% にセットされてます。(変更する場合、ダッシュボードの編集で直接編集が必要)
- Cluster Using Description Statistics (Yes/No): 説明(文章)箇所の単語数をクラスタリングに利用するかどうか。文章の長さも分類時の重要なアイテムになるためここで選択します
モデル作成
必要な設定項目をインプットしたら、"submit selection"をクリックしてモデルを作成します。結果が表示されるので問題なければ保存します。
TFIDFのオプションしばりが厳しいため、場合によっては対象データがないと表示されたり、グルーピングが結局1グループなんてことが結構ありました。その場合は、このアプリは使えないと思って諦めましょう!
オプションをチューニングする方法もありますが、結局重要度の低い単語を沢山利用してグルーピングするだけなので、あまり意味のないモデルができてしまいます。
ここでどんな事を裏でしているか簡単にみたいと思います。大きな仕組みとしては以下のようなステップで文章をグルーピングしております。
- TFIDF による特徴量抽出
- PCA による次元削減
- GMeans によるクラスタリング
ちなみにTFIDF のオプションは以下のようにセットされております。
| fit TFIDF description analyzer=word max_df=$df_max$ min_df=0.05 max_features=200 ngram_range=1-2 stop_words=english
min_df, max_df は先ほど説明した通りですが、そのほかにもいくつかオプションが設定されており、max_features=200 となるので、TFIDFによる特徴量の数は最大で200個になります。またngram_range=1-2 とあるので、単語として利用するのは 1または2センテンスとなります。stop_words=English とあるので、利用しない単語は"English"という単語です。
これらがデフォルトでセットされており、変更するには直接ダッシュボードの編集から変更する必要があります。
結果の確認
[Save Model] をクリックすると、モデルが保存されます。
日本語時の注意!
下の方に移動すると、作成したモデルについて、グループ毎に内容が確認できます。ただし、ワードカウントを使った可視化時に、サーチの中でアルファベットと数字以外は除外されるようなフィルターが入っており、日本語の場合全部除外されてしまいます。。。
そこで、日本語時利用は以下の箇所を修正してください。
「編集」ー「ソース」
以下の単語でサーチをかけて、対象箇所を編集します。
<編集前>
| rex field=description mode=sed "s/[^A-Za-z0-9]/ /g"
<編集後>
| rex field=description mode=sed "s/[^A-Za-z\W]/ /g"
\w を追加します。
ステップ3
あとは、本番で利用するだけです。
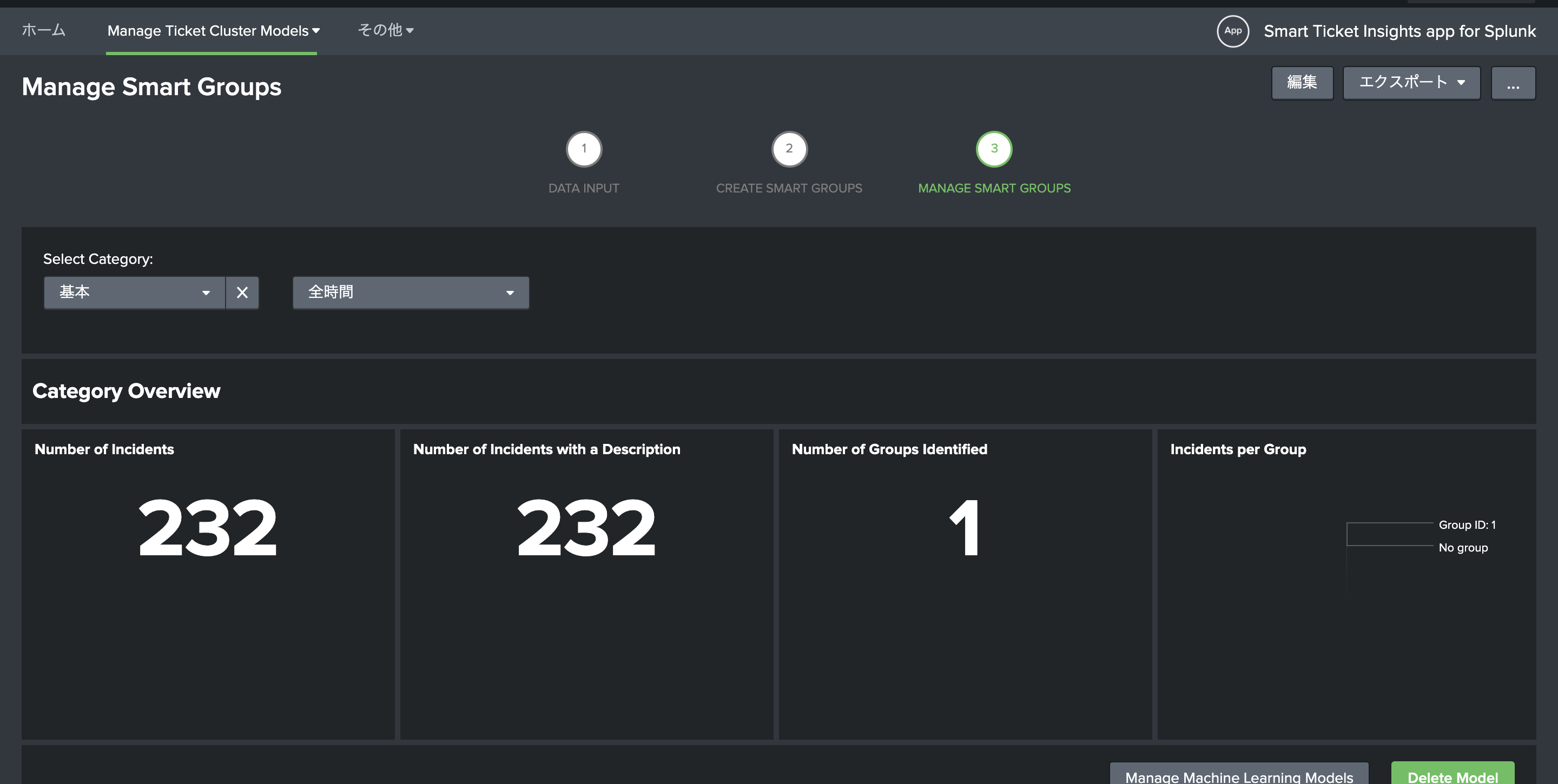
Manage Smart Group を上のタブから選択すると、作成したモデルをいつでも使ってグルーピングしてくれます。
グループを指定すると、グループの詳細が確認できます。
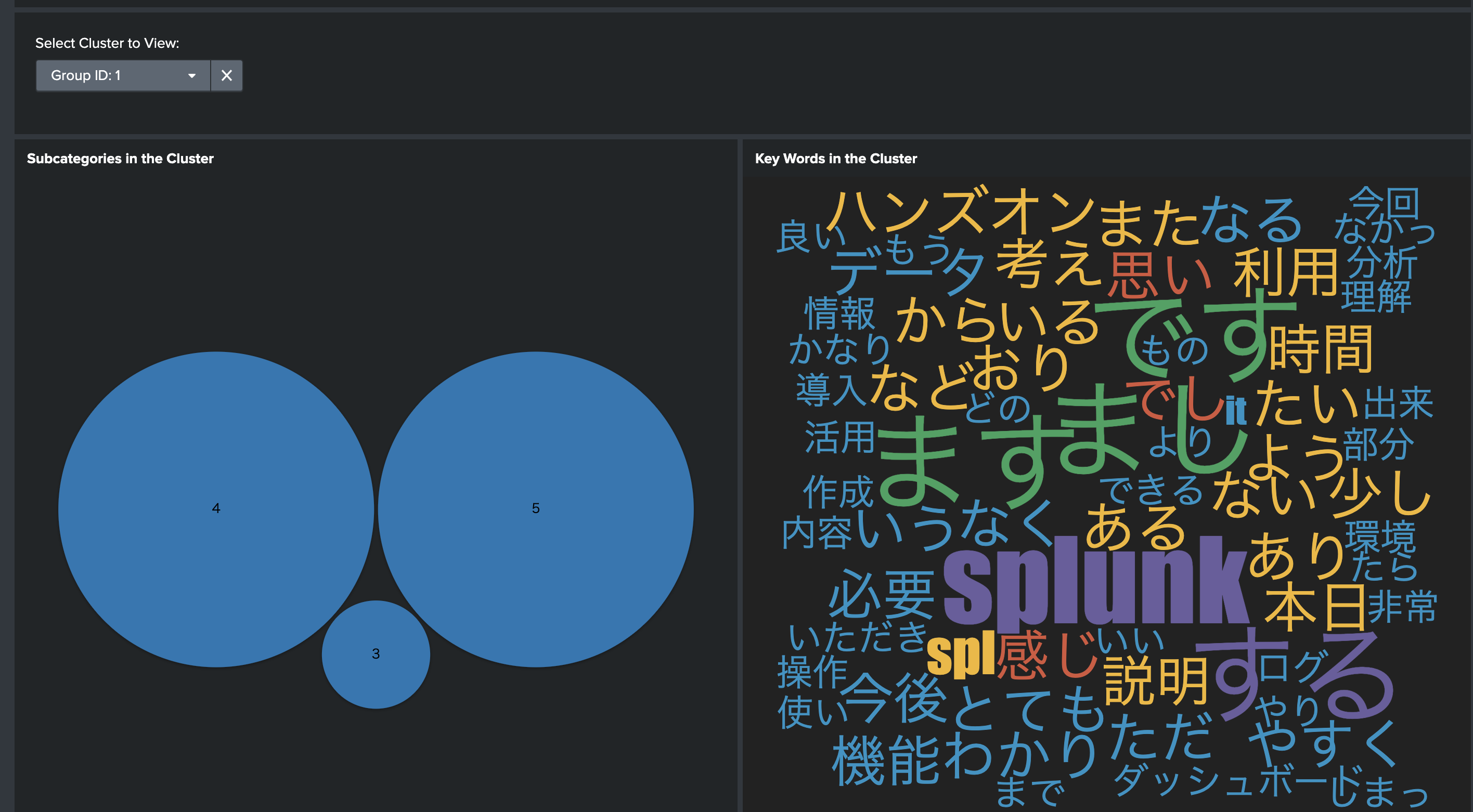
他のカテゴリーも同じ要領でモデルを作成&保存します。
保存されたモデルは、「Manage Smart Group」にて確認することができます。通常の運用ではこちらの画面で内容をチェックするのがメインになると思います。
最後に
正直な感想としては、利用シーンがだいぶ限られるなと思いました。
またうまく分類できない(対象文章などの問題で)ケースも多々あり、グルーピングが出来る状況でないと利用できない点やカテゴリー毎にモデルを作成しないといけないため、結構手間がかかります。
さらに日本語などの非英語に対応していないため、利用する際は別途形態素解析との組み合わせが必要です。
良かった点としては、分析手法について参考になりました。