目的
突然ですが predict と forecast の違いってご存知ですか? 私も知らなかったのですが時系列データのように一つのメトリックで過去の動きをもとに未来を予測することを forecastといい、カテゴリーなどを様々な特徴量をもとに予測することを predict というようです。(すみません余談でした)
時系列データを扱う場合 forecast したいケースは多々あります。ただしよくある問題として祝日は理解して予測してほしいとか、特別セール期間は普段と違うので考慮した動きを予測して欲しいとか考えたことありませんか?
Splunk MLTKにある StateSpaceForecast アルゴリズムを使うと、そういった特別な日を考慮した forecastができるようです。また他にも以下のような特徴があります。
- fit & apply で実行するため、一度作ったモデルを他のデータに対しても適用できます(同じような他システムとか)
- 特別な日を指定できます(祝日やセール日など)
- 差分データのみ利用して再学習が可能なので、学習時の負荷が少なくてすみます
- 複数の変数を同時に扱えます(効率的)
- null値は自動的に省いて学習してくれます(予測がnullにひきづられない)
それでは、まずは試してみたいと思います。ちなみに Splunkではこのアルゴリズムを使った予測を SmartForecastingと呼ぶようです。
デモデータについて
MLTKにある "Forecast App Logons with Special Days" というデモデータを利用します。
・applogonscount.txt : applogonscount.txt には、1時間毎のログインデータが約8ヶ月分あります(6300件)
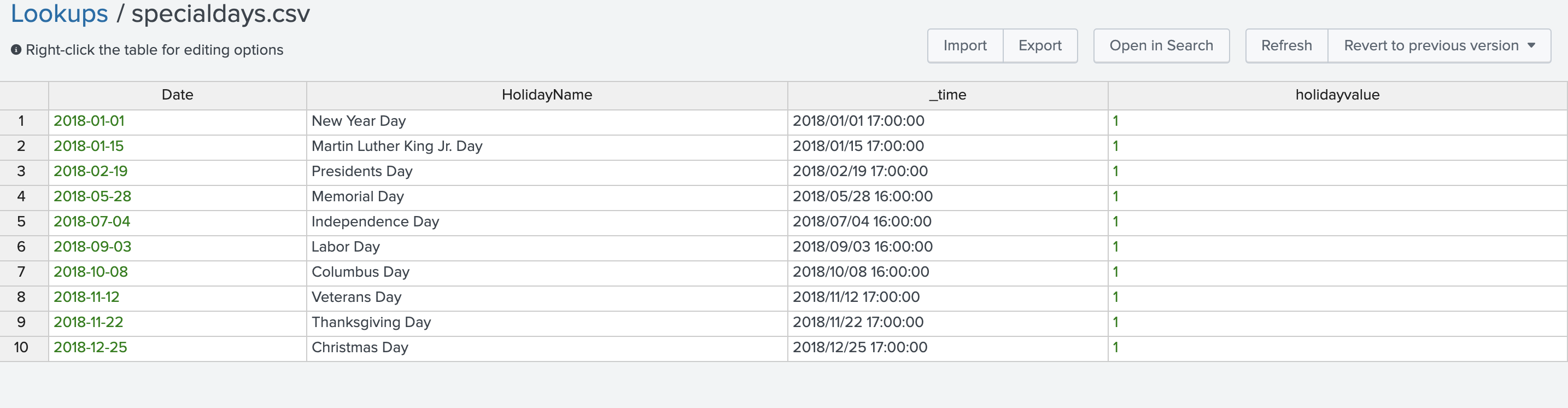
・specialdays.txt : 特別な日が記述されたリスト (*)lookupにすでに登録されており、以下のような内容になってます。
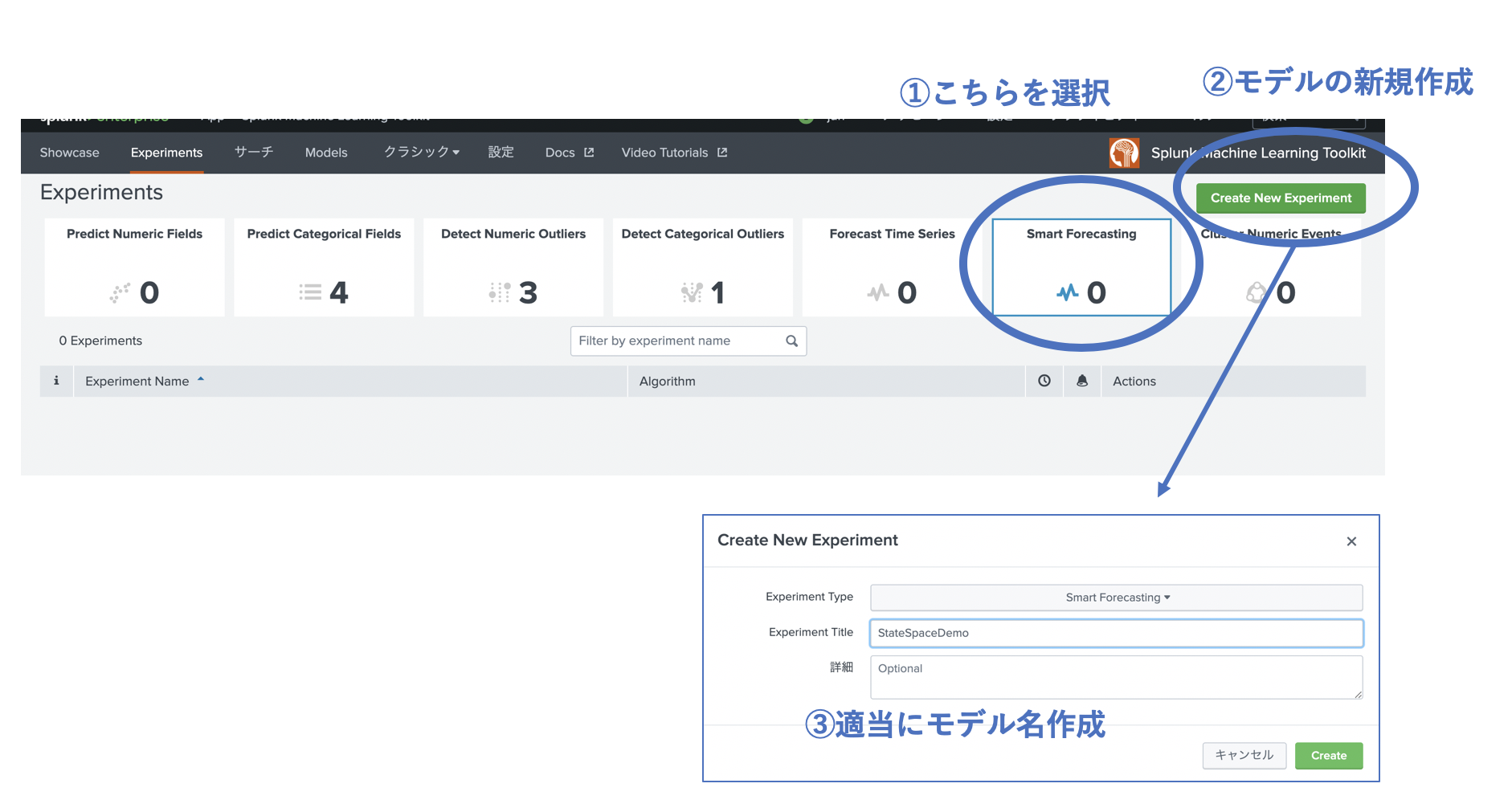
1) Define (対象データの定義)
MLTK 4.4から SmartAssistant という機能が追加されて、ステップに従って簡単に機械学習ができるようになっています。では早速新規作成して試してみましょう。
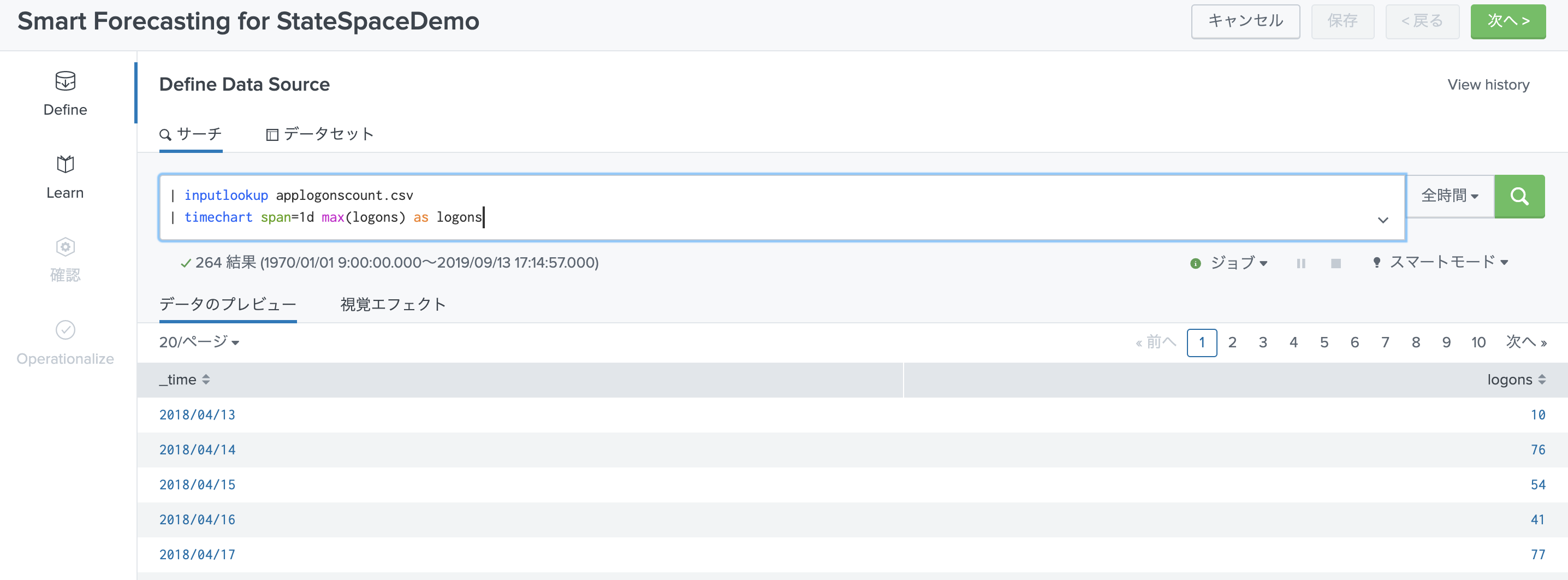
次に先ほどのデモデータを取り込みます。今回は 1日のログイン最大値(1時間あたり)に変換しておきます。
| inputlookup applogonscount.csv
| timechart span=1d max(logons) as logons
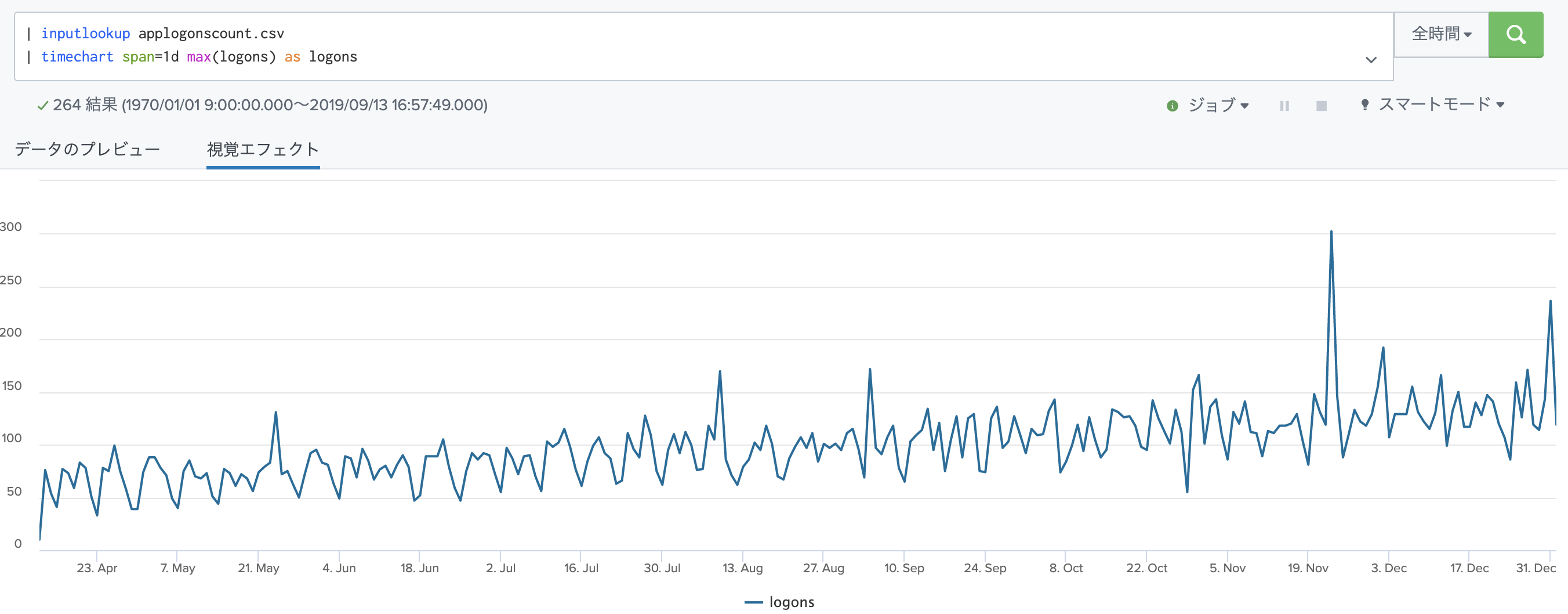
グラフによる可視化も簡単
2) 特別な日定義ファイルの取り込み
次のページに進み、特別な日(時間)を指定する (lookup内の日付と joinしている)
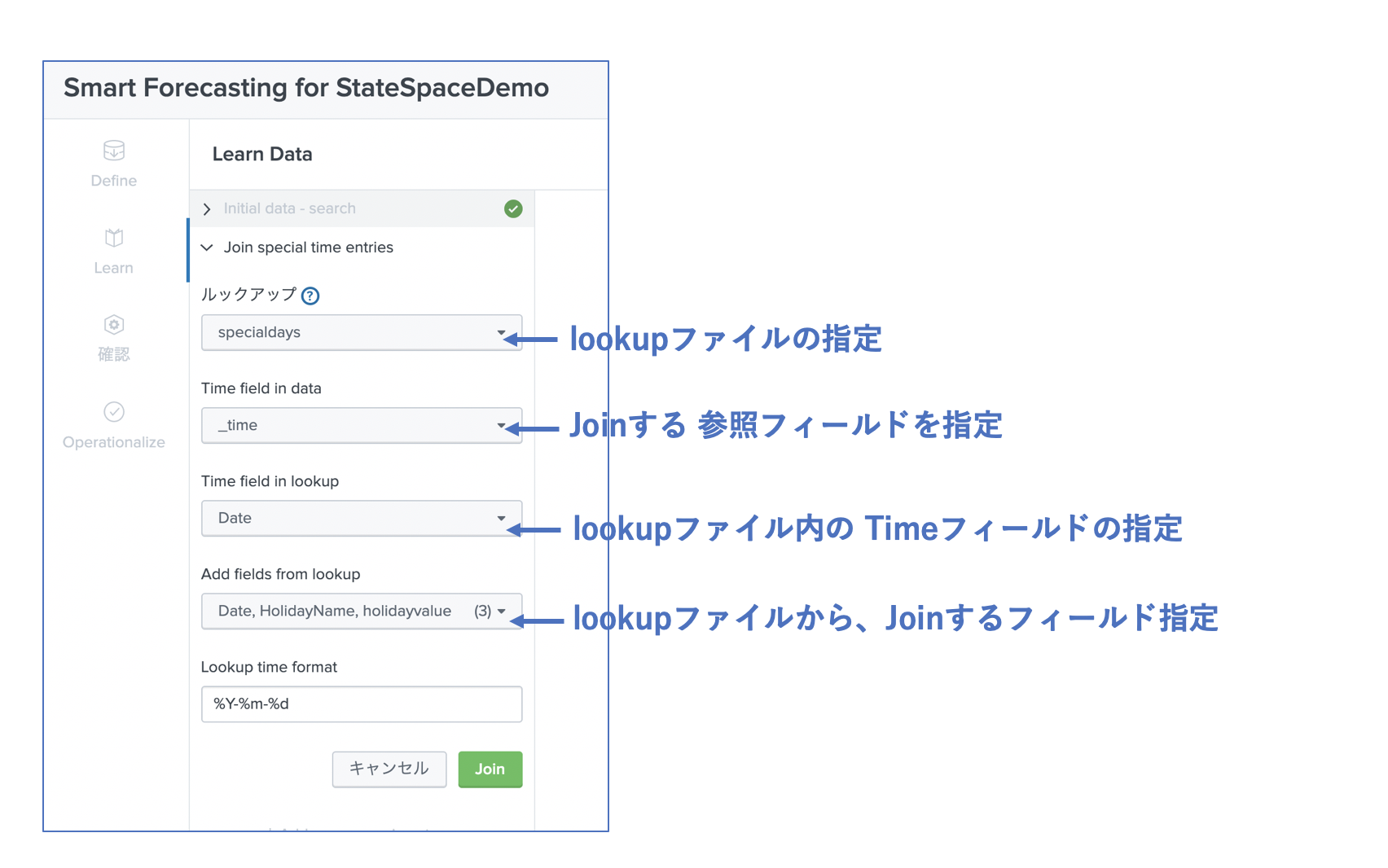
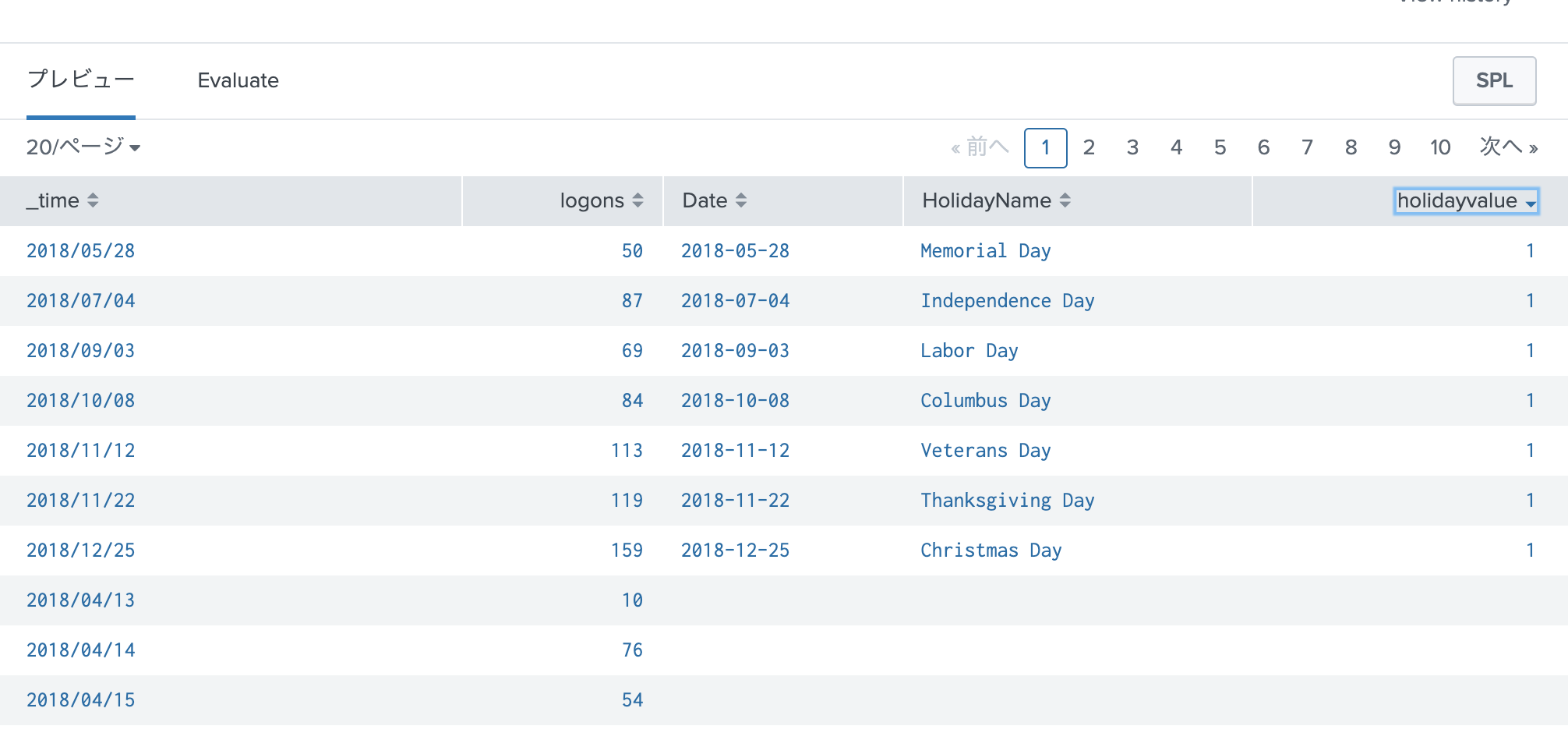
このような形で Joinされているのが確認できる。
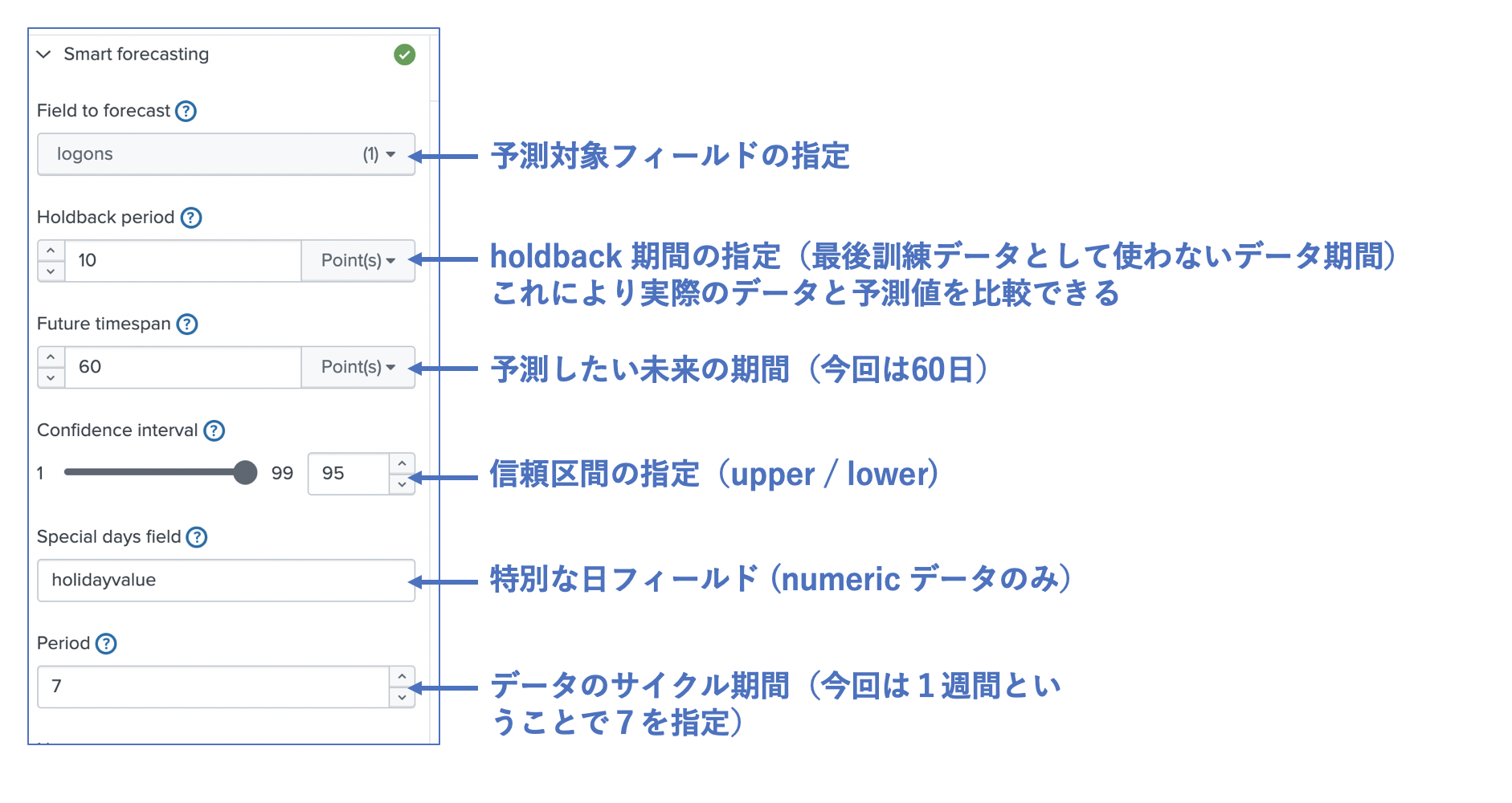
3) Learn (学習)
次に StateSpace アルゴリズムを使ったモデルを作成します。必要なパラメータを入力します。
4) レビュー
次のページに進むと、予測データと 実データの正解率(R^2)や、平均二乗誤差(RMSE)や、実際の予測値を確認できます。また予測したい日を指定するとその日の予測ログイン数が確認出来たり、閾値を設定すると、予測データが閾値を超える日にちを教えてくれます。
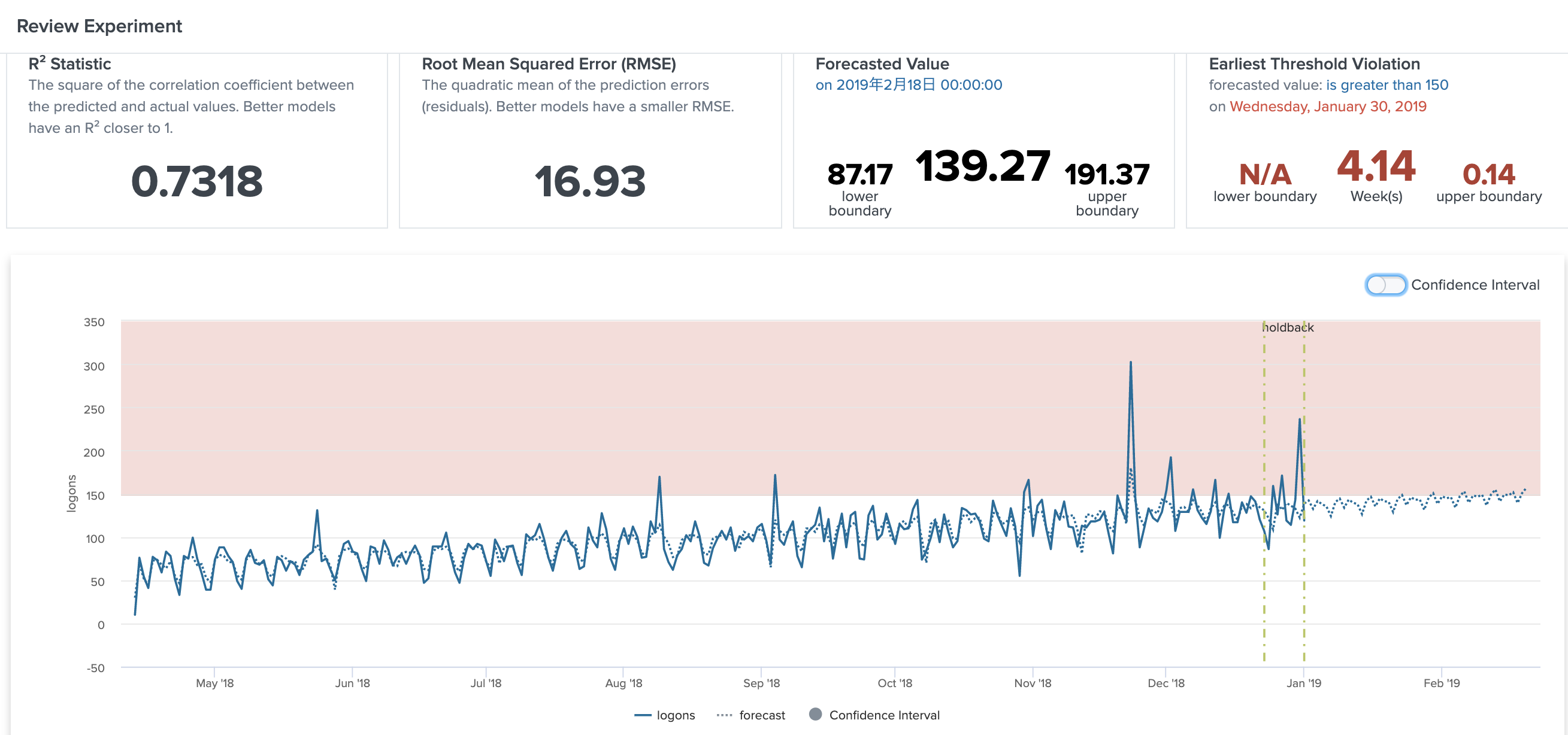
最後に、こちらのモデルで問題なければ保存します(保存ボタンがあります)
5) 運用
さらに次のページに進むと、先ほど保存したモデルを使って、スケジュール学習させたり、アラート設定したりできます。
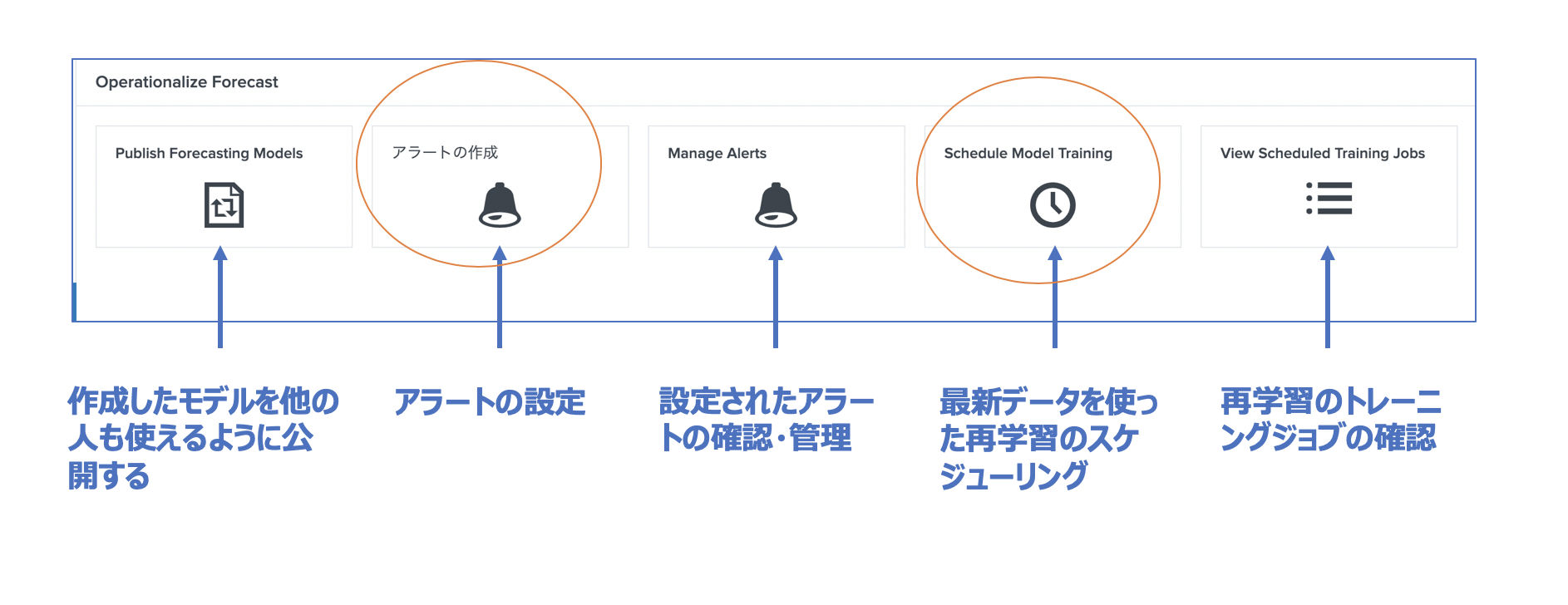
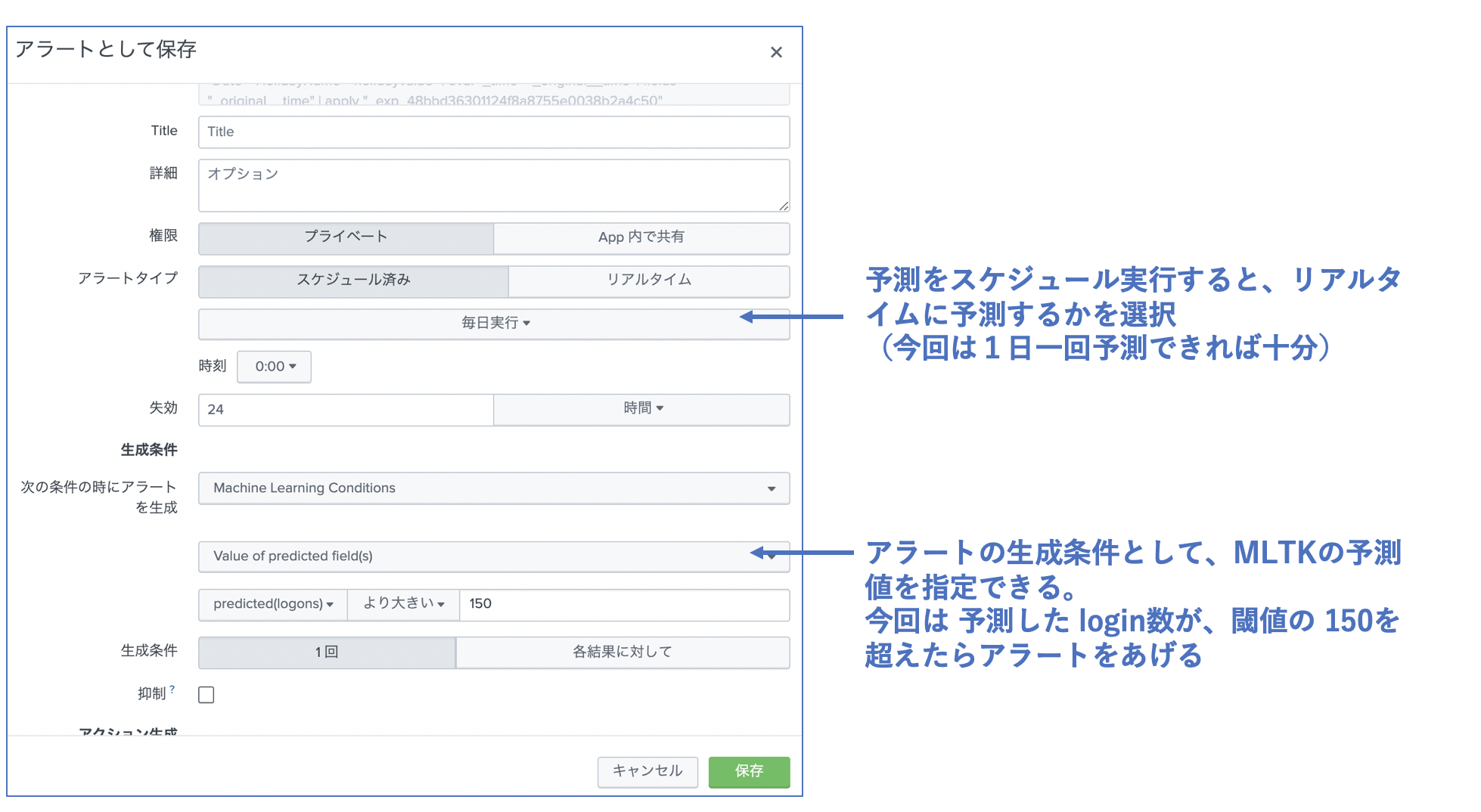
アラート設定

再学習のスケジュール設定
ログインデータは常に更新されていくので、定期的に最新のデータで予測しなおす必要があります。この再学習を自動化することができます。めちゃ便利。
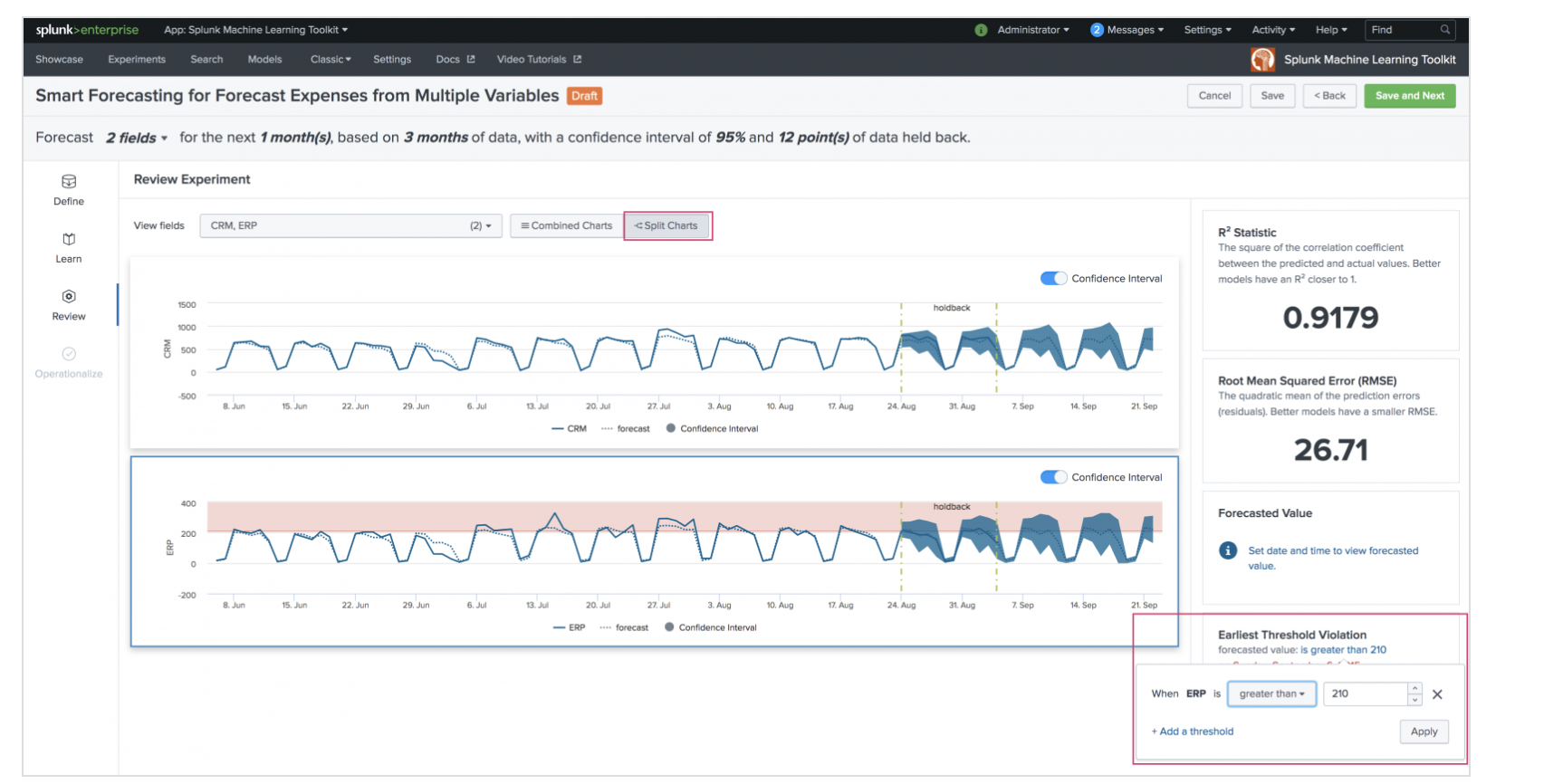
Smart Forecastintg による多変量予測
先ほどは ログイン数という一つのフィールド予測でしたが、2つ以上(最大5つまで)を同時に予測できるようです。
デモ用データもあるので、詳細はこちらをご確認ください。
増分データによる再学習 (partial_fitオプション)
再学習する際に、毎回対象データ全てで学習するとコストがかかります。Statespace アルゴリズムには、partial_fit パラメータがあり Trueにすると(defaultはFalse)過去の同じデータは学習せずに差分のみで再学習ができるという、すばらしい機能があります。
ただし、SmartAssistantでは、設定する箇所が見つからなかったので、サーチ画面で fitコマンドを実行してレポート保存&スケジュールの方法で登録する必要がありそうです。。
本当に specialdays は機能しているのか?
もとのデータだと、specialdays も他のデータとあまり差がなく本当に機能しているか分からなかったため、下記のように specialdays の日は値を1000にしてわかりやすくしました。
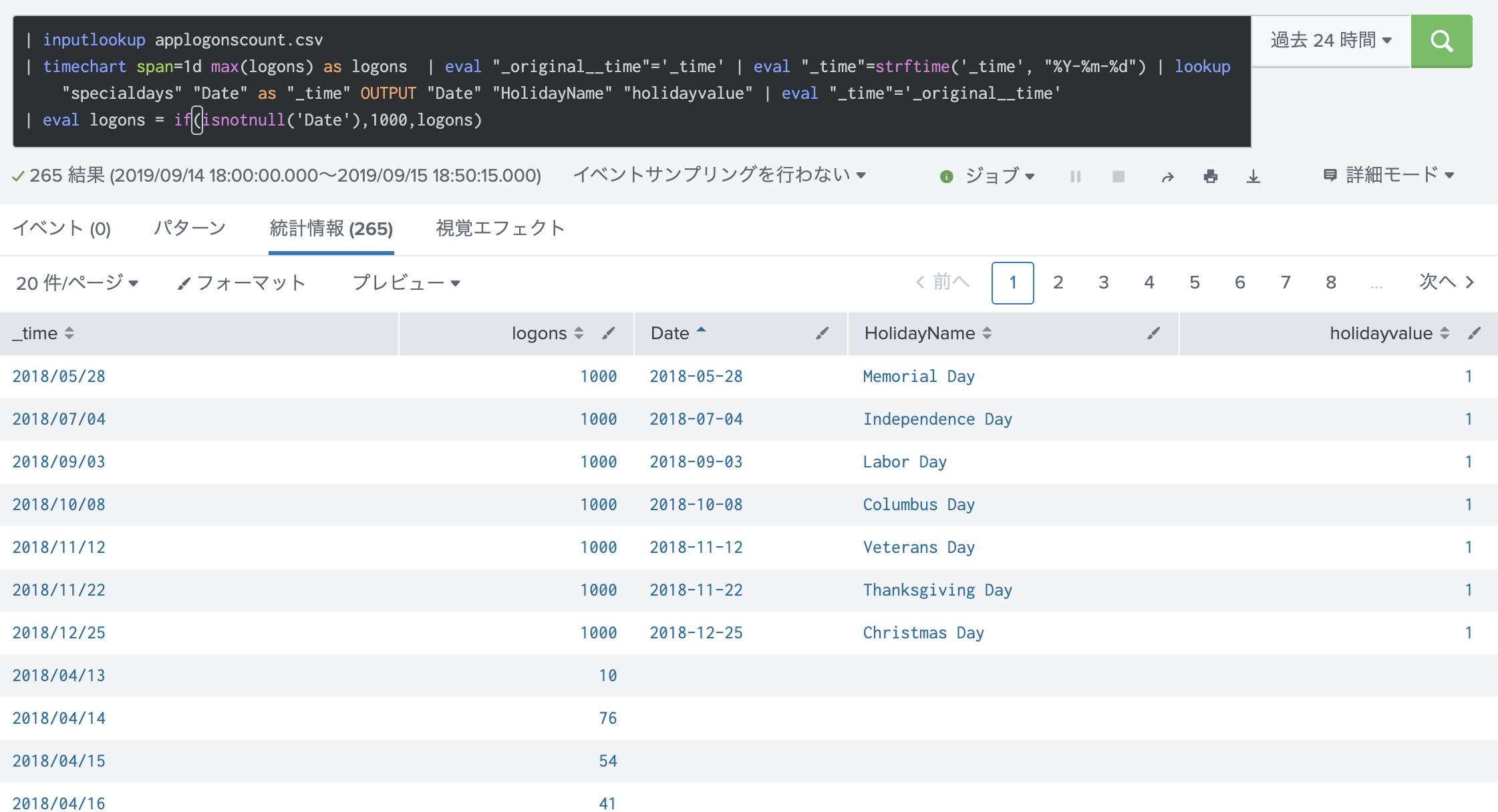
このデータで fit(学習)させたモデルを作り、applyしたいと思います。(holdbackを20として、12/25 が学習対象から外れて予測対象とします)
| inputlookup applogonscount.csv
| timechart span=1d max(logons) as logons | eval "_original__time"='_time' | eval "_time"=strftime('_time', "%Y-%m-%d") | lookup "specialdays" "Date" as "_time" OUTPUT "Date" "holidayvalue" | eval "_time"='_original__time'
| eval logons = if(isnotnull('Date'),1000,logons)
| apply myStateModel specialdays=holidayvalue holdback=20 forecast_k=50
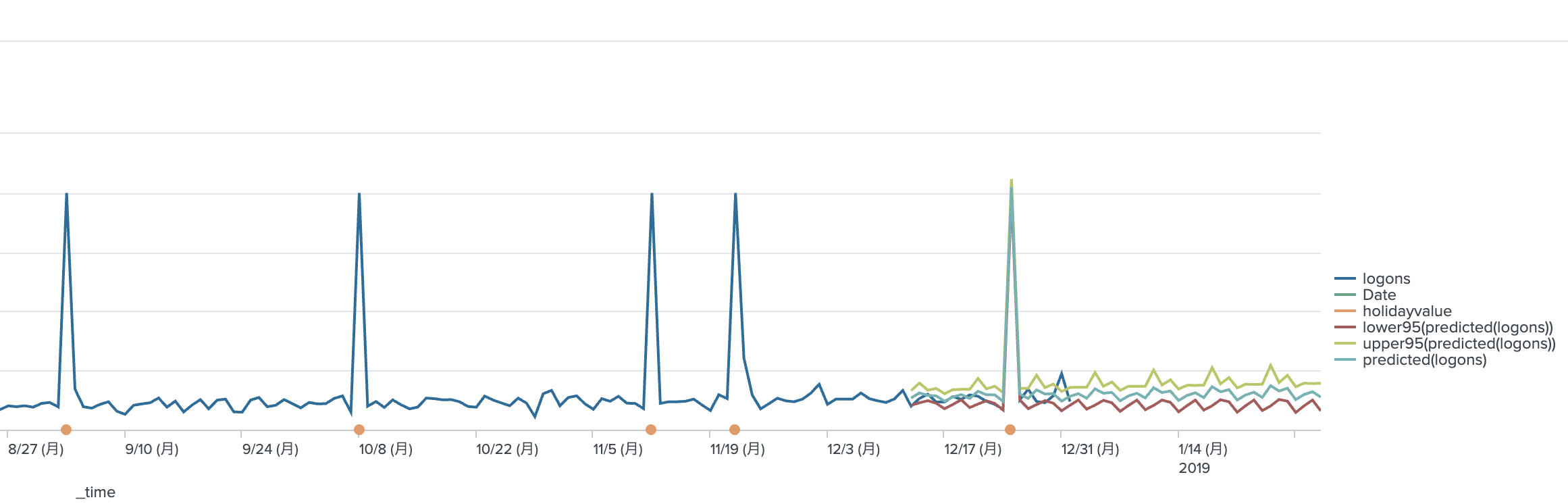
オレンジの●が付いている箇所が holidayであり、 12/13 から50日の予測をしております。見事に 12/25の holiday時には他のデータと同様に高い値になっており、次の日から通常の値になっておりました。ちゃんと機能しているようです。
Tips
最後に予測精度を高めるためのTipsです。学習データに外れ値が含まれていると、予測精度にも影響してしまいます。明らかにおかしいデータは学習させる前に取り除いておきましょう。
また、あまり遠い未来の予測をすると、信頼区間も大きくなってしまい、あまり意味のある予測ではなくなってしまうため、短めが良さそうです。
最後に
Splunkには元々 predict コマンドがありましたが(forecastコマンドに名前変更した方が良さそうだが・・)、Statespaceの方がより正確に予測出来ているように見えます。またspecialdaysも lookupを使わなくても numericなフィールドがあれば指定できたので、結構簡単に利用できそうです。これからはこちらを利用しようっと。
参考資料
Splunk SmartAssistant (SmartForecast) マニュアル
https://docs.splunk.com/Documentation/MLApp/4.4.1/User/SmartForecastingAssistant#Smart_Forecasting_Assistant_Showcase
Blog
https://www.splunk.com/blog/2019/03/20/what-s-new-in-the-splunk-machine-learning-toolkit-4-2.html
StateSpace アルゴリズム
https://docs.splunk.com/Documentation/MLApp/4.4.1/User/Algorithms#StateSpaceForecast