はじめに
Splunk の機械学習機能で NLP(Natural Language Processing) Text AnalyticsというApp があり、感情分析できるのですが、残念ながら日本語対応していない・・・
また、DLTK (Deep Learning Toolkit)を使うと自然言語処理などができるので、LSTMなどを使って感情分析などの機能実装も可能なのですが、大量のデータを集めたり、Deep Learningのコード実装が必要だったりしてハードルが高い・・・
感情辞書を用いた方法も精度を高めるには苦労しそうだなー・・・
と思っていたところ、Google Natural Language を使うとできるよという話を教えてもらいました。
すでに日本語での大量の学習済みモデルを使えるので、精度も高そうだし、APIで提供されているので実装も簡単そう。
ということで、Splunkにあるデータを使って、Google Natrual Language APIで感情分析させて、Splunkのダッシュボードで結果を表示させてみました。
実装概要イメージ
今回実装した方法は以下のようなイメージです。
将来的にはAppを作成するのも面白そうですが、一旦以下のように実装しました。
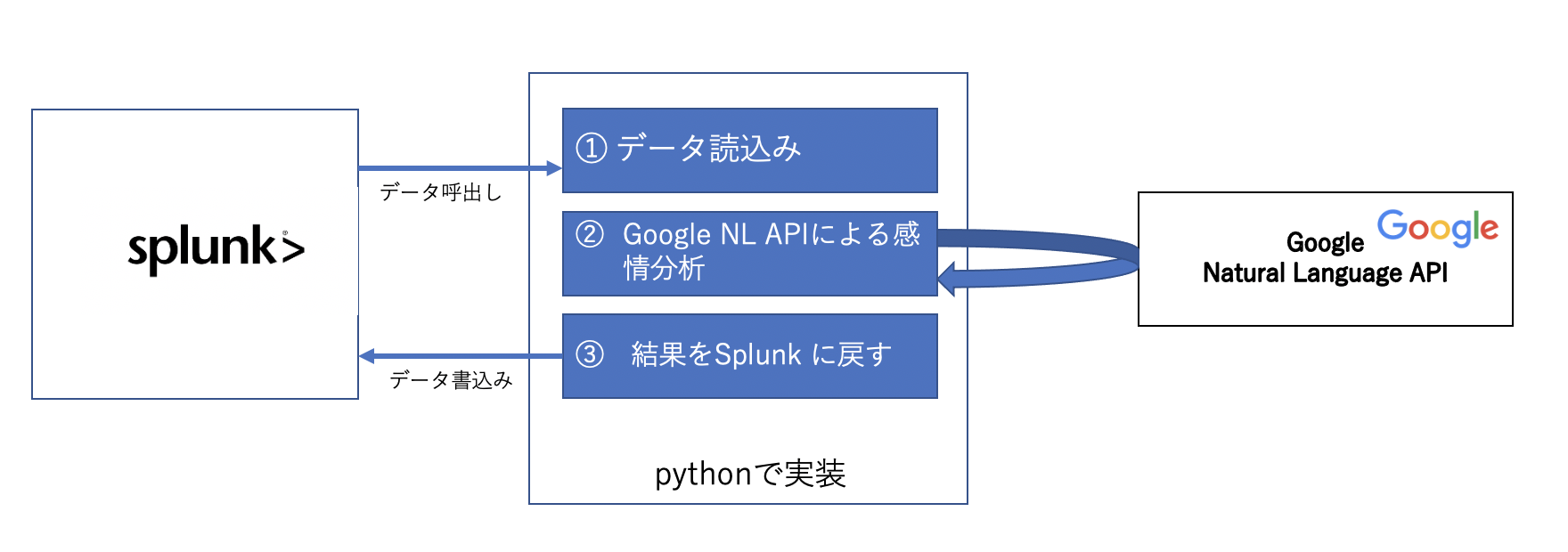
Step 1. データ読み込み
PythonでのSplunkデータの取り込み方法については、以前記事を書いているので、ここでは詳細は割愛させていただきます。
Pyhton コードで Splunk サーチ結果を読み込む (RestAPI編)
https://qiita.com/maroon/items/178a0c1263575597eea8
今回は、以下のように取得したデータを DataFrame形式にしております。こちらの comment 列の内容をGoogle NL APIを使って感情分析をさせたいと思います。

Step 2. Google NLP API による感情分析
この機能を利用するためには、いくつか準備が必要です。
Google Cloud Natural Language APIのクイックガイドがあるので、こちらに従って設定するのがいいかと思いますが、Cloud SDKを入れるため、Google Collaboratory などのWeb上の開発ツールだとうまく実行できなかったため、今回はこちらのDeveloper's Blog様の記事にあるAPI token実装による方法を採用しました。
Google Cloud 側の設定は途中までクイックガイドにある方法と同じですGoogle Cloud設定
設定手順
- プロジェクト作成
- 課金の有効化 (5000件/月までは無料枠あり)
- Google Natural Language APIの有効化
- サービスアカウント作成
- APIキーの発行
上記のAPIが利用できるようになったら、次にコード実装をします。
取得したAPIキーを以下の access_token の箇所に入力ください。
# 感情分析の関数設定
import sys
import requests
def check_sentiment(content):
access_token = "<<API Key>>" # API key
url = 'https://language.googleapis.com/v1/documents:analyzeSentiment?key={}'.format(access_token)
header = {'Content-Type': 'application/json'}
body = {
"document": {
"type": "PLAIN_TEXT",
"language": "JA",
"content": content
},
"encodingType": "UTF8"
}
response = requests.post(url, headers=header, json=body).json()
return response
Splunkから取得したデータを データフレームとして格納したため、以下のように、一件ごとループで上記の check_sentimentを実行していきます。
# 感情分析を実行する
magnitude = pd.Series(name='magnitude')
score = pd.Series(name='score')
gcp_output = pd.DataFrame()
for j in range(len(df)):
output = check_sentiment(df['comment'][j])
magnitude.loc[j] = output['documentSentiment']['magnitude']
score.loc[j] = output['documentSentiment']['score']
gcp_output = pd.concat([df,magnitude,score],axis=1)

これで、それぞれのコメント毎に score と magnitude という結果が返ってきました。それぞれの意味についてはこちらをご覧ください。感情分析結果の値の解釈
Score : -1 から 1までの範囲で、1 に近いとポジティブ。 -1 に近いとネガティブとなります。 0に近いのはニュートラルもしくは、混在しているケースで、その場合 magnitudeを見て 0に近いとニュートラルだけど、数字が大きいと混在している可能性が高い。とのことです。
Step 3. Splunk に結果を返す。
RestAPIと HECを使って、Splunkにデータを取り込ませる方法については、こちらに別途記事が書いてありますので、ここでは割愛させていただきます。
[pythonでデータを Splunkに取り込む ( RestAPI + HECの組み合わせ)]
(https://qiita.com/maroon/items/66e92399f00800d5f069)
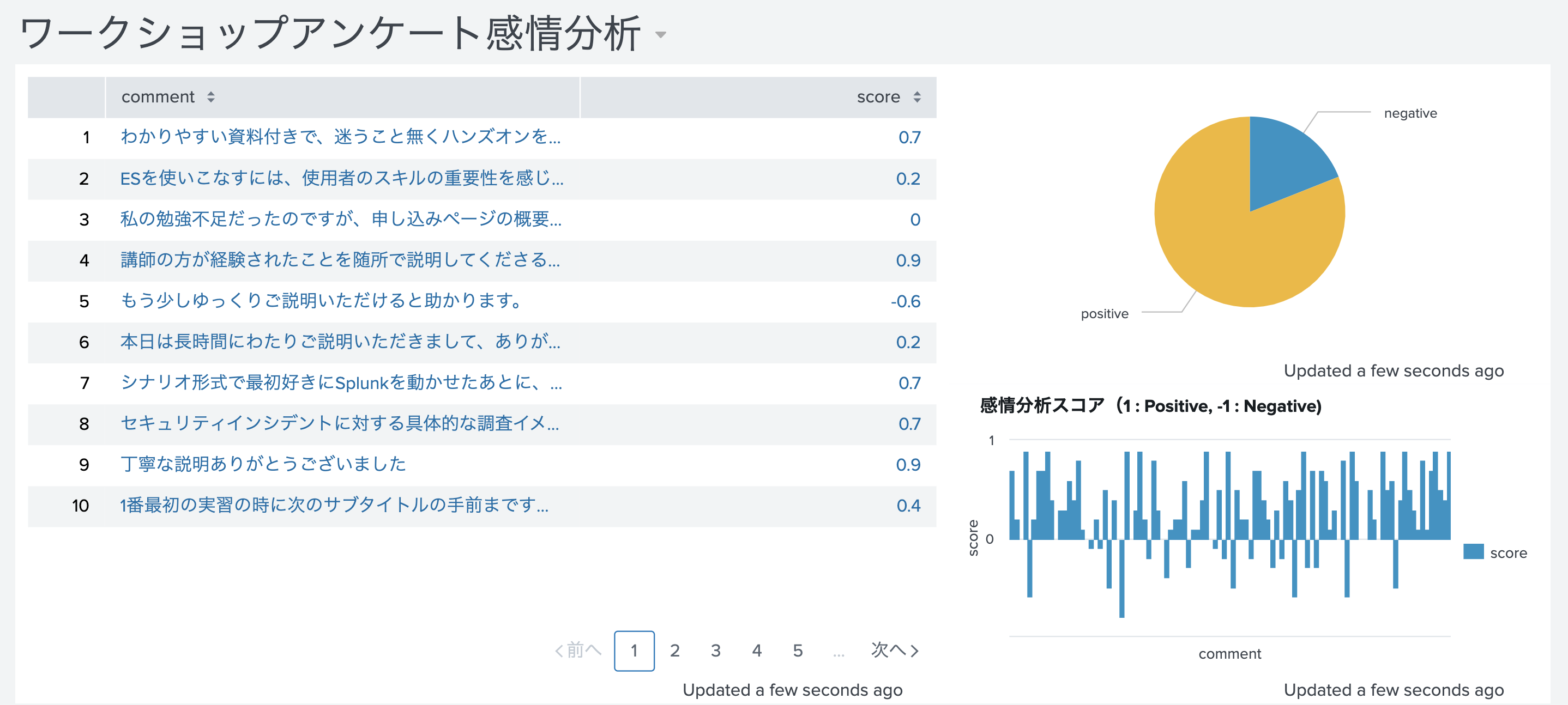
Step 4. Splunk上で分析・可視化する
従来のデータに感情分析結果が付与されたため、今まで出来なかったような分析ができるようになりました。これはデータ分析を進めていく上で非常にありがたい情報ですね。
最後に
日本語の自然言語処理って1から作ると大変ですが、このようなサービスを利用できるのは本当にありがたいですね。また、このGoogle Natural Languageのすごいところは、文章のままで感情分析をしてくれるというところです。単語ではないので、日本語の難しい言い回しや、最後に否定がきてもちゃんと意味理解をしてくれるし、かなり精度も高いように感じました。
ちなみに、5000件/月までは無料枠なので、感情分析はこの機能を利用して、他の自然言語処理(構文解析,エンティティ分析、形態素解析)などはSplunk のDLTKにある spacy (ginza) を使うといいのかなと思います。