はじめに
SplunkのMLTK(Machine Learning Tool Kit) の中には、アルゴリズムだけでなく便利なチャートも含まれており、その一つの Outlier Chartが、外れ値を可視化するのに便利だったのでご紹介したいと思います。外れ値は異常検知の有効な手段なので、活用の機会は多くあるのではないでしょうか。
最終的な可視化イメージとしては、以下の図ように閾値である上限と下限が水色で囲まれて、それを逸脱しているものを外れ値として検知して教えてくれます。
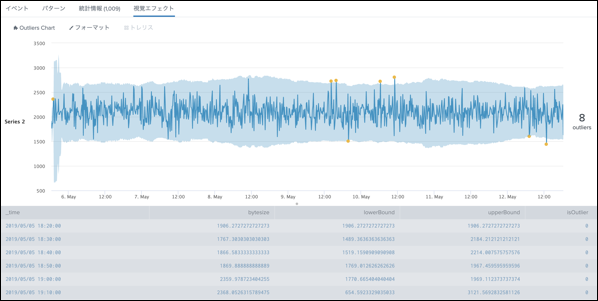
Outlier Chart の使い方
まずは、MLTKをSplunkに追加してください。(追加方法についてはここでは省略します)
これで視覚エフェクトで選択することができます。
chart を使うためにデータを下記のように加工します。
|table _time, <outlier_variable>, <lower_bound>, <upper_bound>
timechart との組み合わせが便利です。 <outlier_variable> が、<lower_bound>よりも下か、<upper_bound>よりも上の場合、外れ値として検出して表示してくれます。
異常値閾値 (lower_bound , upper_bound) の求め方
統計手法等を使って閾値を設定する方法はいくつかあります。それぞれ簡単にみてみます。
1)固定値(シンプルに固定の閾値を設定)
2)標準偏差を使った閾値
3)中央絶対偏差を使った閾値
4)IQR (四分位範囲)を使った閾値
ちなみに今回のデータは異常検知としては意味のないデータなので、そこは突っ込まずに手法だけ見てください。
1) 固定値による閾値
こちらは簡単です。グラフをみて単純に上限・下限を決めるだけです。伝統的な監視手法は、ほとんどがこの方法ではないでしょうか?(例:CPU使用率が 90% を超えたらアラート。など)
閾値はグラフをみて決めるか、経験値などを頼りに思い切って決める必要があります。
index=tutorial sourcetype=access*
| timechart span=10m avg(bytes) as bytesize
| eval lowerBound=1500
| eval upperBound=2500
| fields _time, "bytesize", lowerBound, upperBound
2) 標準偏差を使った閾値
標準偏差をとり、平均値 ± 標準偏差 x (value) を閾値とする方法です。 (value) の部分は自分たちで決める必要があります。偏差値でいうと、value=2 にすると偏差値 70 or 30 に相当します。value=3 にすると、偏差値 80 or 20 に相当します。
index=tutorial sourcetype=access*
| timechart span=10m avg(bytes) as bytesize
| join
[ search index=tutorial sourcetype=access*
| timechart span=10m avg(bytes) as bytesize
| stats avg("bytesize") as avgbyte , stdev("bytesize") as std]
| eval value=3
| eval lowerBound=(avgbyte - std*value)
| eval upperBound=(avgbyte + std*value)
| table _time, "bytesize", lowerBound, upperBound
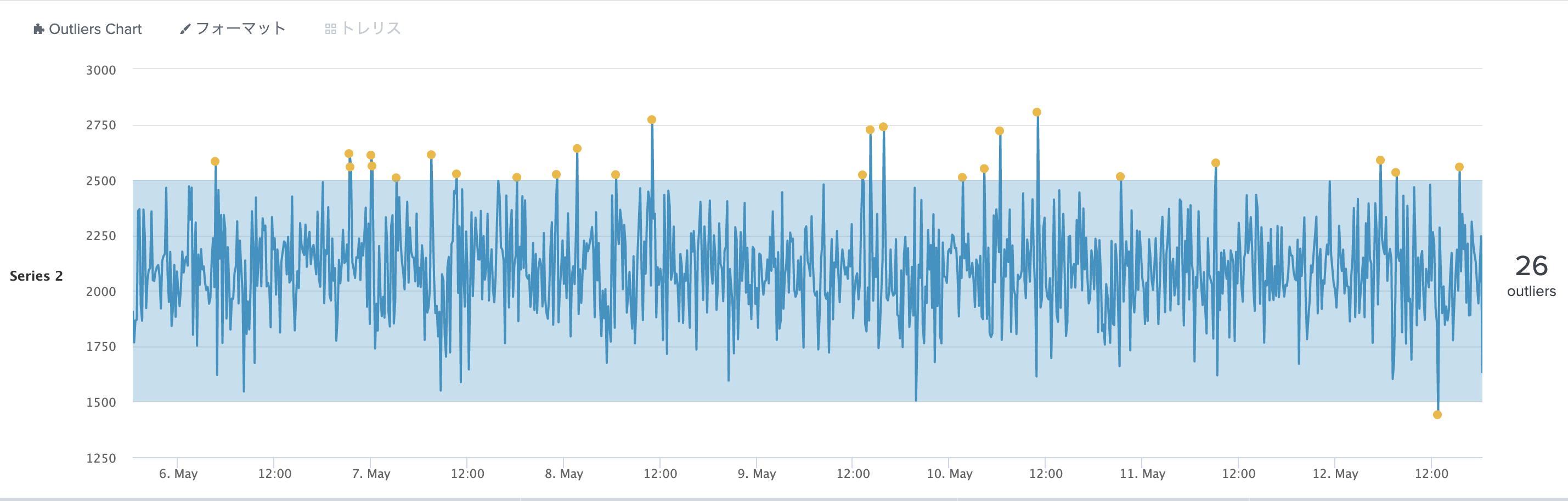
今回は標準偏差と平均値を全体から算出しました。(サブサーチで計算して、joinしてます)valueを3にして外れ値を算出しております。
また固定値と違い計算しながら閾値を設定できるため、この方法を streamstats を組み合わせて計算する範囲をスライドしながら標準偏差と平均を求めて、それをもとに動的な閾値を設定してみます。
index=tutorial sourcetype=access*
| timechart span=10m avg(bytes) as bytesize
| streamstats window=200 current=t stdev("bytesize") as std, avg("bytesize") as avgbyte
| eval value=3
| eval lowerBound=(avgbyte - std*value)
| eval upperBound=(avgbyte + std*value)
| table _time, "bytesize", lowerBound, upperBound
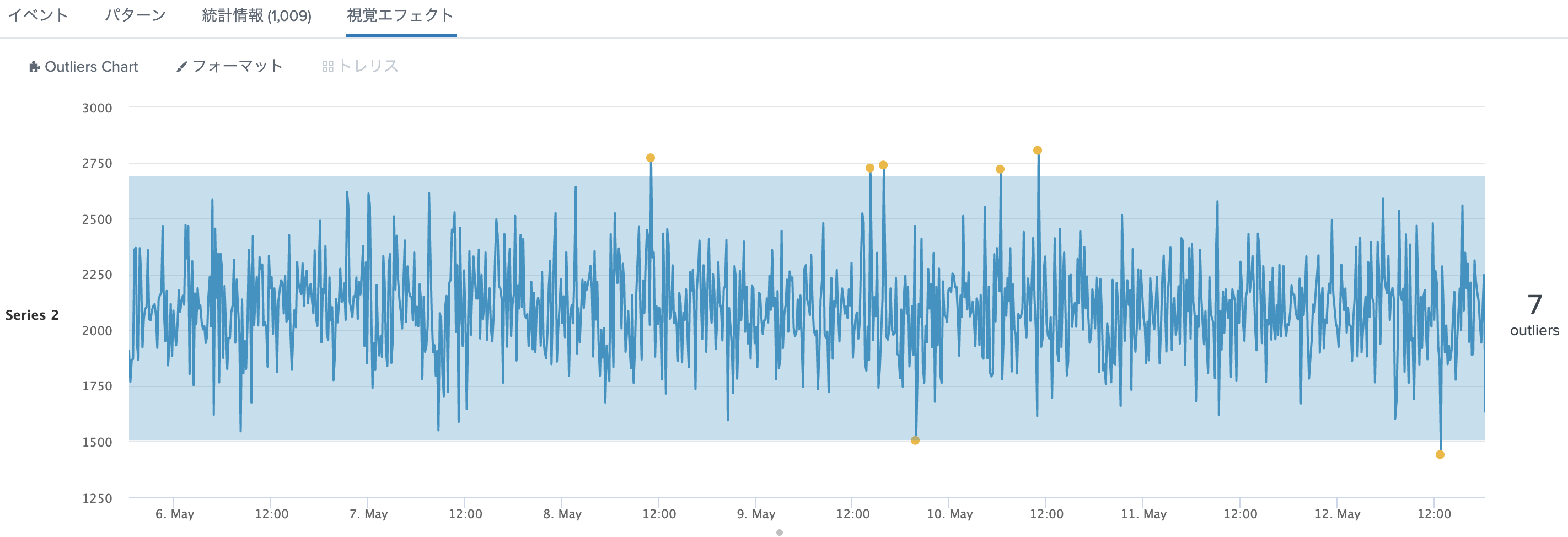
データが正規分布に従っていると仮定することが前提となります。
3) 中央絶対偏差を使った閾値
- の標準偏差を使った閾値の問題は、外れ値の値が大きすぎたり小さすぎたりすると平均値や標準偏差に大きく影響を与えてしまいます。streamstats でスライドした場合はさらにプロット数が小さいため影響を受けやすいです。それにより問題のあるポイントを見逃してしまう可能性があります。年収などの例だとわかりやすいかと思いますが、高年収の人がいると、平均値をあげてしまうので正しく評価できないなどのケースです。
そこで、外れ値の値にあまり影響を受けない方法として、中央値を使った方法があります。
ここでは全体の中央値と中央値と実際の値の差分を並べてさらに差分中央値をとり、それにValueをかけて閾値を設定する方法をご紹介します。
ちょっとわかりづらいかと思いますが、2)のケースと比較すると平均が中央値に代わり、標準偏差が中央絶対偏差に代わります。
今回は最初から streamstats を使って分析してみます。中央値をとるためのコマンドと、中央絶対偏差の中央値をとるためのコマンドがあるので、ちょっと複雑に見えるかもしれませんがあしからず。今回は valueを3にしてますが、この値は人が決める必要があります。
index=tutorial sourcetype=access*
| timechart span=10m avg(bytes) as bytesize
| streamstats window=200 current=t median("bytesize") as median ## 中央値
| eval absDev=(abs('bytesize' - median)) ## 絶対偏差
| streamstats window=200 current=t median(absDev) as medianAbsDev ## 中央絶対偏差
| eval value=3
| eval lowerBound=(median - medianAbsDev*value)
| eval upperBound=(median + medianAbsDev*value)
| table _time, "bytesize", lowerBound, upperBound
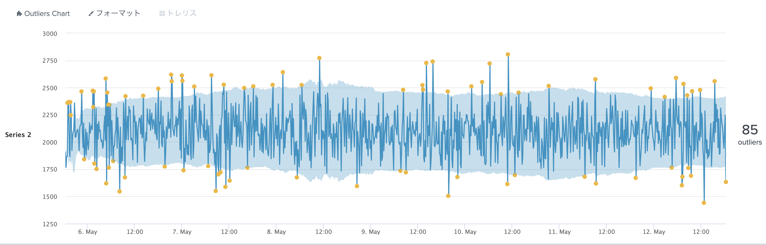
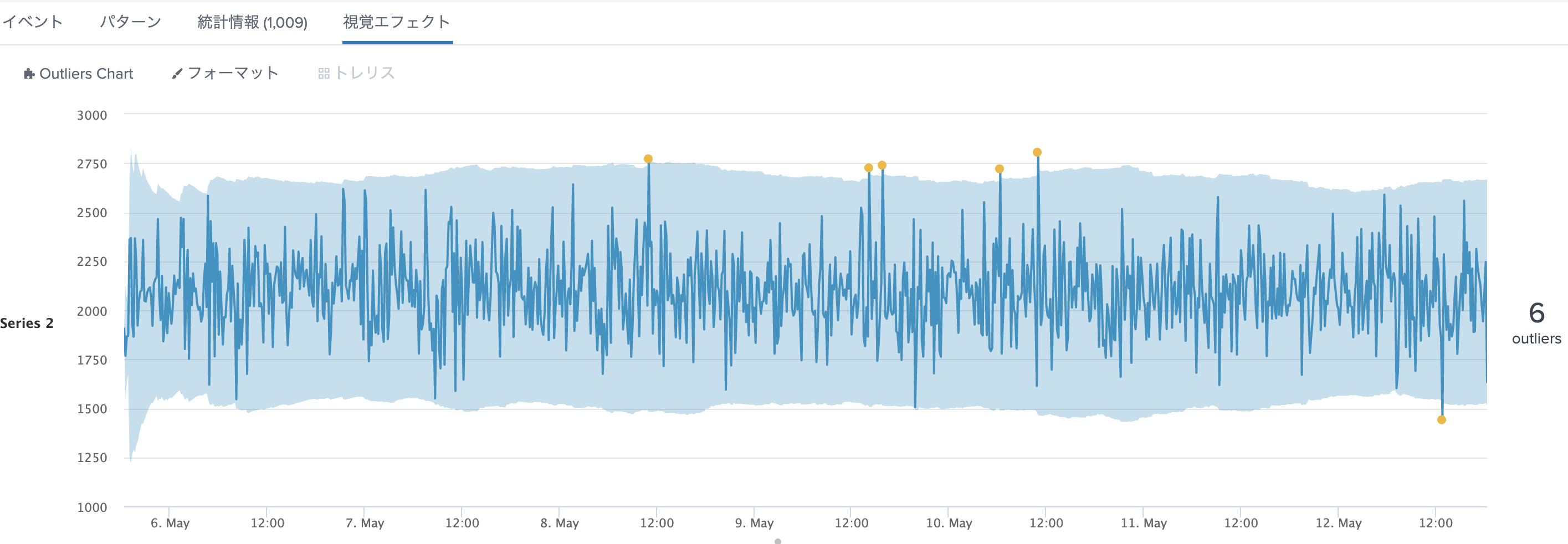
正しいかは別として、標準偏差の方法よりも多くの外れ値を検出できました。
4) IQR (四分位範囲)を使った閾値
最後に IQR (四分位範囲)を使った閾値設定についてです。IQRは箱ひげグラフとして有名です。
詳細はこちらの統計WEBのサイトを参照ください。今回は、IQRを使った閾値設定方法について記述します。
Splunkでは、 四分位の perc25, perc75 など指定したパーセンタイルを簡単に求めることができます。
また、IQR の値は、perc75 - perc25 で求めることができます。
valueは同じように、人が決める必要があります。
index=tutorial sourcetype=access*
| timechart span=10m avg(bytes) as bytesize
| streamstats window=200 current=t median("bytesize") as median, p25("bytesize") as p25, p75("bytesize") as p75
| eval IQR = (p75-p25)
| eval value=2
| eval lowerBound=(p25 - IQR*value)
| eval upperBound=(p75 + IQR*value)
| table _time, "bytesize", lowerBound, upperBound
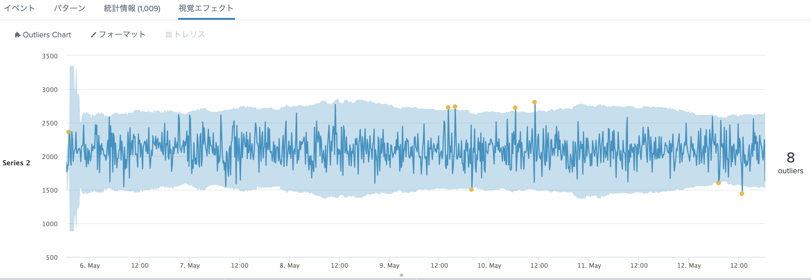
最後に
どの閾値を使うべきかは、それぞれの特徴をもう少し勉強する必要がありますが、統計手法による外れ値の求め方や可視化は少しわかりました。これを常時モニタリングすれば単純な固定値による閾値よりも有用な問題を検出できるかも(?)
最後に Outlier Chartでは、グラフの中では外れ値を表示してカウントしてくれますが、実際に運用の中でアラートをあげるためには、外れ値のフィールドを明確に設定しておく必要があります。そのため少しSPLを修正して、外れ値が検出されたかどうかを判断できるように以下のコマンドを追加してみます。
| eval isOutlier=if('bytesize' < lowerBound OR 'bytesize' > upperBound, 1, 0)
これを今までのSPLに追加することで、isOutlierフィールドが追加されて、外れ値が検出された場合は 1がセットされます。
index=tutorial sourcetype=access*
| timechart span=10m avg(bytes) as bytesize
| streamstats window=200 current=t median("bytesize") as median, p25("bytesize") as p25, p75("bytesize") as p75
| eval IQR = (p75-p25)
| eval value=2
| eval lowerBound=(p25 - IQR*value)
| eval upperBound=(p75 + IQR*value)
| eval isOutlier=if('bytesize' < lowerBound OR 'bytesize' > upperBound, 1, 0)
| table _time, "bytesize", lowerBound, upperBound ,isOutlier
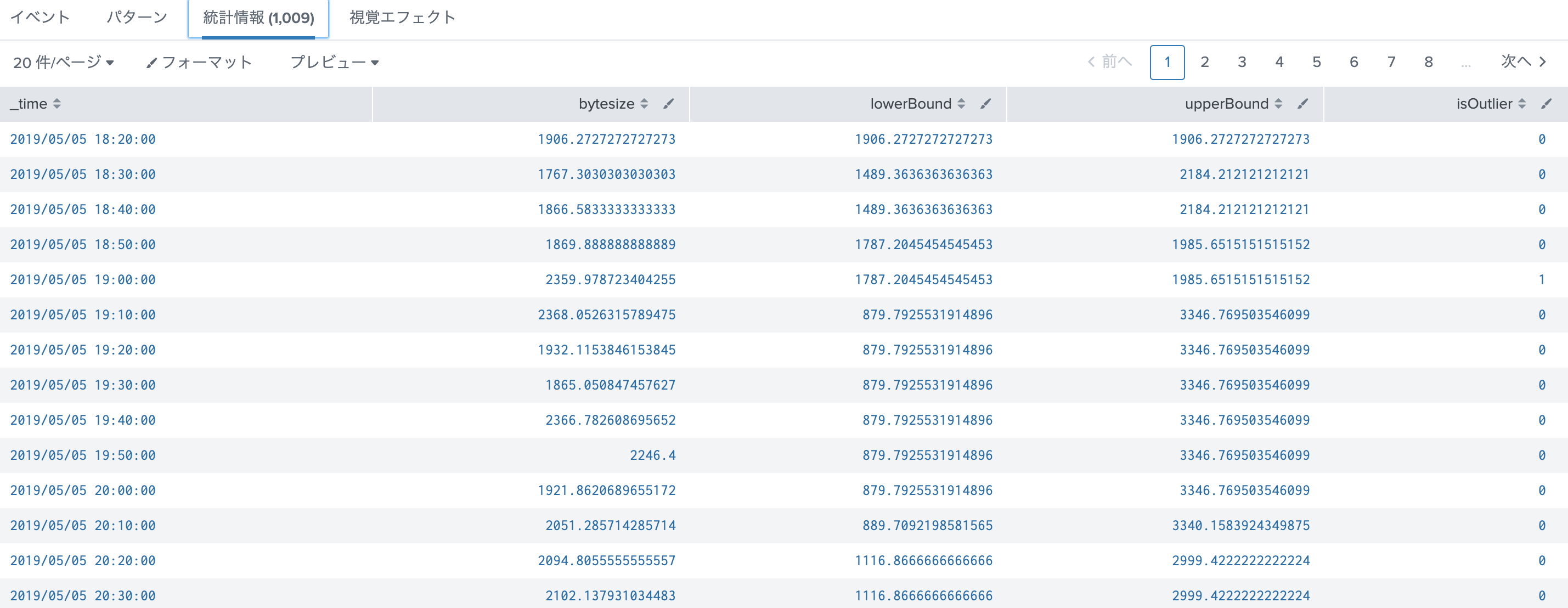
### 実は・・・
最後に、実はこれらのやり方は MLTKを使えば、GUIを使って簡単に実行することができます。(固定閾値はありませんが)しかも、streamstats を使ったスライド指定もできます。 valueの値がここでは threashold multiplierで指定できます。なんと便利なんでしょう。
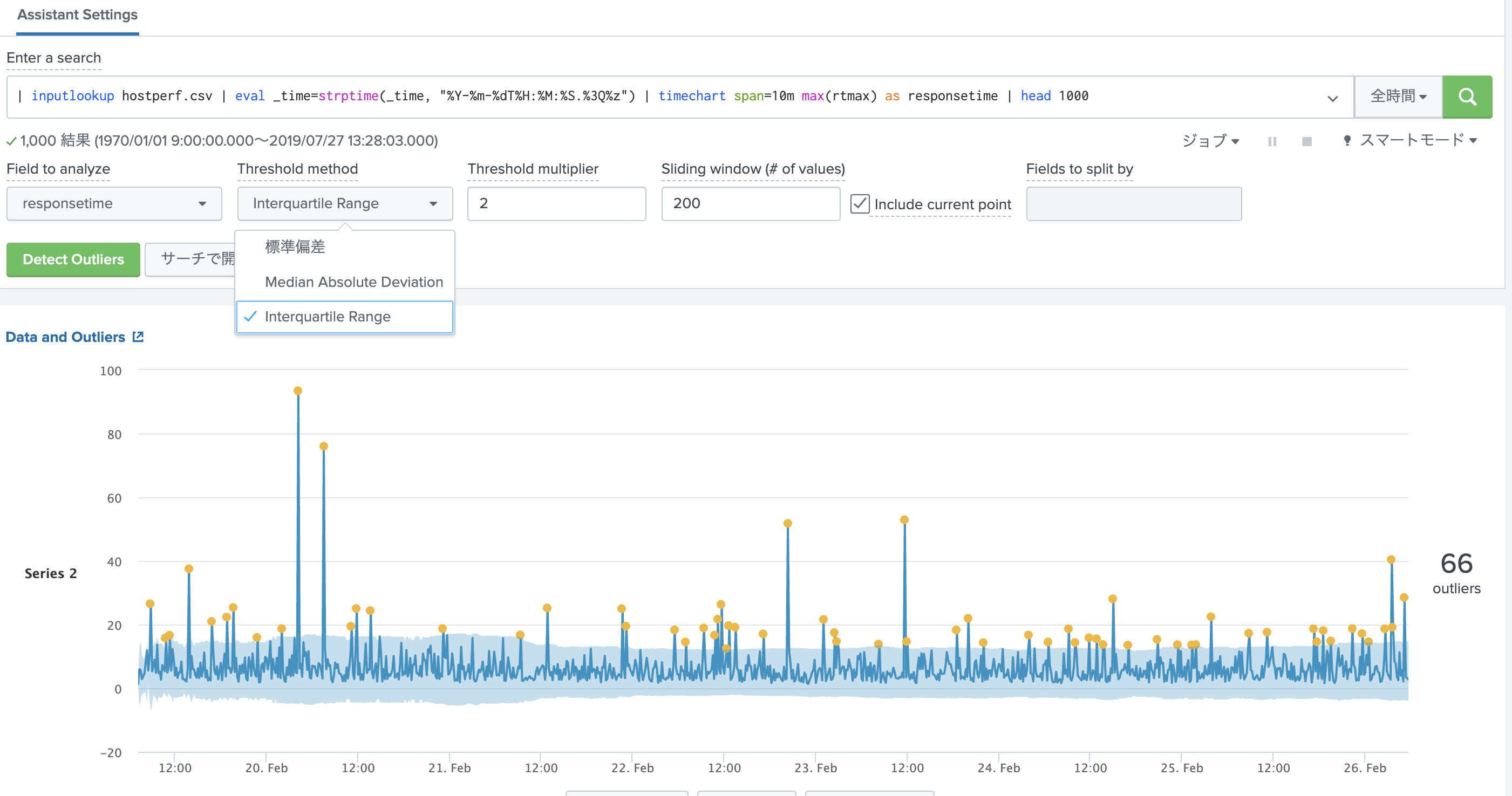
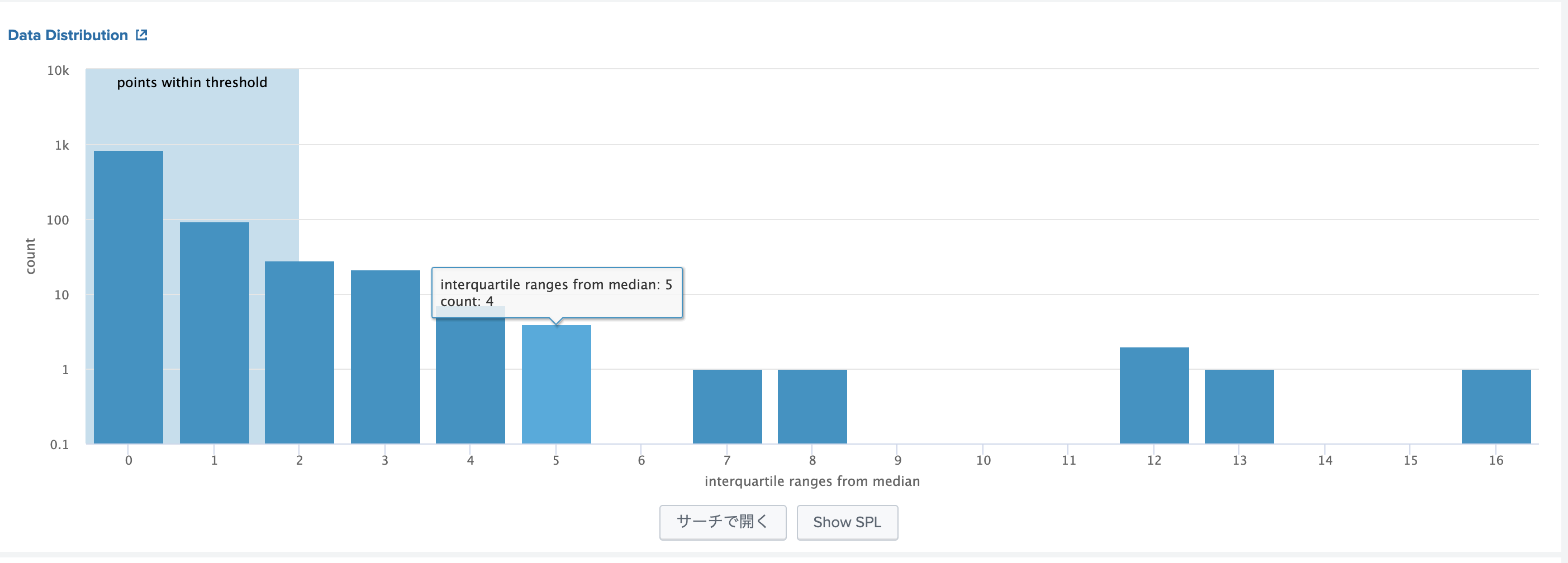
しかも、下記のようにvalueの値をbinとして、ヒストグラムを作成してくれるので、人が決めないといけないvalueをどれにセットすると、どのくらい外れ値が出るかが一目でわかります。
MLTKにはこのような機械学習や統計手法を使ったアルゴリズムがたくさん詰まってますので、今後も試してみたいと思います。