追記 (2019/10/25)
MLTK5 がリリースされたことにより、こちらの実装がGUIベースで可能になりました。
詳細はこちらをチェックしてください。
Splunk MLTK Smart Outlier Detection Assistant について
目的
Splunk MLTK 4.2 から、新しいアルゴリズムとして Density Function が追加されました。機械学習を使って確率密度ベースによる異常検知ができるというもので、教師なし学習でモデルが作れます。しかも確率密度推定に使われる確率分布として、正規分布・指数分布以外にもカーネル密度推定(Gaussian)が利用できるということで、今までよりも複雑なデータ分布にも対応することができるようになりました。
異常検知までのフローとしては、以下のようなイメージです。過去のデータを元にモデル(確率密度推定)を作り、異常と判定される範囲を決めます(upperとlower)。 そして本番データに適用する事で upperとlowerに入らない値を異常値として検出されるというものです。
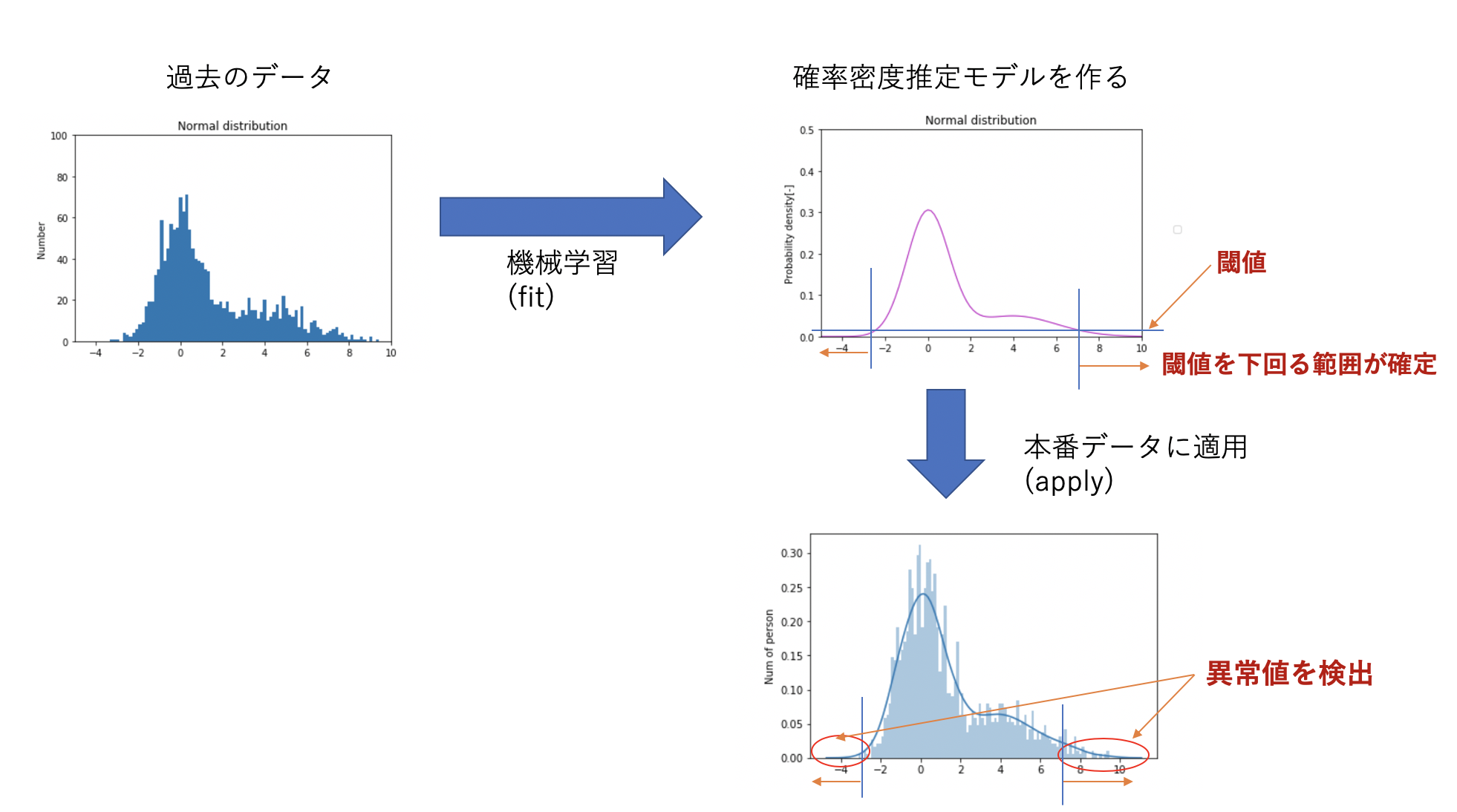
確率密度推定とはなんぞや? ガウスカーネルとはなんぞや? というのは一旦後回しにして、まずは使ってみましょう。
1)前提条件
・ MLTK 4.3 以降を Splunkに追加
・ 機械学習による予測のため、十分なデータセットを用意(最低50以上のデータポイント)
2) サンプルデータについて
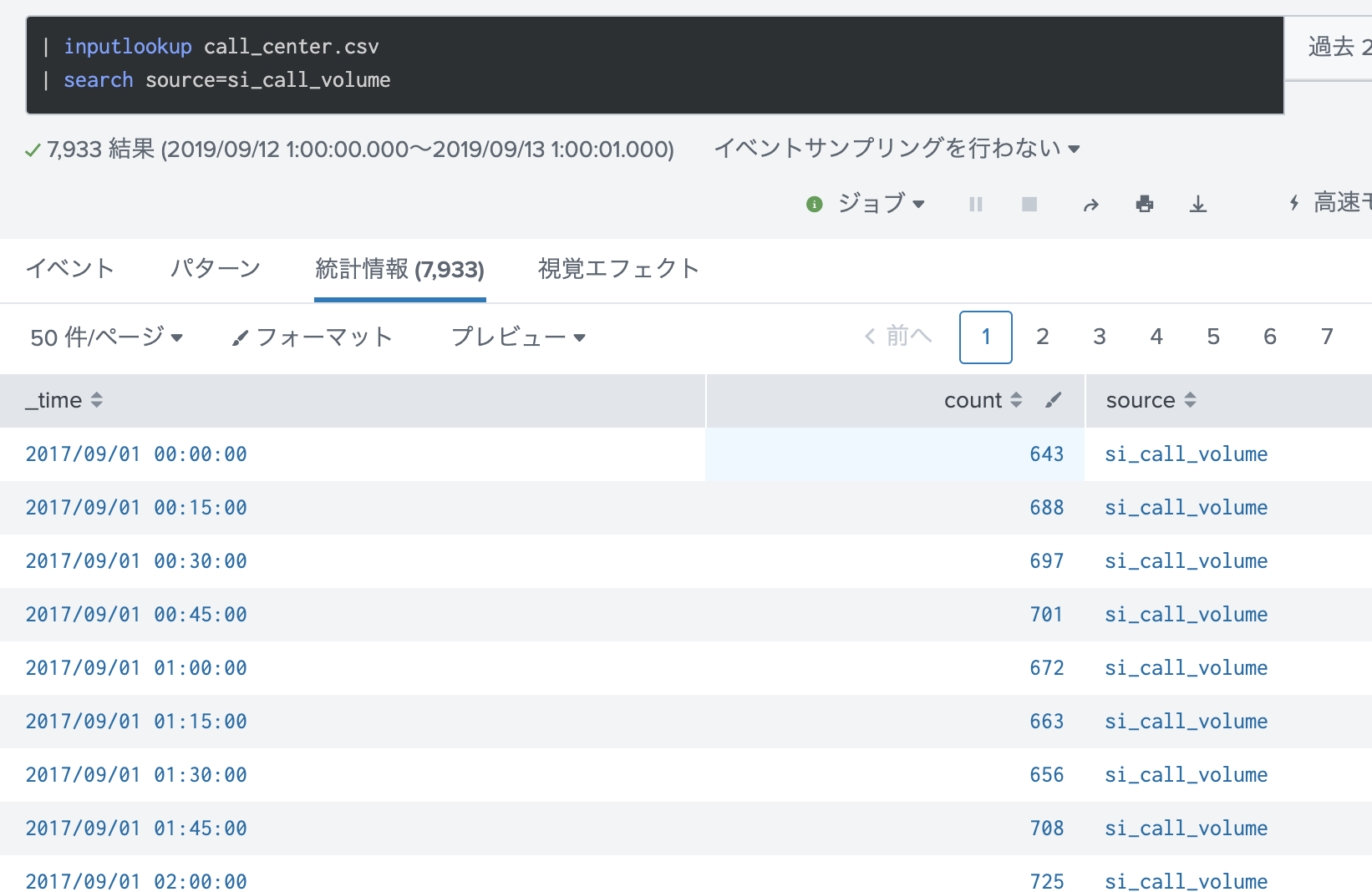
・ MLTKにデフォルトで含まれている call_center.csvを利用します。時間ごとにコール数がカウントされており、五種類のソースが含まれております。今回はシンプルにするため、そのうちの1種類 (source=si_call_volume)を利用します。
15分毎のデータが集計されており、約3ヶ月分(7933件)のデータがあります。
3) どんなモデルを作るか?
今回は時間帯毎のカウント数を学習させて、その時間帯のカウント数が通常と違っていたら異常値と判定したいと思います。ただし曜日によってカウント数が異なるようなので、曜日毎にグループ化してそれぞれのグループ毎に確率密度推定を行い、異常判定したいと思います。
4) モデル作成
前処理として曜日(DayOfWeek) と時間(HourOfDay) ごとに分割します。
最後に、fit コマンドで、DensityFunction アルゴリズムを指定します。今回は曜日+時間の組み合わせのグループ毎に確率密度を計算するため、by句で指定します。(7※24=168グループ出来ます)
| inputlookup call_center.csv
| search source=si_call_volume
| eval _time=strptime(_time, "%Y-%m-%dT%H:%M:%S")
| eval HourOfDay=strftime(_time, "%H")
| eval DayOfWeek=strftime(_time, "%A")
| stats max(count) as Actual by HourOfDay,DayOfWeek,_time
| fit DensityFunction Actual by "HourOfDay,DayOfWeek" into mymodel
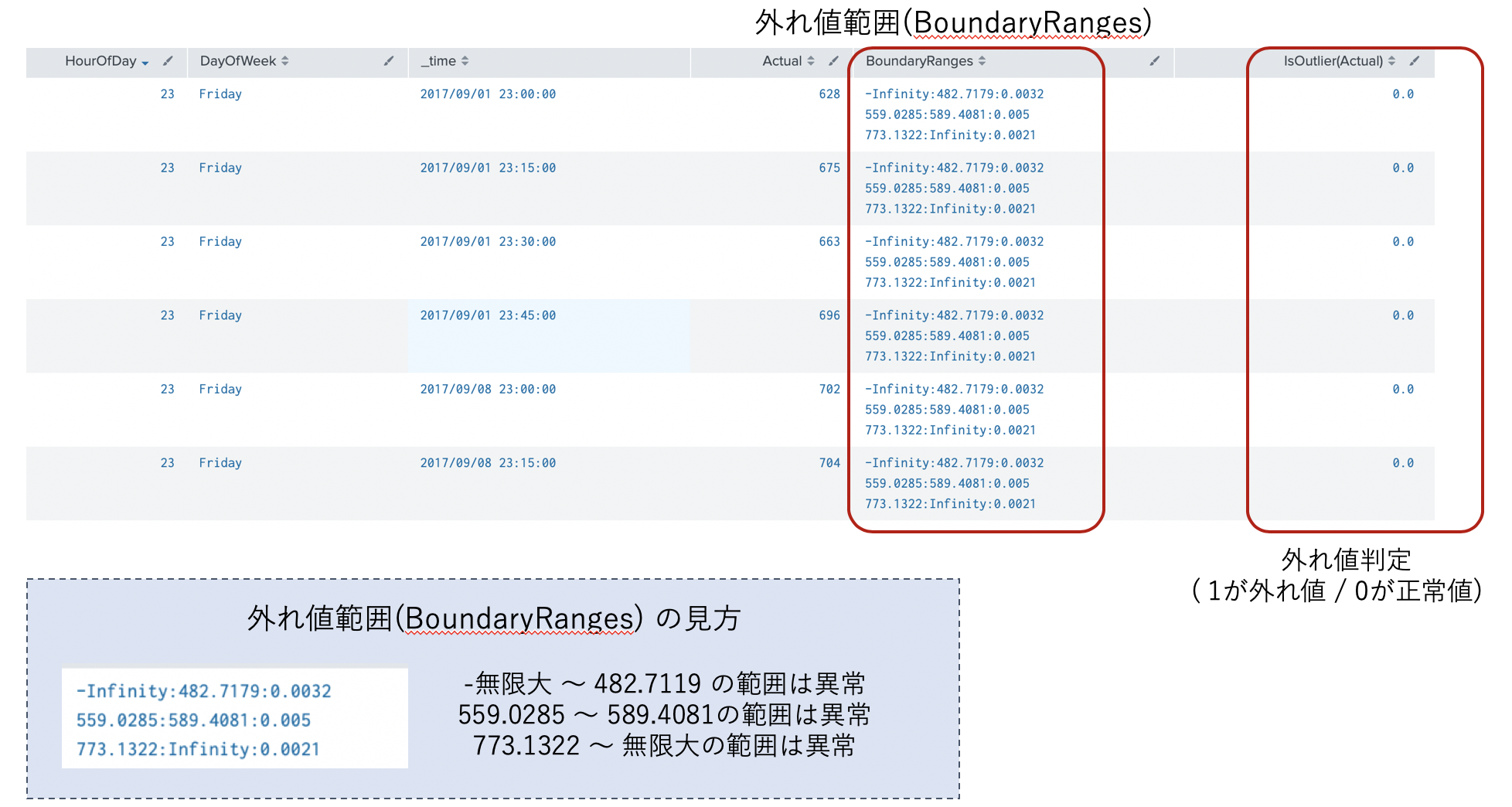
この時点で、現在のデータでの外れ値(異常値)が確認できます。(IsOutlier フィールド)
5) 本番データへ適用
今回は、11/3 のデータを抽出して適用してみます。(外れ値が見つかったため)
基本的に最後の apply が先ほどと変わっただけです。
| inputlookup call_center.csv
| search source=si_call_volume
| eval _time=strptime(_time, "%Y-%m-%dT%H:%M:%S")
| eval day=strftime(_time,"%d")
| eval month=strftime(_time,"%m")
| eval HourOfDay=strftime(_time, "%H")
| eval DayOfWeek=strftime(_time, "%A")
| search month=11 day=3
| stats max(count) as Actual by HourOfDay,DayOfWeek,_time
| apply mymodel
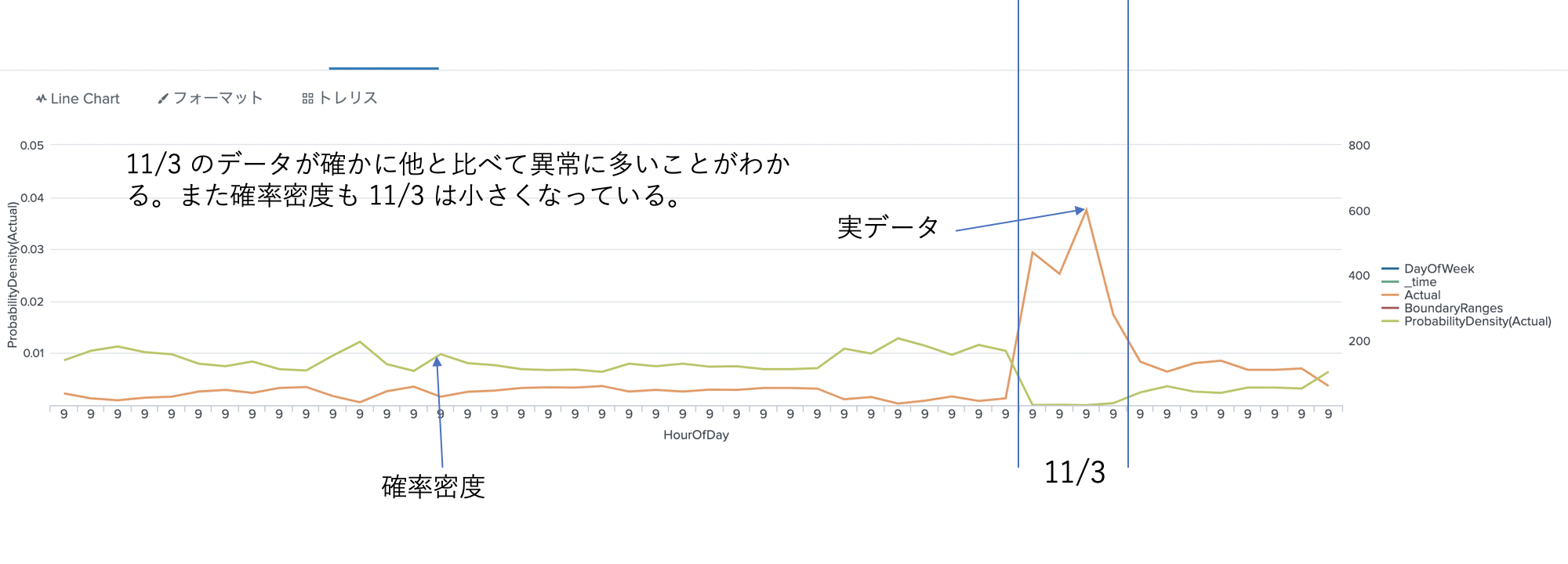
4箇所。異常値が見つかりました。この図だけみるとなぜ異常なのかわからないですが、その時間帯のデータにしてはおかしいのです。ただし本当に問題ないのであれば、閾値などを設定しなおす必要はありそうです。
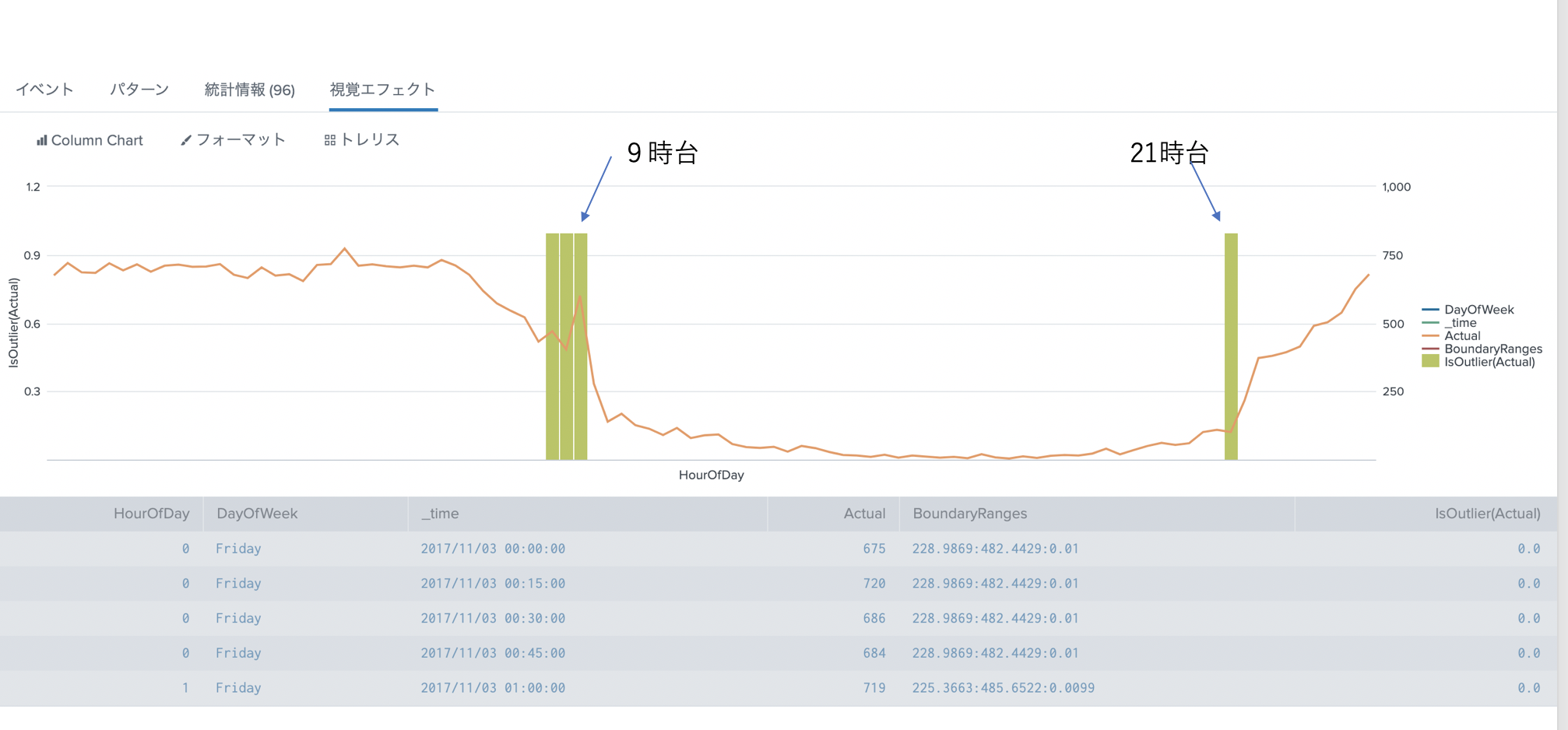
異常値のある箇所が、Friday の 9時台だっため、こちらグループのデータを確認してみます。
| inputlookup call_center.csv
| search source=si_call_volume
| eval _time=strptime(_time, "%Y-%m-%dT%H:%M:%S")
| eval day=strftime(_time,"%d"), month=strftime(_time,"%m")
| eval HourOfDay=strftime(_time, "%H")
| eval DayOfWeek=strftime(_time, "%A")
| search HourOfDay=9 DayOfWeek=Friday
| stats max(count) as Actual by HourOfDay,DayOfWeek,_time
| apply mymodel show_density=t
| fields - "IsOutlier(Actual)"
6) モデルの確認
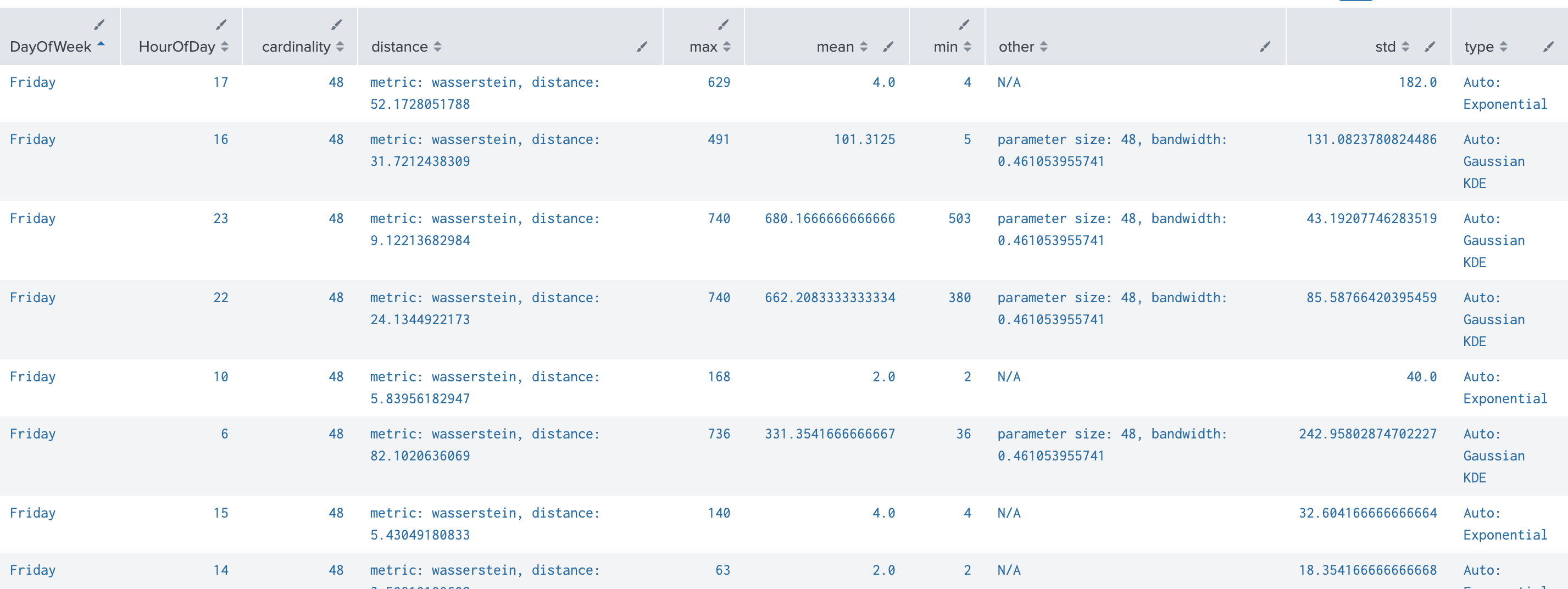
今回作成したモデルについて、どんな確率分布を適用したか?などを確認したい場合は、summary コマンドで確認できます。(一番右の type フィールド確認)
| summary mymodel
7) 実装
実装は、アラート設定として applyコマンドをスケジュール実行し、IsOutlier フィールドが1の値が見つかったら、アクション通知(メールなど)が可能です。リアルタイム設定も可能と思いますが、サーバー負荷にはご注意を。
まとめ
今回は曜日毎の実行としましたが、例えば平日と休日などのフィールドを lookupと組み合わせて作成し、それによるグループ毎の学習も可能になります。従来の統計ベースの異常値判断よりはカーネル関数が利用できたり、グループ毎の検知が出来たりとかなり柔軟に対応できますのでおすすめです。
その他
DensityFunction パラメータについて
・分布図の選択は、 dist パラメータで指定(default:auto). -- 選択される分布図は、正規分布、指数分布、ガウスカーネル分布
・show_density=true オプションで、Probability_Density による強度を確認できる
・sample=true とすると、確率密度に従ったサンプル値が表示されるため、実際のデータとの比較ができる。
・外れ値のしきい値として threadhold パラメータがあり、 0.000000001 から 1 (100%) をセットできる。これはどのくらいを外れ値として見なすかという値なので、大きいほど多くの外れ値が検出されるので注意( default: 0.01)
DensityFunctionのパラメータなどのオプション詳細は、こちらのマニュアルを参照ください。
参考図書
DensityFunction ドキュメント
https://docs.splunk.com/Documentation/MLApp/4.4.0/User/Algorithms#DensityFunction
Blog
https://www.splunk.com/blog/2019/03/20/what-s-new-in-the-splunk-machine-learning-toolkit-4-2.html
カーネル密度推定
https://vaaaaaanquish.hatenablog.com/entry/2017/10/29/181949
ノンパラメトリック密度推定
http://ibis.t.u-tokyo.ac.jp/suzuki/lecture/2015/dataanalysis/L9.pdf