はじめに
前回の記事でDatabricks間でDeltasharingを使ったデータ共有を行いましたが、今回はDatabricks以外の環境からアクセスしてみたいと思います。
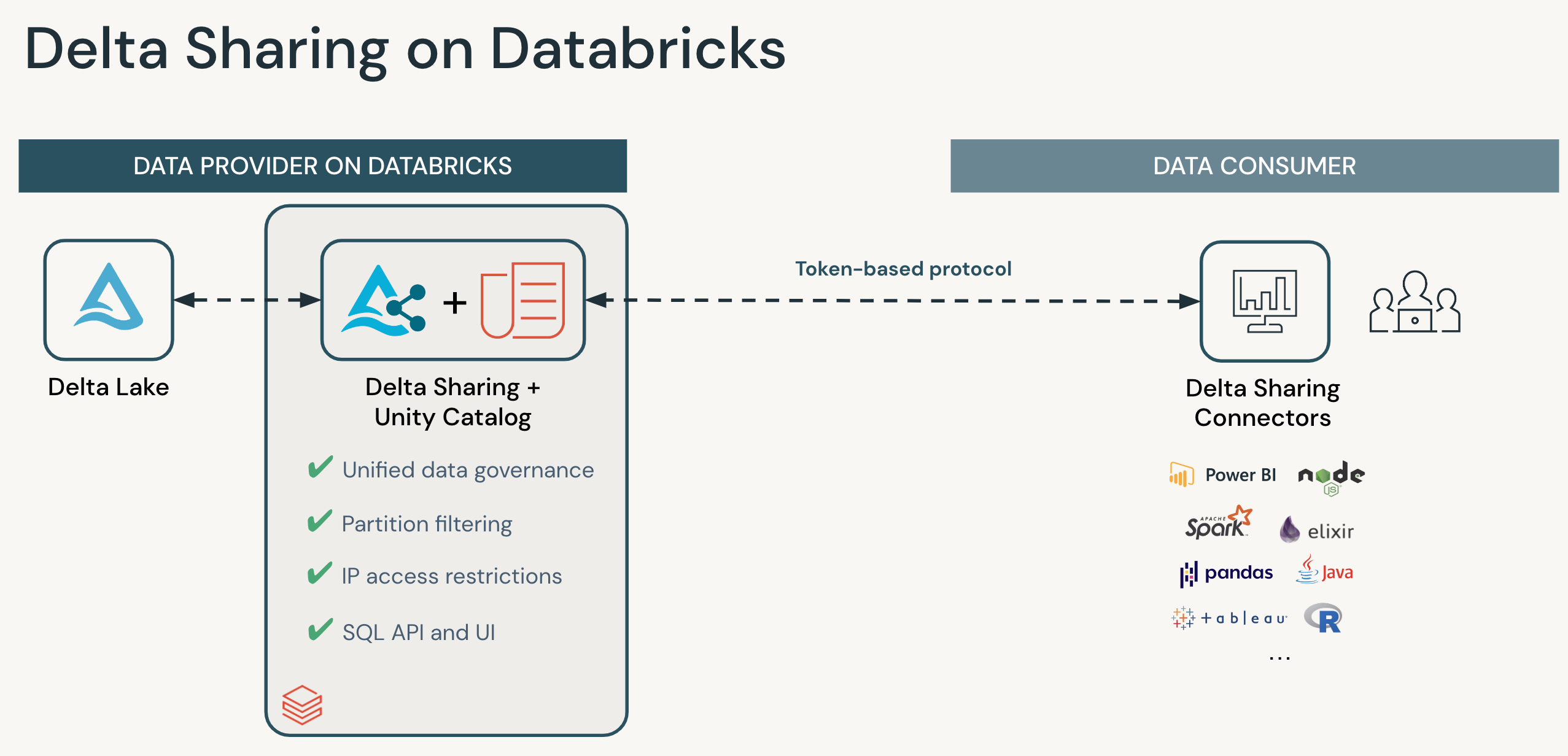
DeltaSharingはオープソースプロジェクトですので、以下のようにDatabricks以外のツールからもアクセスすることが可能です。ただし現時点で対応しているツールは少ないのでご注意ください。対応状況についてはこちらをご覧ください。
準備
以下のセットアップが完了している必要があります。
- Unity Catalogが利用できる
- DeltaSharingが有効になっている
- 共有するメタストアに対して管理権限を持っているもしくはメタストアに対して特権(CREATE_SHARE, CREATE_RECIPIENT, CREATE_PROVIDER)を持っている
詳細なDeltaSharing要件についてはマニュアルもご覧ください。
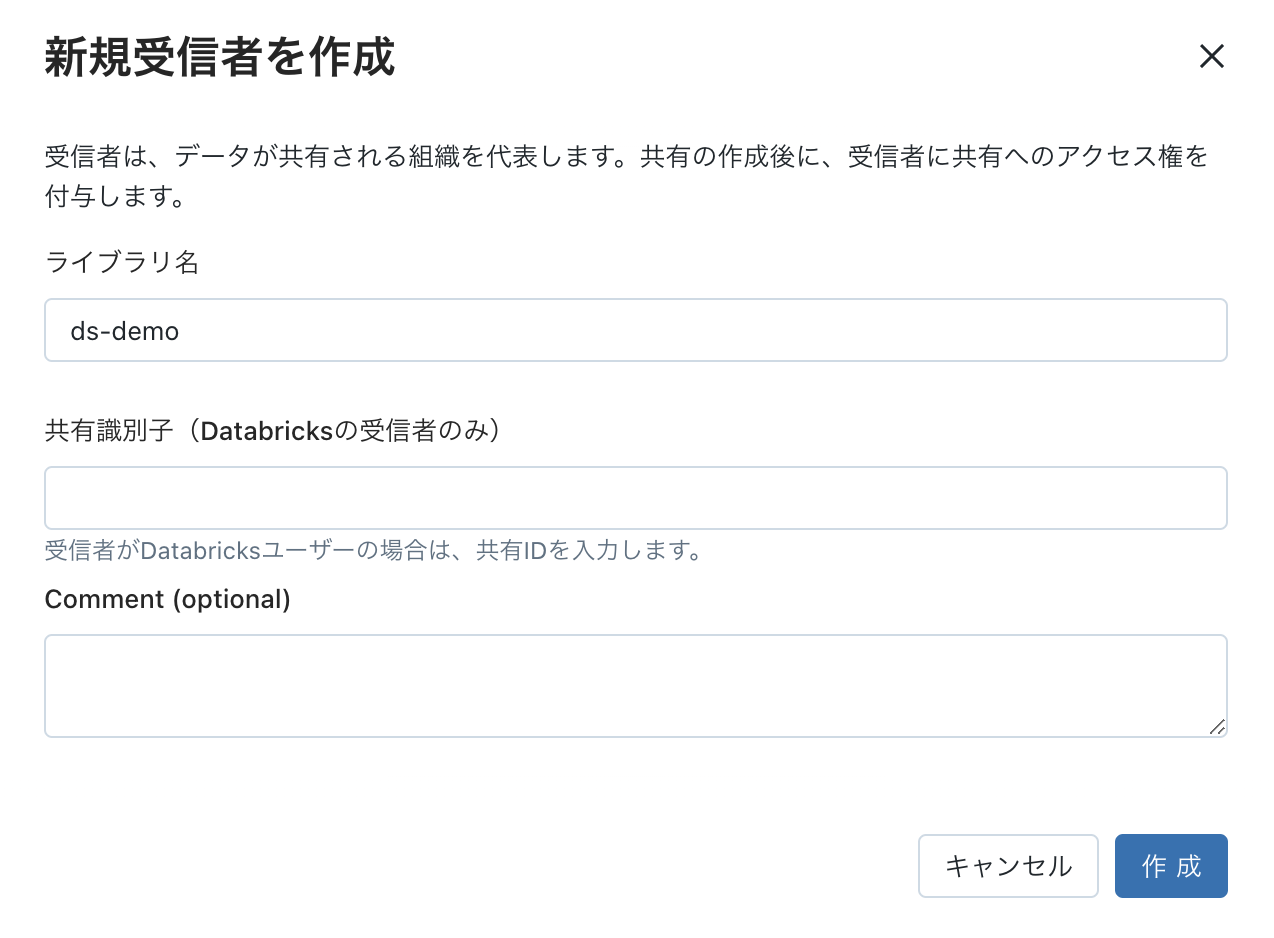
1. DeltaSharing受信者の作成
データブリックスのデータエクスプローラーから、DeltaSharingメニューを開いて「自分が共有」ー「新たな受信者」をクリック。Databricks以外のツールからのアクセスのため、共有識別子の入力は不要です。
2. アクティベーションリンク発行 & クレデンシャル情報
アクティベーションリンクが発行されるのでクライアント側になんらかの方法で送信する。リンクは後から受信者の詳細ページで確認もできます。
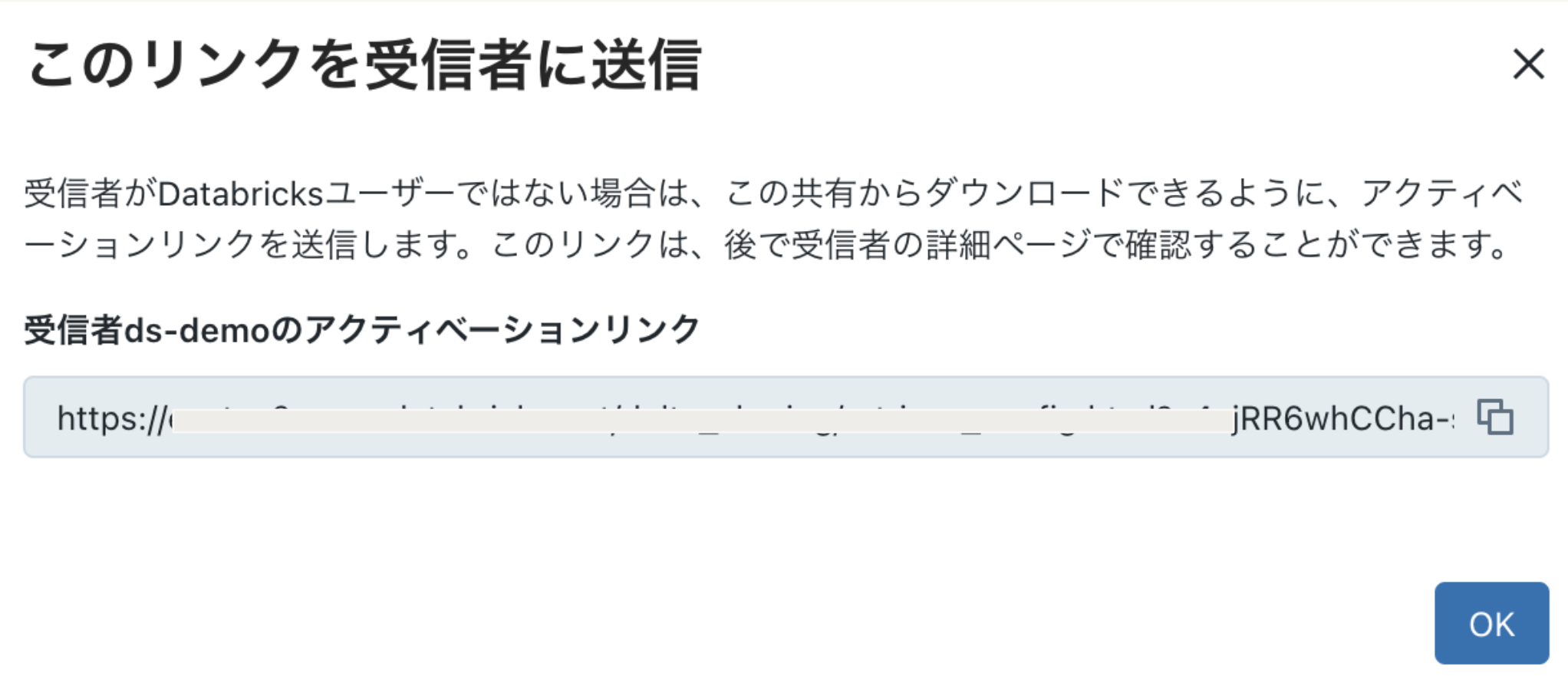
リンク先を参照すると以下のようにクレデンシャル情報をダウンロード出来るようになっております。(ダウンロードは一回のみ可能ですので要注意)

ちなみに発行したトークンの有効期限を変更したり、IPアクセス制御をかけたりすることも可能です。
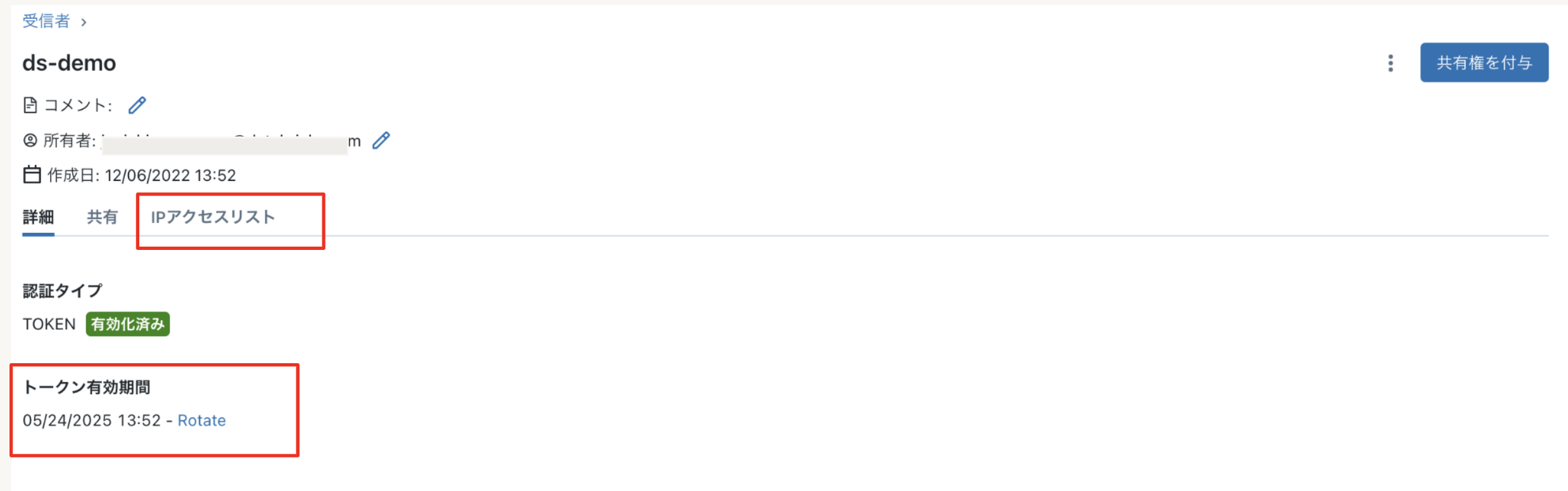
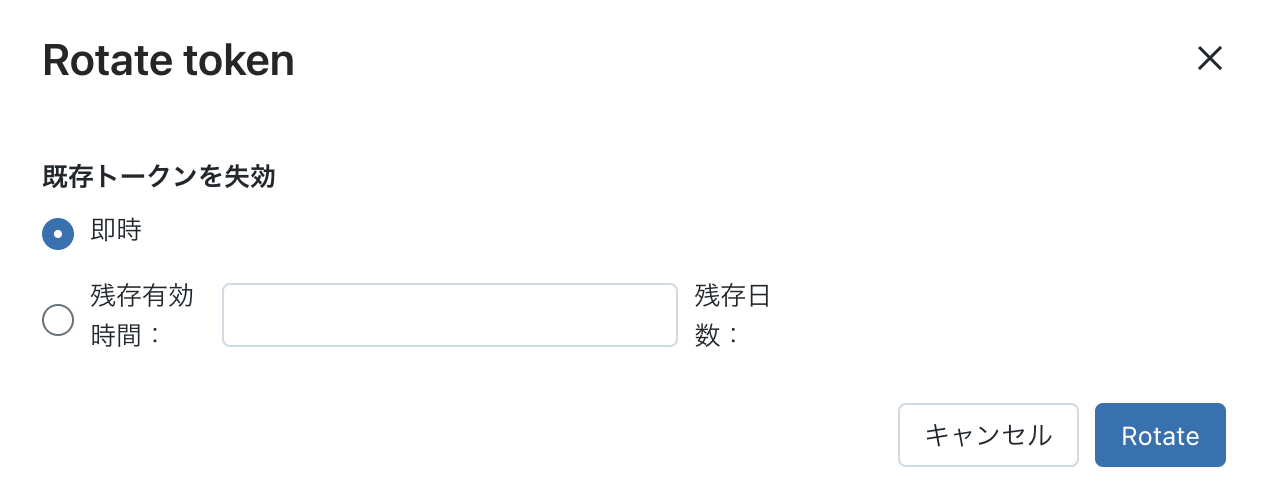
3. 共有オブジェクトの作成
2-1. 共有するテーブルを指定し共有オブジェクトを作成します。
同じくデータエクスプローラ(共有する側)のDelta Sharingメニューから、「自分が共有」を選択し、右上にある「データを共有」をクリックします。

2-2. オブジェクトが作成できたら、次に共有するテーブルを追加してきます。
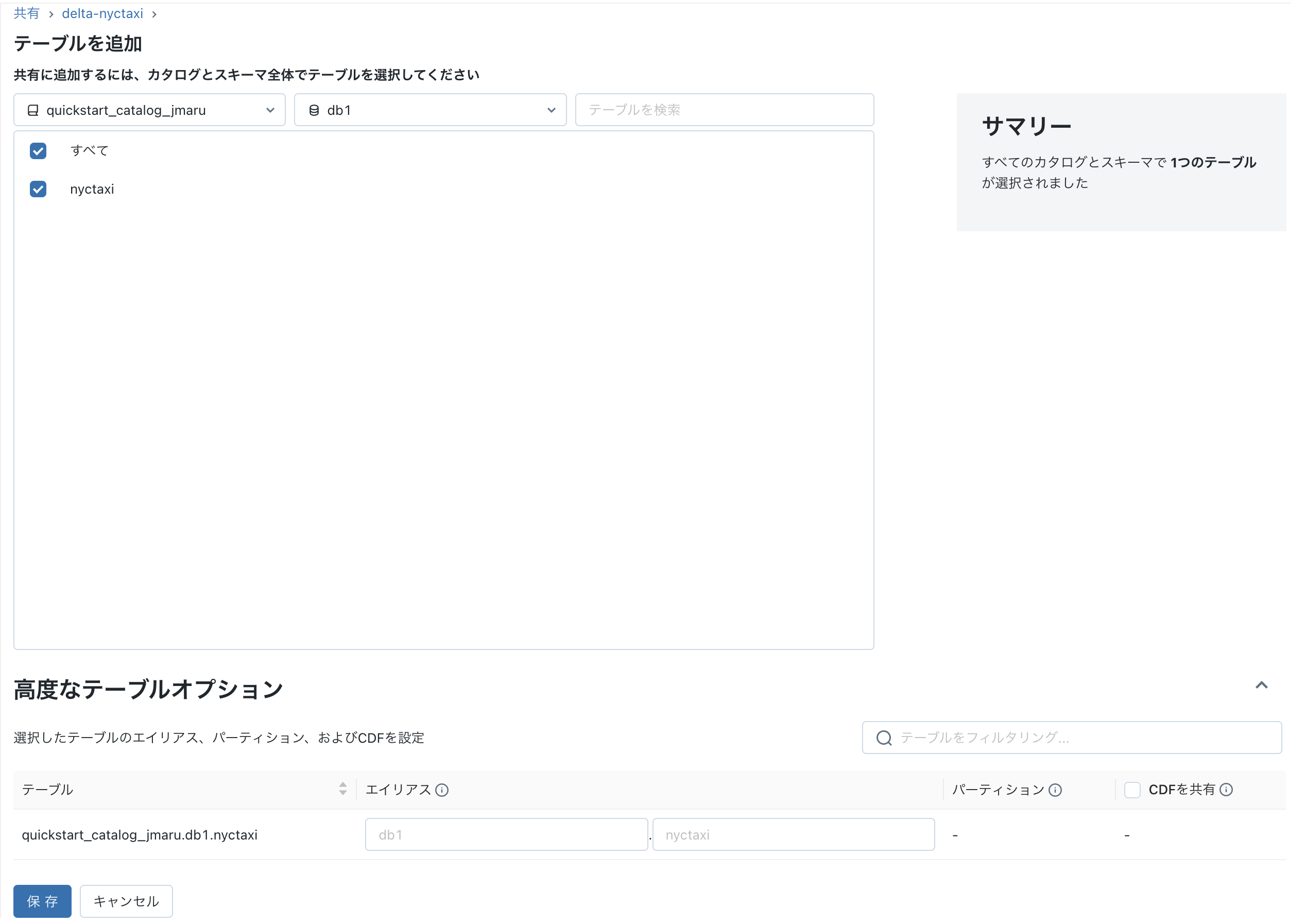
高度なテーブルオプションでは、エイリアス名をつけたり、共有するパーティションを指定したり、CDFとして共有するなど選択できます。
最後に保存する。
2-3. 作成した共有オブジェクトに受信者を追加
共有オブジェクト画面にて、右上に「受信者を追加」ボタンをクリックし、1で作成した受信者を追加します。
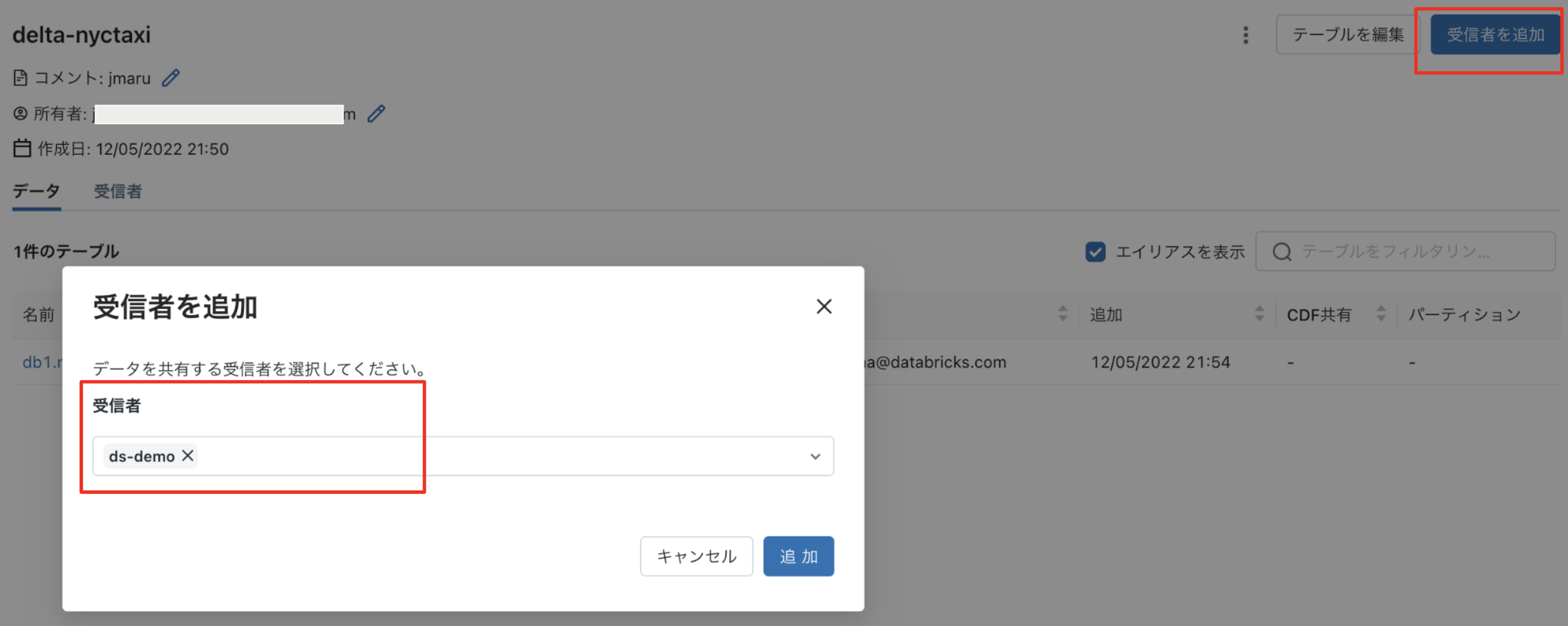
4. ローカルPCからアクセス
それでは準備は整いましたので、Delta Sharingを使ってデータブリックスのデータにアクセスしてみます。
今回はPandasとしてデータを取り込んでみます。
4-1. Credential Fileの保存
1でActivation LinkからダウンロードしたCredentialファイル(config.share)をローカルPCに保存します。
4-1. Pandasとしてデータを読み込む
まずはdelta-sharingモジュールをinstallします。
%pip install delta-sharing
次に以下のようにpandasとして読み込みます。
- profile_path : 保存したCredentialファイルのパス
- share_name : 共有オブジェクト名(ステップ3で作成したもの)
- schema_name : テーブルが格納されているSchema(database)名
- table_name : 参照したいテーブル名
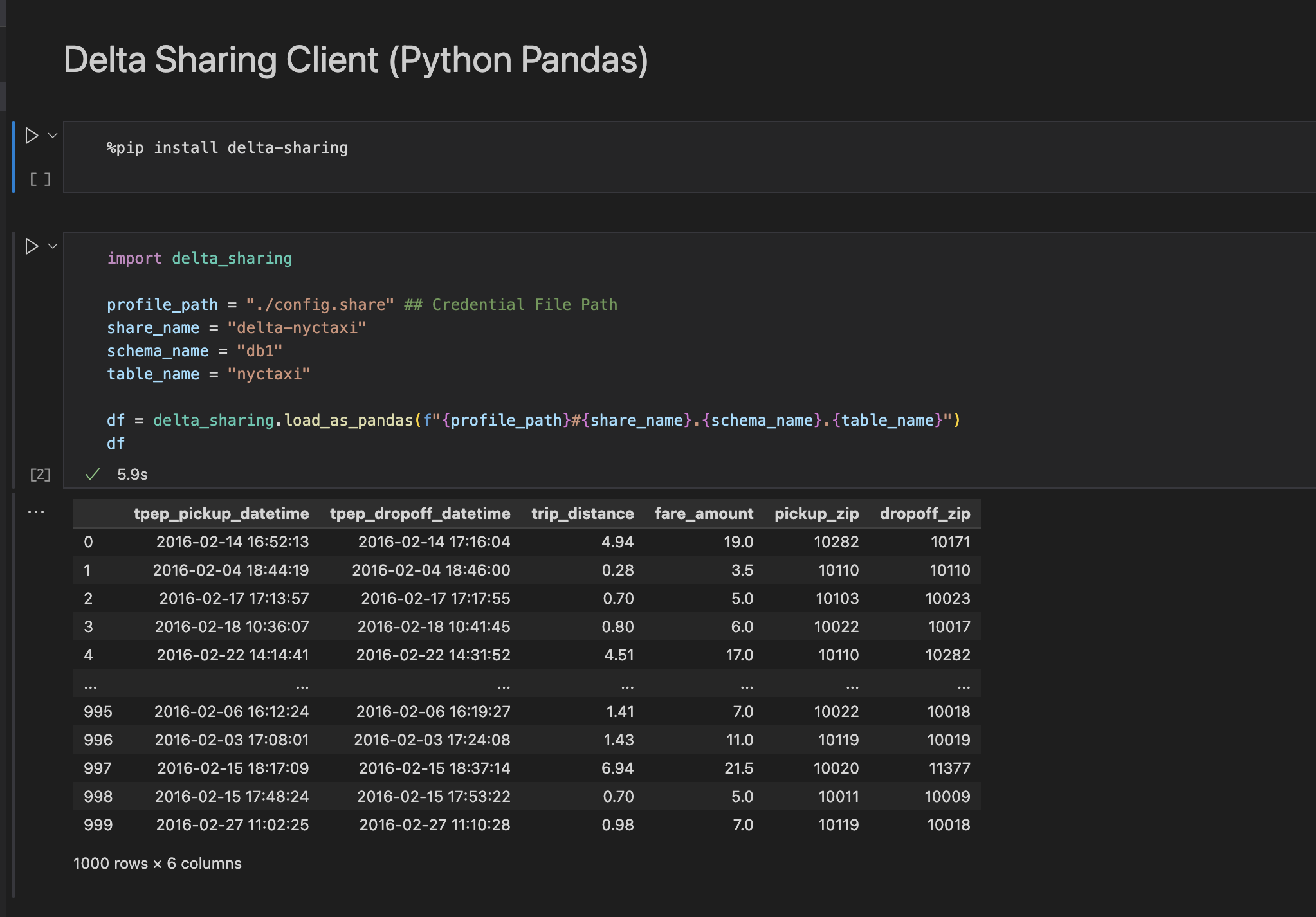
import delta_sharing
profile_path = "./config.share" ## Credential File Path
share_name = "delta-nyctaxi"
schema_name = "db1"
table_name = "nyctaxi"
df = delta_sharing.load_as_pandas(f"{profile_path}#{share_name}.{schema_name}.{table_name}")
df
実際の画面はこんな感じ
その他クライアントツールについて
Pandas以外にも、Sparkや PowerBIからもアクセスできます。詳細はこちらをご覧ください。
https://docs.databricks.com/data-sharing/read-data-open.html#apache-spark-read-shared-data
嬉しい点
- シンプル: ODBC/JDBCドライバーなど不要でクライアント側からは簡単に利用できる
- 柔軟性: 従来のようなPersonalトークン発行だと利用範囲が大きく、余計なテーブルなどにアクセス出来てしまったりしていたが、細かい範囲指定や柔軟なトークン管理が出来るため柔軟性が大きい
- 費用面:Provider(データ供給者)側はクラスターやSQL Warehouseを起動せずにアクセスできるため、コストを低く抑える事ができます。(Network通信費とストレージIO費程度)。