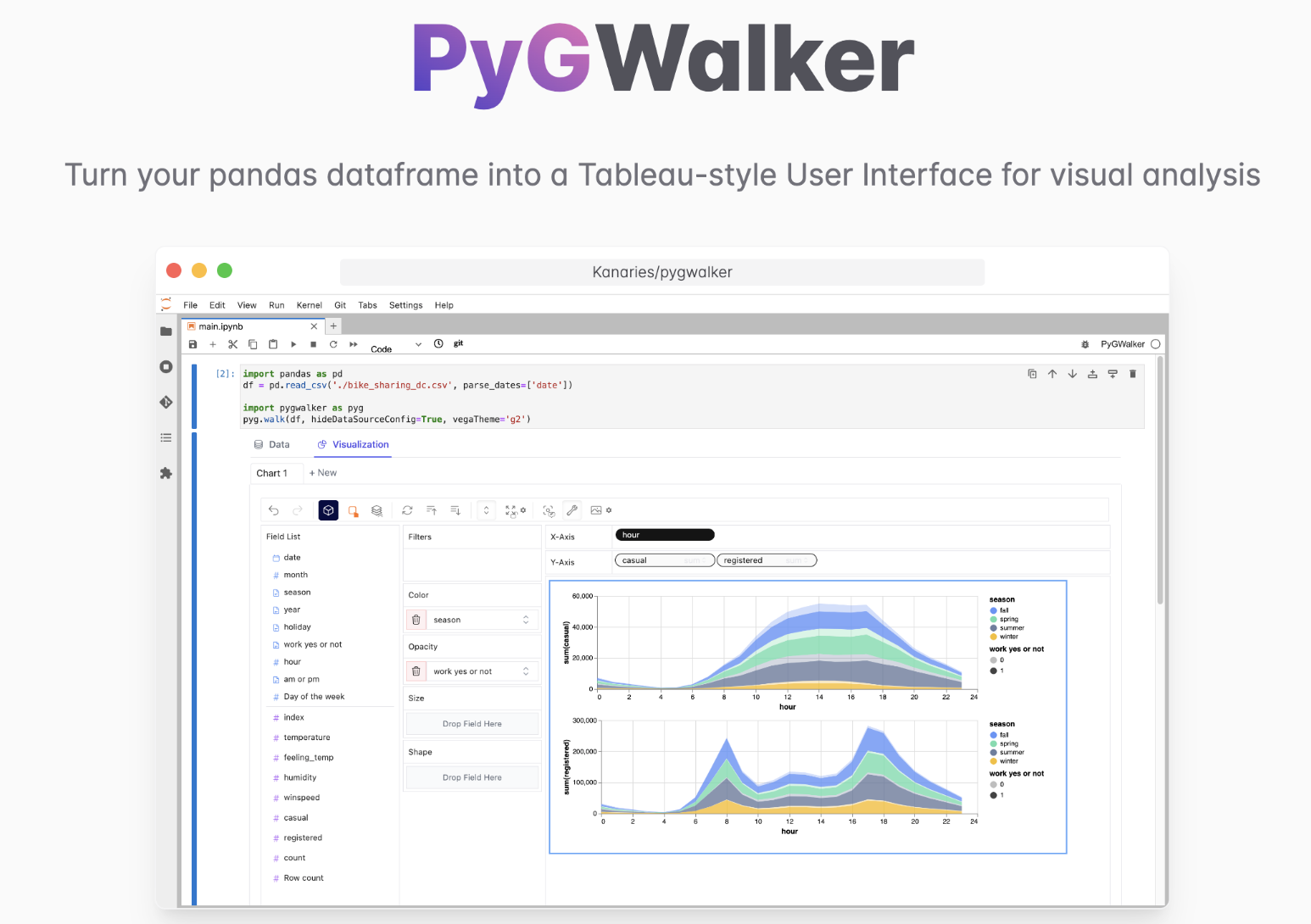
Tableau ライクなインターフェースでノートブック上で可視化が出来るツールがある。と聞いたので早速 pygwalkerを試してみました。
pygwalkerとは?
PyGWalkerはJupyter Notebookのデータ解析とデータ可視化のワークフローを簡素化し、pandasデータフレームをTableauスタイルのユーザーインターフェースに変えて、視覚的に探索することができます。とのことです。
残念ながら Sparkデータフレームには対応していない模様です。Databricksにある bamboolibに近い製品かなと思いました。
セットアップ
非常に簡単です。
!pip install pygwalker
サンプルデータの取り込み
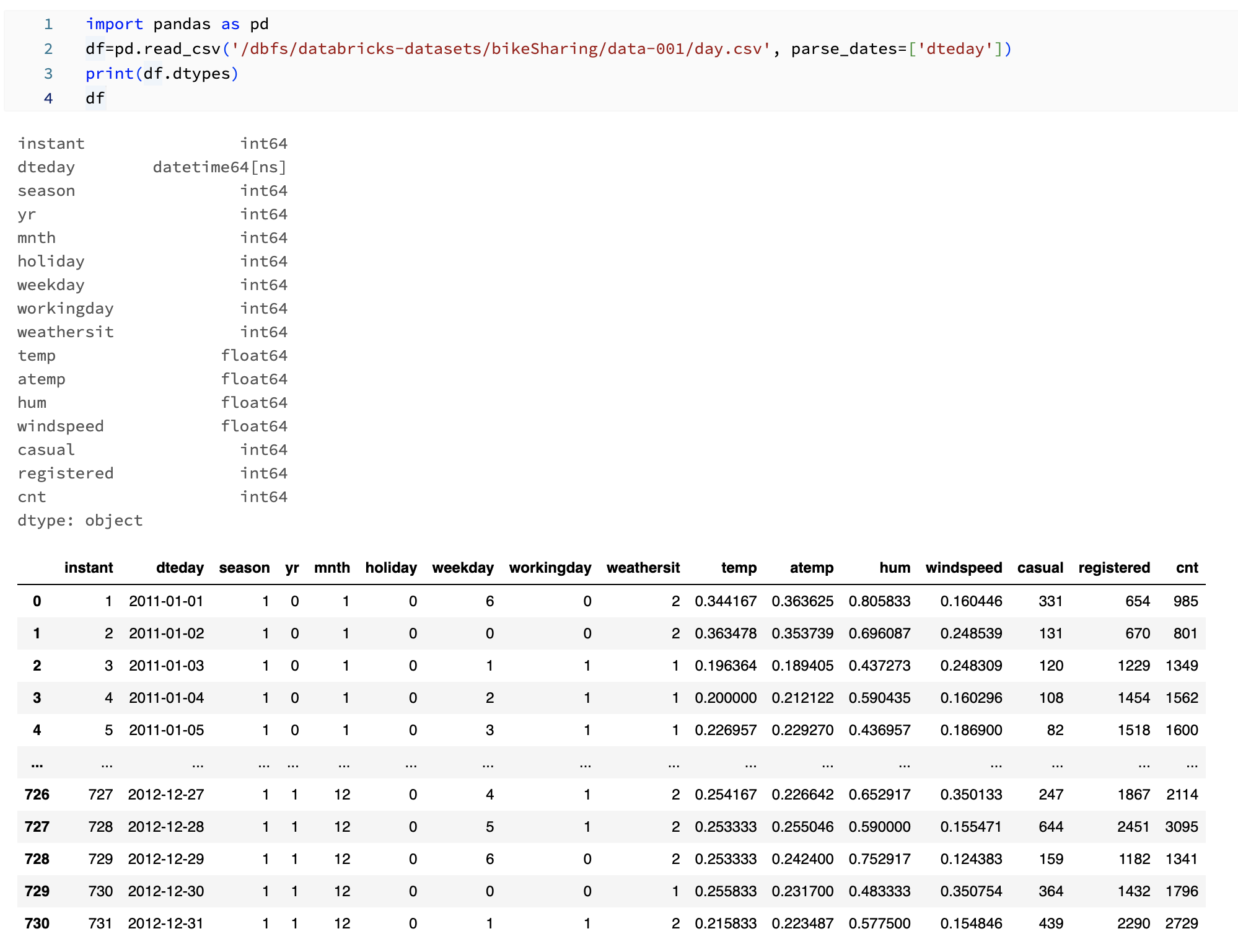
今回は、Databricksでデフォルトで用意されているデータをpandasで読み込みます。
import pandas as pd
df=pd.read_csv('/dbfs/databricks-datasets/bikeSharing/data-001/day.csv', parse_dates=['dteday'])
pygwalkerの起動
import pygwalker as pyg
gwalker = pyg.walk(df)

以上です。あとはGUI上で Tableauライクに可視化が出来ます。
サンプル
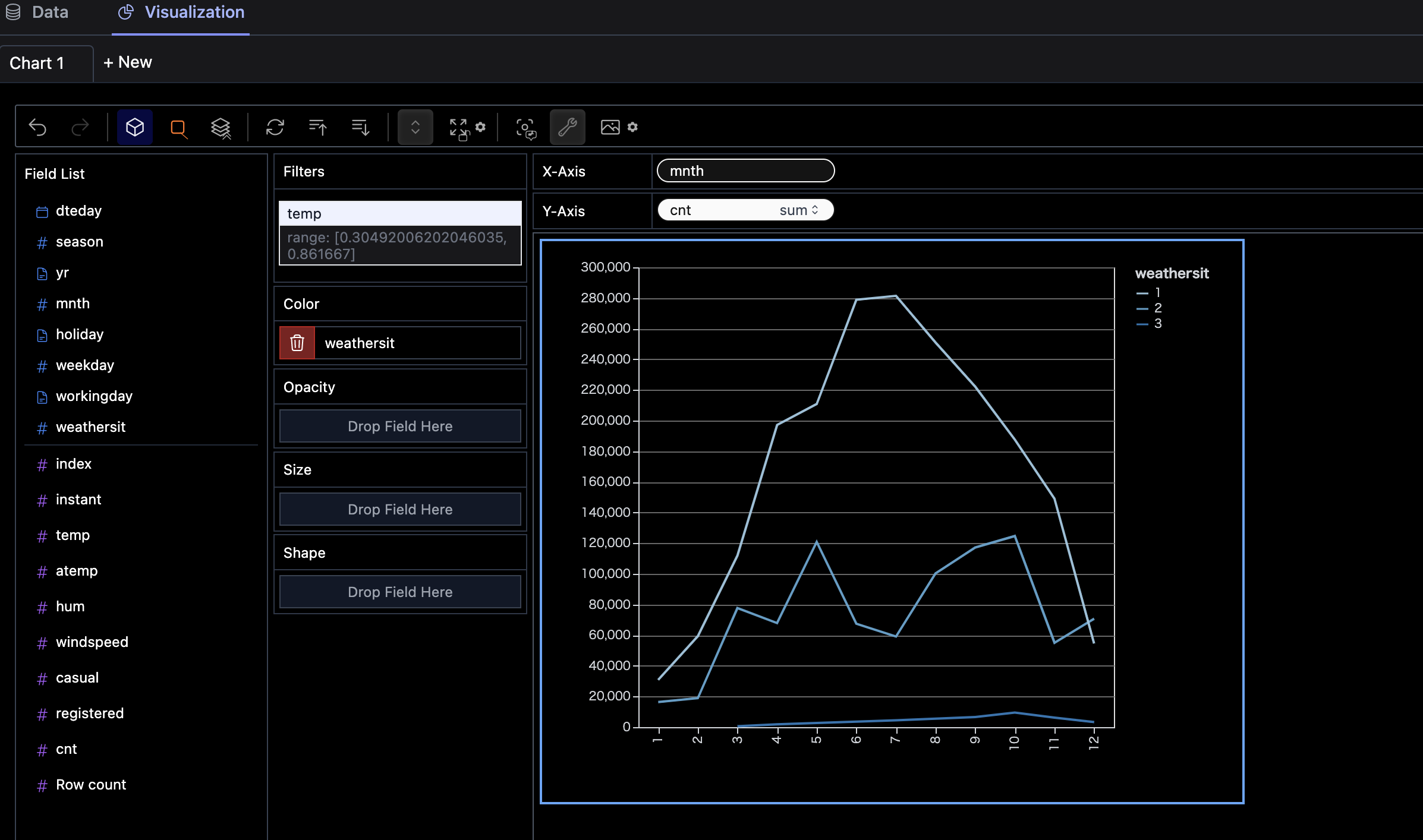
月毎の利用者数を調査 &天候毎にグループ化

グラフのサイズの変更
ギアマークをクリックするとサイズ変更出来ます。もしくはグラフの青色の枠を掴んでサイズ変更できます。

グラフタイプの変更
そこまで多くないですが変更可能

Aggregation機能
Aggregationボタンを押すと、sum/min/max/meanなどでAggregationして表示できます。

filter条件の入力
filterフィールドに tempを入れてみます。クリックすると条件を指定出来ます。

Exportはpngとsvg形式のみ

メリット&デメリット
メリット
- Tableauライクなインターフェースで誰でも直感的に操作できる
- Filter設定でInteractiveな操作が可能
デメリット
- pandasデータフレームしか利用出来ない。ビックデータには不向き
- 利用できるグラフが少ない(拡張とかできるのかな?)
- ノートブック上のため設定を保存出来ない。(リフレッシュすると全て消えてしまう)
- ETL的な操作は出来ない(Joinやデータ加工など)
- csvやexel形式でダウンロード出来ない
- グラフにタイトルや、X/Y軸のラベルや凡例などカスタマイズできない
感想
ちょっと触っただけの感想で恐縮ですが。操作はシンプルなので直感的で非常に使いやすいツールと思いましたが、個人的にはDatabricks標準のDisplay()で十分な気がしましたし、機能面ではBamboolibの方が優っていると思いました。ただ直感的にわかるというのはやっぱ重要ですよね。