はじめに
Google Spread Sheetと連携して、データをDatabricksに取り込んでみたいと思います。
いくつか、過去のライブラリーなど利用しようとしてハマったので、同じ轍は踏まないように書いておきたいと思います。
開発中止ライブラリー
まず最初に目についたのが、Spark APIを使ったライブラリーspark-google-spreadsheetsだったのですが、Spark3の環境にインストールしようとするとエラーになってしまい、互換性もないということから利用しない方が良さそうです。
ということで、SparkAPIを使ったものは諦めて、通常のPythonライブラリーを使いたいと思います。
gspread / gspread-dataframe ライブラリー
検索してみると、gspreadというライブラリーがあるようです。また gspread-dataframeライブラリーを使うと、pandasデータフレームとして取り込む事ができるとの事なのでこちらが良さそうです。
手順1:Google 側の設定を行う
こちらの記事が非常にわかりやすかったので、こちらを参考に以下のGoogle側の設定を行います。
https://virment.com/enable-google-spreadsheet-api/
- Spreadsheet API を有効化する
- Service Accountの作成と Account Keyの発行
- Spreadsheet への permission設定
手順2:Account KeyファイルをDatabricksのDBFS上にアップロードする
上記のサービスアカウント作成時にダウンロードしたAccount Keyファイル(json)を DBFS上にアップロードします。
(注意)
DBFS上におくと他のユーザーもアクセスできてしまうのでその点だけご注意ください。もし他のユーザーとキーファイ
ルを共有したくない場合は、S3などにファイルを配置して、Instance Profileなどを利用して直接アクセスするようにしてください。
今回はそのままDBFSにアップロードします。

#手順3:Databricks Notebookから利用してみよう
これで準備は完了です。それではノートブックから利用してみましょう。
今回利用するGoogle Sheetはこちらです。
ファイル名はtest_data
シート名はtest_sheet
Google SheetのURLに大事なSheetID情報があります。
https://docs.google.com/spreadsheets/d/<ここの部分>/edit#gid=xxxx

ライブラリーインストール
%pip install gspread
%pip install oauth2client
%pip install gspread-dataframe
Google認証情報とワークシート情報の設定&シートの読み込み
以下の3つの入力情報を入力の上実行すると、エラーがなければスプレッドシートをオブジェクトとして取得する事ができます。
import gspread
import json
from oauth2client.service_account import ServiceAccountCredentials
from gspread_dataframe import get_as_dataframe, set_with_dataframe
#2つのAPIを記述しないとリフレッシュトークンを3600秒毎に発行し続けなければならない
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
#######################################
####. 入力情報 (必要事項を入力ください)#######
########################################
credential_path = '<file path of .json>' # アップロードした認証ファイルのパスを指定します。 ex) /dbfs/FileStore/xxx.json
sheet_key = '<spread sheet key>' # 読み込むスプレッドシートのキーを入力します。 ex) '13aaiSIDJkhhynFU-0HyTVb5NUuXv-C31TsXLEftr3bA'
sheet_name = '<sheet name>' # ex) 'test_sheet'
#認証情報を設定し、OAuth2の資格情報を使用してGoogle APIにログインします。
credentials = ServiceAccountCredentials.from_json_keyfile_name(credential_path, scope)
gc = gspread.authorize(credentials)
#スプレッドシートを開く
workbook = gc.open_by_key(sheet_key)
#ワークシート名からワークシートを取得
worksheet = workbook.worksheet(sheet_name)
pandas DataFrameとして読み込み
get_as_dataframe関数で読み込めます。オプションを指定する事で読み込む対象や、ヘッダーなどを付与できます。
オプションはこちらのread_csvオプションが利用できるようです。
df_sps = get_as_dataframe(worksheet, usecols=[2,3,4,5], nrows=6, skiprows=0, header=3, index_col=0)
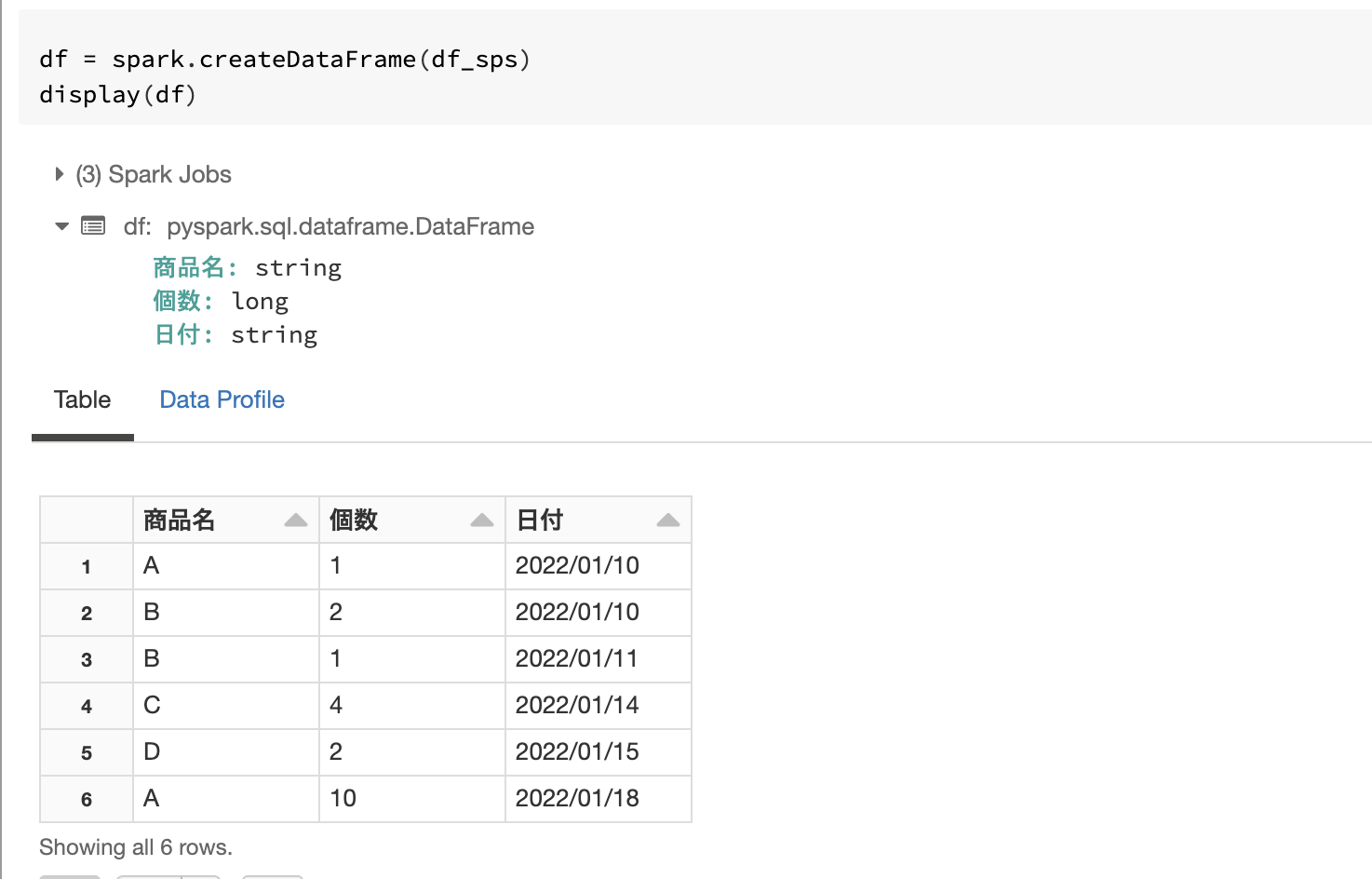
df_sps

その他
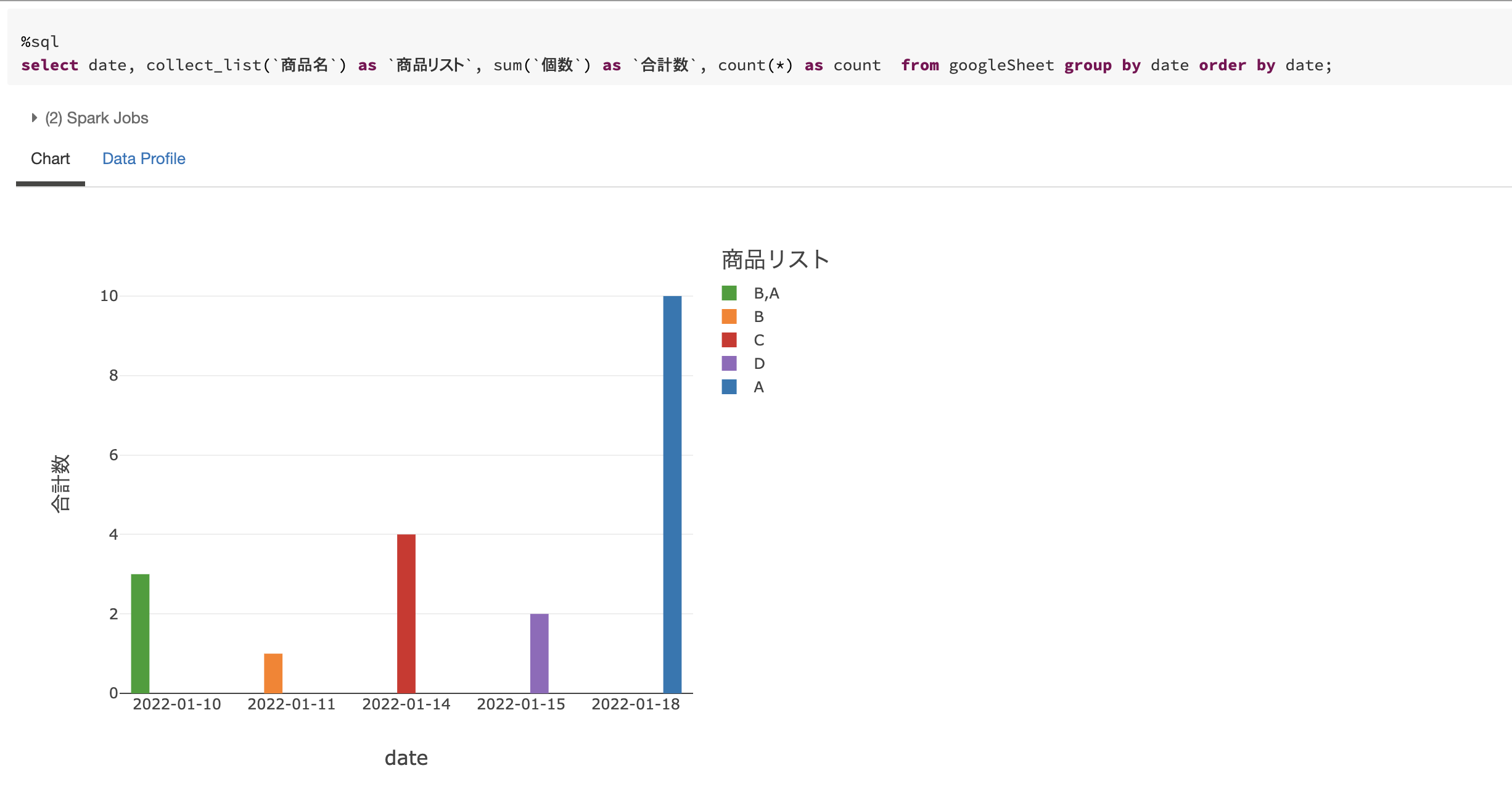
せっかくなので、もう少し触ってみます。
Spark DataFrameとして読み込み
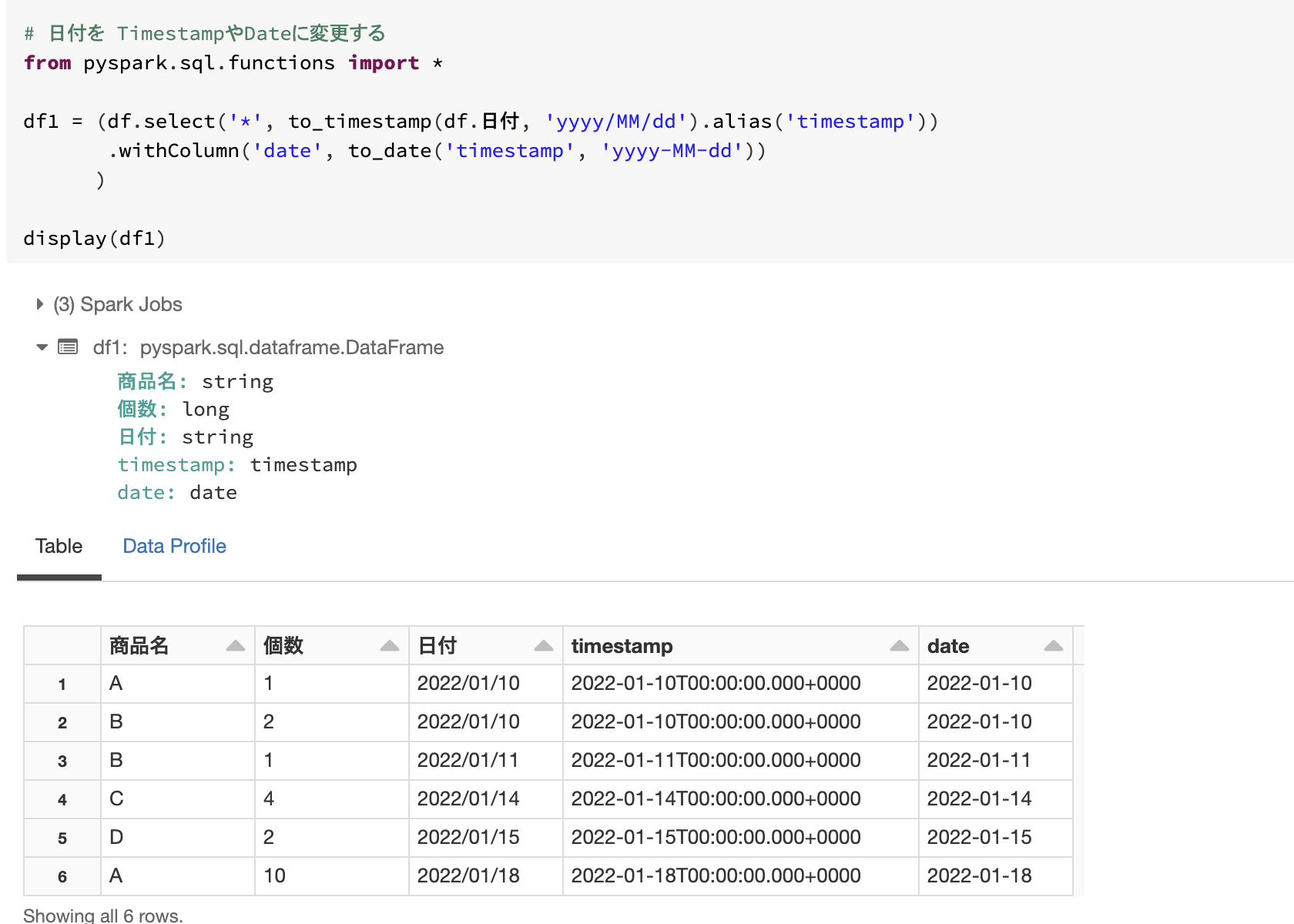
Schemaを変更(Timestamp)
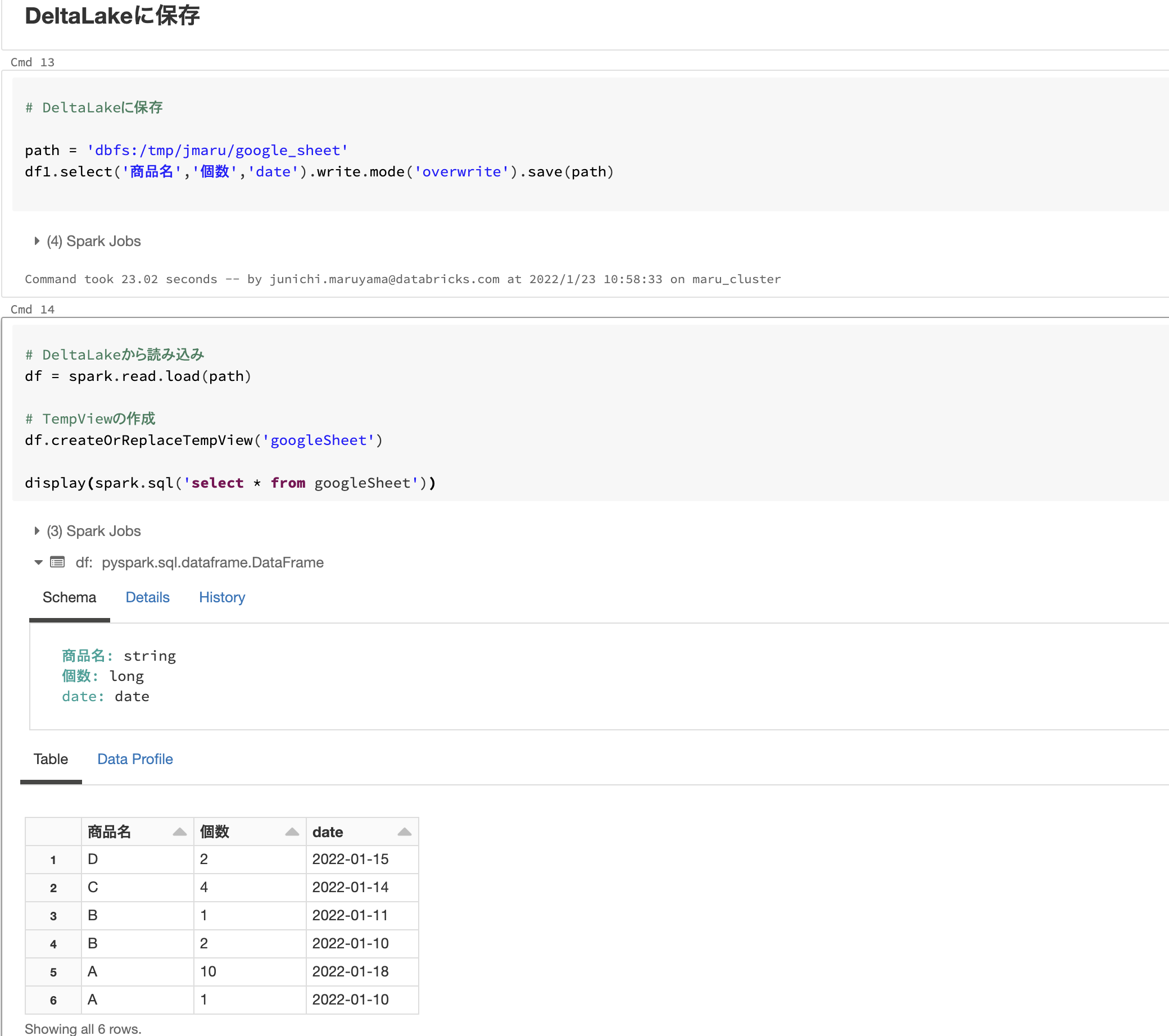
DeltaLakeへの保存 & TempView作成
参考サイト
サンプルノートブック
今回利用したサンプルノートブックはこちらから利用できます。